MLOps Guide: Tools, Best Practices & Key Concepts
|
|
The trend of building applications and technologies based on the principles paved by DevOps is on the rise. The practice of DevOps is meant to give a uniform and cohesive approach to the process of developing applications. The same inspiration is being used for other types of applications, like those that heavily rely on AI.
Machine Learning (ML) is a popular technology under the AI umbrella. Its applications are many – recommendation systems, natural language processing (NLP), computer vision, and many more. In fact, it is projected that:
“The global MLOps market was valued at USD 1.7 billion in 2024 and is projected to grow at a CAGR of 37.4% between 2025 and 2034.” (source)
While one might wonder why the principles of DevOps aren’t enough for AI-based applications like those using ML, the answer is simple. AI comes with its own complexities and depends on much more than just code; it also focuses on data and the model used. Thus, MLOps helps manage these nuances associated with ML.
Learn more about MLOps in this article.
| Key Takeaways: |
|---|
|
What is MLOps?
MLOps is a set of practices and principles one can use to ensure ML-based applications are developed, tested, and deployed smoothly. It uses the best lessons of DevOps, considering the unique factors of ML, to give a cookbook for ML applications. With more companies racing to adopt AI and ML to gain a competitive edge, it has become imperative to have dedicated practices for managing such applications. This is because the traditional, manual process of deploying models is slow, error-prone, and impossible to scale. MLOps provides the structure needed to make this happen seamlessly.
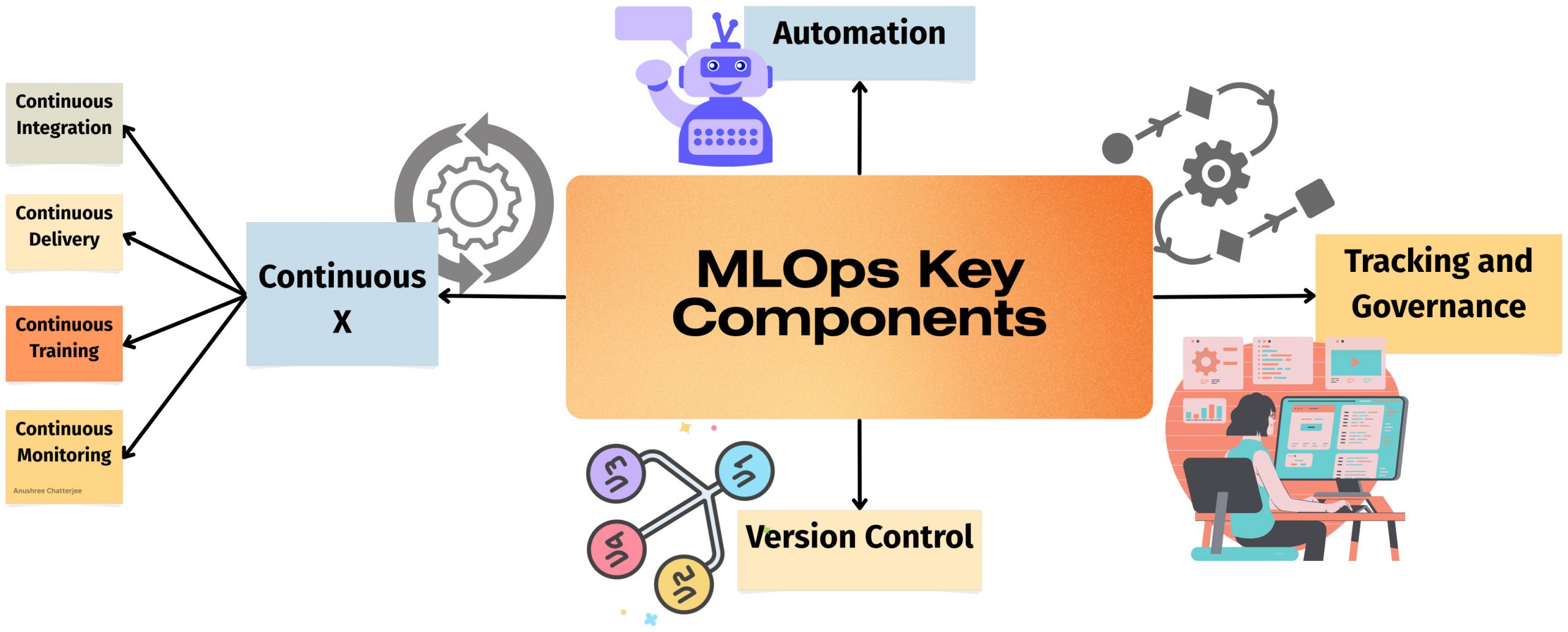
Core Principles of MLOps
Let’s look at some key principles that are at the heart of MLOps.
Automation
You can consider automation to be a prominent factor in making or breaking your MLOps endeavors. This is because the level of automation determines how mature your MLOps framework is. Automation here means all kinds of processes involved in dealing with the ML code, data, model, testing, deployment, and monitoring. You might see triggers for automated model training and deployment, such as messaging, monitoring, or calendar events, data changes, model training code changes, and application code changes.
Continuous X
DevOps introduced the concept of automating various aspects of the application lifecycle so that they can happen continuously. In the case of MLOps, the following activities can be done continuously:
Continuous Integration
You’re probably familiar with Continuous Integration (CI) from software development – it’s about automatically building and testing new code every time a developer makes a change. For MLOps, this concept is bigger. It isn’t just about testing your code; it’s about testing the entire pipeline. This includes validating the new code, checking that your data preparation steps are working correctly, and even running initial tests on the model itself to make sure it’s not totally off base before you invest time in training.
Continuous Delivery
It’s the automated process of packaging your trained model and its supporting code so it’s ready to be deployed. It takes it one step further, automatically pushing that new model to a production environment. This ensures that the moment you have a better, more accurate model, it can be seamlessly swapped in for the old one without any manual fuss.
Continuous Training
Unlike a traditional application, an ML model doesn’t just work forever once it’s deployed. The real world changes – customer behavior shifts, new trends emerge, and the data your model sees in production starts to look different from the data it was originally trained on. This is called data drift, and it can cause a model’s performance to slowly degrade. Continuous training is the automated process of re-training your model to keep it sharp and relevant, ensuring it continues to make accurate predictions over time.
Continuous Monitoring
Continuous Monitoring means tracking the health of the infrastructure (Is the server running okay?) and, more importantly, the performance of the model itself. Are its predictions still accurate? Is it getting worse over time? We also monitor the incoming data to detect any signs of drift. This monitoring is what provides the crucial feedback loop that often triggers the Continuous Training pipeline.
Version Control
Version control is aimed at maintaining copies of every iteration of the code, model, data, and tests. These versions can prove very helpful for auditing, compliance, back-tracking, preparing new training data, restoring current version in case of issues, retraining models in case of drifts, and for self-learning of models.
Tracking & Governance
It is important to track the collaboration between different stakeholders within MLOps, like data scientists, engineers, testers, product managers, and business stakeholders. This means meticulously logging every detail of every experiment: the parameters you used, the dataset, the evaluation metrics, and the model that was produced. It is about ensuring that the model is secure and reliable, while also complying with expected industry and business standards.
The MLOps Lifecycle
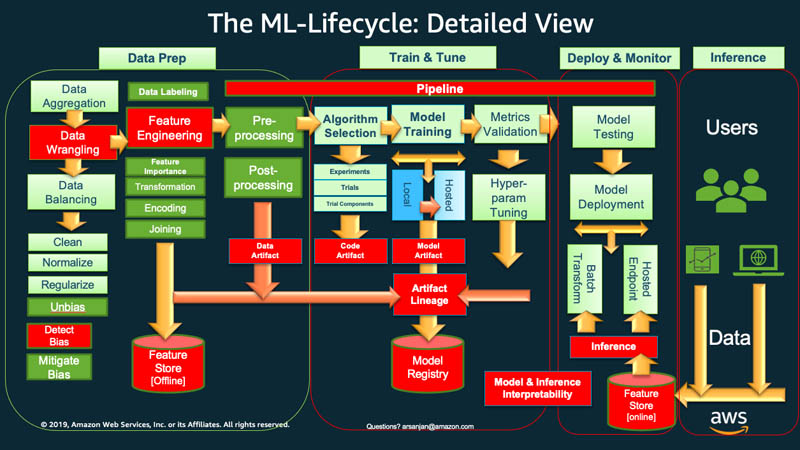
The MLOps lifecycle is a superset of the ML lifecycle. The ML lifecycle’s goal is to create a model, meaning it will involve a lot of manual and exploration-based activities. On the other hand, the MLOps lifecycle’s goal is to turn that ML model into a sustainable product that provides continuous business value.
In the ML lifecycle, you’ll see the following happening:
Data Collection & Preparation
You need to gather the data that will power your model, whether it’s from a database, a stream of user actions, or a collection of images. But raw data is often messy and incomplete. This stage involves the crucial work of cleaning the data – handling missing values, correcting errors, and organizing it into a usable format.
Feature Engineering
Once your data is clean, you need to transform it into features – the specific, relevant pieces of information that your model will use to learn and make decisions. For example, you might combine two columns, convert text into numerical data, or extract a specific pattern from a timestamp. This is a critical step because a good set of features often makes the difference between a mediocre model and a great one.
Model Development & Experimentation
Data scientists take the prepared data and start running experiments, trying different algorithms and configurations to find the best approach for the problem at hand. This stage is all about exploring different ideas, comparing results, and refining the model until it meets the performance goals.
Model Training & Validation
After all the experimentation, the actual model is built. This is where the chosen algorithm “learns” from the data. But the process doesn’t end there. The model then needs to be rigorously validated to ensure it performs well on new, unseen data. This step is a critical quality control measure, proving that the model is ready for the real world and not just memorizing the training data.
Model Deployment & Serving
Once a model has been validated and approved, it’s time to launch it. The model is packaged into a format that a server can understand and then deployed to a production environment. This makes the model’s predictions available to your applications, either in real-time for immediate user interactions or in batches to process large amounts of data.
Model Monitoring & Retraining
The cycle doesn’t end with deployment. This final stage involves continuously monitoring the live model to ensure its performance doesn’t degrade over time (a phenomenon known as data drift). If a decline is detected, this monitoring system can automatically trigger a retraining process, using fresh data to create a new, more accurate model. This self-healing loop is the key to maintaining a reliable AI application for the long run.
Here’s a great depiction of the ML lifecycle visualized by Amazon.
When it comes to the MLOps lifecycle, it is the “how-to” guide for making the ML lifecycle practical and reliable in a real-world business context. You’ll see some crucial stages and practices being added, like:
- Automation: Using CI/CD pipelines to automate data validation, model training, testing, and deployment.
- Version Control: This is not just for code but also for data and the trained models themselves, ensuring reproducibility.
- Continuous Training: An automated process that retrains models on new data when performance degrades.
- Continuous Monitoring: Actively tracking a live model’s performance and data to detect issues like model drift.
- Governance & Collaboration: Establishing a standardized framework for roles, responsibilities, and approvals to ensure models are fair, secure, and compliant.
Levels of MLOps Implementation
Seldom does one see an all-or-nothing implementation of a process. Organizations typically have varying degrees of automation that help them achieve either of these levels of MLOps implementations.
Level 0: The Manual Process (No MLOps)
At this stage, there’s no real MLOps to speak of. The process is completely manual and often disconnected. Data scientists work on their laptops or a local server, writing code in a notebook and running experiments. When they finally have a model they’re happy with, they manually hand it off to the engineering team.
- The Workflow: Data collection and preparation are done by hand. The model is trained and validated in an isolated environment. Getting the model into production is a one-time, manual deployment. If the model starts underperforming, the process starts all over again from scratch.
Level 1: Automated Pipeline
This is the first big step toward a mature MLOps practice. The goal here is to automate the core steps of the machine learning pipeline to ensure reproducibility and consistency. The focus shifts from a manual, one-off model creation to an automated, repeatable process.
- The Workflow: The ML pipeline, from data preparation to model training and evaluation, is automated. This pipeline is often triggered by a schedule or by the arrival of new data. Teams use a centralized model registry to keep track of different model versions and experiment tracking tools to log their results.
Level 2: Automated CI/CD Pipeline
Here, the entire end-to-end process is automated, seamlessly connecting the machine learning pipeline with the software development lifecycle. This is for organizations that want to constantly experiment with new ideas and create new models as quickly as possible. They need to be able to make an improvement to a model and have it live in minutes.
This setup requires everything from the previous level, but with two key additions:
- A Pipeline Orchestrator: This is a system that acts like a project manager, automatically running all the steps of a machine learning project in the correct order without any manual effort.
- A Model Registry: This is a central place to store and track all the different versions of models that have been created.
With these tools, the organization can run a continuous, automated cycle that has three main stages:
- Build the Pipeline: This is the “idea” phase. You have a team that’s constantly trying out new ways to build a model – new algorithms, new data strategies, etc. Every time they find a good new approach, they write it down as a set of automated instructions – source code for your ML pipelines.
- Deploy the Pipeline: Next, you automatically build and test this new blueprint. Once it passes all the checks, it gets deployed. The output of this stage is a live, running pipeline with your new, improved model ready to go.
- Serve the Pipeline: Finally, the model is put to work, making predictions for real users. The system constantly watches how the model is performing with live data. It looks for any signs that the model is becoming less accurate or outdated. If it sees a problem, that information becomes a signal that automatically tells the system to go back to the first stage and start a new cycle of improving the model.
MLOps Tools
Let’s look at some popular tools used during different stages of MLOps.
For Experimentation and Model Management
- MLflow: Every time you train a model, MLflow records the parameters you used, the results you got, and the final model file. It also has a “Model Registry” to store and version-control your best models, making them ready for deployment.
- Weights & Biases (W&B): Like MLflow, W&B is great for tracking and visualizing your experiments. It’s particularly popular for deep learning, as it provides rich dashboards and collaborative features that help teams see what’s working and what isn’t.
For Data Management and Versioning
- DVC (Data Version Control): It works with Git to version control your data and model files, so you can always know exactly what dataset was used to train a specific model.
- Great Expectations: This tool helps you automatically validate your data. You can set up “expectations” or rules about your data. Great Expectations then runs these checks to ensure your data is always high-quality.
For Pipeline Orchestration
- Kubeflow: This is a popular option for organizations running on Kubernetes. It provides a platform to build, deploy, and manage your entire ML workflow, from data processing to model serving, all in one place.
- Apache Airflow: While not strictly for ML, Airflow is widely used to create and schedule complex data and ML pipelines. It’s a great tool for building a repeatable, automated workflow for your models.
For Model Serving and Deployment
- BentoML: This tool helps you package your trained model and its code into a single, ready-to-deploy unit called a “Bento.” It simplifies the process of getting a model into a production environment.
- Seldon Core: This is a powerful, open-source platform that’s used to serve models at scale on Kubernetes. It handles advanced features like A/B testing, different model versions and ensuring reliability.
For Monitoring and Validation
- testRigor: While the other tools focus on the model itself, testRigor is crucial for validating the final user experience. It lets you write automated, plain-English end-to-end tests to ensure that the AI-powered application functions correctly for the end user. This is a vital final check in the MLOps process, ensuring that all your hard work on the model translates into a flawless experience for the person using your product. Read: AI Features Testing: A Comprehensive Guide to Automation.
Apart from these individual tools, you can also use AWS’s Amazon SageMaker or Google’s Vertex AI for MLOps. They offer the entire suite of services you’ll need for MLOps.
How is MLOps different from DevOps?
Though MLOps borrows heavily from DevOps, ML’s complexities make both approaches different.
| Aspect | DevOps | MLOps |
|---|---|---|
| Primary Focus | The software application and the code that runs it. | The entire ML system which includes the code, the data, and the model. |
| Main Artifact | The core “thing” being managed and deployed is the application code and its dependencies. | The core “things” being managed are the application code, the data, and the trained model itself. |
| Key Challenge | Ensuring the code is deployed consistently and the application runs reliably. | Ensuring the model’s performance remains reliable over time, even as real-world data changes. |
| Continuous Loop | Relies on a continuous loop of Integration and Delivery (CI/CD). | Requires a more complex loop that includes CI/CD, plus Continuous Training and Continuous Monitoring. |
| Main Monitoring Focus | Checking the application’s health, server performance, and user satisfaction. | Checking the model’s accuracy, the quality of the data coming in, and detecting model degradation. |
| Team Collaboration | Bridges the gap between developers and IT operations. | Bridges the gap between data scientists, ML engineers, data engineers, and operations. |
MLOps Best Practices

Conclusion
Adopting practices like MLOps is becoming a necessity as our applications incorporate more AI elements. MLOps can help you streamline your creation, training, deployment, testing, and retraining processes. By adopting a good level of automation, you can additionally make sure that your attempts at implementing MLOps within your organization are a success.
Additional Resources
- AI Model Bias: How to Detect and Mitigate
- What is the Role of Quality Assurance in Machine Learning?
- What is Adversarial Testing of AI
- What is Metamorphic Testing of AI?
- Generative AI vs. Deterministic Testing: Why Predictability Matters
- What is Explainable AI (XAI)?
| Achieve More Than 90% Test Automation | |
| Step by Step Walkthroughs and Help | |
| 14 Day Free Trial, Cancel Anytime |









