How to Keep Human In The Loop (HITL) During Gen AI Testing?
|
|
The age of Generative AI (Gen AI) has changed the way we develop, verify, and deploy intelligent systems. The AI is no longer constrained to pre-defined tasks, but makes decisions, interprets, and creates new content on its own instead. This shift in paradigm, although exciting, poses a significant challenge: how can we make it so that these intelligent systems are reliable, ethical, and aligned with human values?

The solution is simply to have the human in the loop (HITL). While Gen AI is taking the center stage, humans are still a key stakeholder as the stewards of trust, making sure that AI decisions can be explained, trusted, and contextually correct. In the world of software testing, this human touch makes testers more than bug-catchers; it turns them into trust architects who influence how intelligent systems function in a way that’s responsible and fair.
As AI has advanced, testing has become more than just preventing hiccups. It’s about failures prevented before they happen and building trust in intelligence. This evolution requires a rethinking of the QA process, one in which humans and AI work together, where oversight intersects with automation, and trust is verified, not taken for granted.
| Key Takeaways: |
|---|
|
The Evolution of Testing in the AI Era
Software testing has echoed the complexity of its serving systems. During past eras, testing was only manual and involved hard labor. Testers clicked through screens, followed checklists, and compared outputs. With the rise of automation, we lived through a revolution in scripts that imitated the same action over and over, freeing humans to pursue analytical tasks.
And then there was AI-enabled testing, where tools started to recognize patterns, predict failures, and auto-generate scripts. Gen AI took this a step further, enabling systems not just to learn knowledge from data but to create new knowledge databases, which help to generate and design tests, and make decisions in context. Hence, the tester’s mission evolved:
| Traditional QA | AI/Gen AI QA |
|---|---|
| Focus: Detecting functional errors | Focus: Building trustworthy intelligence |
| Deterministic verification | Probabilistic validation |
| Manual or scripted tests | AI-driven, self-learning tests |
| Reactive testing | Proactive, preventive validation |
| Quality = correctness | Quality = fairness, explainability, and reliability |
The human role did not disappear; it matured. Testers are elevated to auditors of logic, interpreters of AI reasoning, and guardians of ethical conduct. Short story, testing went from validating your code to validating trust in a system.
The Role of Human-in-the-Loop (HITL) in Gen AI Testing
Human-in-the-Loop (HITL) appeared before the days of Gen AI. First used in automation and robotics, it refers to systems with human operators that can step in if something goes wrong to secure safety and ethical compliance. In AI testing, HITL stands for the human in the loop, incorporating human expertise into the AI lifecycle (design, training, validation, deployment, and monitoring). Read more about Generative AI in Software Testing.
In Gen AI testing, HITL plays multiple layers of responsibility:
- Oversight and Supervision: AI outputs are being reviewed by human testers, who diagnose anomalous behavior and make sure the results still make sense given their role in time. So, for example, if an AI chatbot gives legal advice, a human checks its recommendations for legality and tone. Read: Chatbot Testing Using AI – How To Guide.
- Ethical Judgment: AI systems might also be prone to making harmful or biased decisions by replicating the patterns of flawed data. Human inspectors check to make sure the AI doesn’t cross any social, cultural or moral norms.
- Contextual Understanding: Humans sense tone, sarcasm, and cultural subtext, subtleties that AI still struggles to understand well. The response model uses human feedback to learn situations of contextually relevant answers. Read: AI Context Explained: Why Context Matters in Artificial Intelligence.
- Continuous Improvement: The feedback loop between human and machine that drives learning is what results in adaptivity. Human corrections help to retrain models, cut down on hallucinations, and improve accuracy over time. Read: What are AI Hallucinations? How to Test?
HITL keeps the most autonomous test environments rooted in human wisdom. Machines can learn, but humans teach; machines can act, but humans decide. Read more about AI Compliance for Software.
Why HITL is Still a Critical Role in Gen AI Testing
While Gen AI can scale to perform repetitive, data-heavy tasks, it is constrained by its lack of insight into human intent. It can simulate reasoning, but not moral/relational context. Here’s why HITL remains indispensable:

AI has Blind Spots
AI models are only as good as the data they’ve seen. They can act unpredictably under edge conditions or corner cases of real-world situations. These blind spots humans can help detect and interpret. For example, a model for generative testing may assume that “salary” data is always positive. However, it might not handle edge cases, such as negative adjustments or retroactive deductions. Only a human who knows business logic can catch that. Read: Why Testers Require Domain Knowledge?
Ethical Oversight is Non-Negotiable
AI testing should not breach legal and ethical standards. Each time, human evaluators make sure the model’s suggestions or decisions do not violate the compliance obligations like GDPR or the EU AI Act. For instance, a generative AI model programmed to suggest credit card offers could accidentally recommend premium cards to consumers under the age of 18. A human tester reading the output sees a legal and ethical breach, modifying training rules to exclude underage profiles.
Bias and Fairness Auditing
AI systems commonly adopt bias from the data on which they are trained. HITL testers are used to test for patterns of discrimination, like gender bias in recruitment data or racial bias in facial recognition algorithms. For instance, a recruitment-screening AI prioritizes male candidates over female candidates for leadership roles because its training data disproportionately consists of men as leaders. A human tester realizes this bias, balances the dataset, and re-trains the model so all genders are treated equally. Read more about AI Model Bias: How to Detect and Mitigate.
Interpretability and Accountability
Even if an AI test framework finds issues, someone still has to understand why it has failed. HITL testers offer explanatory reasoning linking model behavior to user experience, business impact, and societal values. For instance, an AI-powered testing system flags a payment flow in a mobile app as “unreliable” with no explanation provided. A human tester looks at the logs, finds only latency problems under specific network conditions, and writes up some contextual notes, turning a vague AI flag into actionable insight.
HITL ensures the system remains explainable, ethical, and auditable, qualities that machines alone cannot promise. Read: What is Explainable AI (XAI)?
Gen AI as an Enabler for Smarter Testing
Gen AI is more than just a challenge for testers; it’s also one of their greatest assets. It multiplies what humans are able to do by self-automating routine tasks and generating “smart” insights.
Smart Automation
Gen AI facilitates the creation of dynamic tests. It can also read requirements in natural language, comprehend intent, and automatically create the test run. For example, tools such as testRigor allow testers to write their tests in plain English, connecting the bridge between technical automation and human understanding.
Synthetic Data Generation
AI systems are typically tested on huge, varied data sets. Gathering this information in real life can raise privacy and ethical concerns. Gen AI can create synthetic but realistic test data spanning gender, race, age, culture, and accessibility. This diversity helps identify biases early. Read more about Test Data Generation Automation.
Governance and Explainability
Test systems that use artificial intelligence can now explain their reasons. When a test fails, AI can point out which features had the greatest impact on the failure. These insights are reviewed and validated by humans to ensure that the explanations correspond with both logic and intuition.
Auditable QA
Today, AI-driven testing platforms keep auditable logs in place, tracking the genesis of test data as well as the logic for conducting certain tests and how results are evaluated over time. These logs are verified by humans to ensure compliance and interpretability.
Gen AI does not replace human intelligence; it extends it. The most successful QA teams in the future won’t be completely automated; they will be powered by AI, with humans at the controls to steer governance and trust.
HITL in the Governance of AI Testing
Governance is the unseen infrastructure of AI safety. It makes sure that AI testing is not only technically correct but ethically and legally compliant.
The core elements of AI testing governance are:
- Accountability: Refers to who is responsible for each testing result, decision or intervention throughout the lifecycle of AI. This clear ownership means every step can be inspected, validated, and optimized as needed, whether human or machine driven.
- Traceability: Means that every AI decision, test result, and change can be traced back to its originating data source or reasoning. This provides visibility for testers and auditors to see how results were derived and confirm accuracy.
- Explainability: Makes sure AI reasoning is clear and intelligible to humans, not simply technically correct. When testers can understand why an AI has behaved the way it did, it bolsters trust, accountability, and confidence in automation.
- Bias Detection: Means monitoring AI outputs for unfair or discriminatory patterns within data and outputs. Human audits allow us to spot and correct them on a regular basis, before they can affect end users or decisions.
- Security & Privacy: Protect sensitive user data when used in testing, to comply with global regulations like GDPR and HIPAA. HITL testers verify that AI systems handle data in a responsible manner, honoring privacy and user rights during the course of QA.
The Human Role in Governance
The auditors of this ecosystem are human testers. They review how the model behaves and test for fairness to make sure each decision is in line with organizational values.
For example, in testing an AI system that approves loans, this HITL process would see human analysts ensuring that the logic of the model does not unfairly penalize applicants due to non-financial attributes such as gender or ethnicity. The human checkpoint turns technical testing into ethical validation. Thus, governance with HITL is not bureaucracy; it’s the conscience of AI quality.
Trust, Transparency, and Explainability in AI QA
One of the greatest challenges in AI is the black box problem, which is that an AI’s decision can be accurate without a clear explanation. Such opacity is unacceptable in areas where accountability counts. Quality assurance teams will also need to verify that AI is both transparent and traceable.
How HITL Enforces Explainability:
- Model Interpretation: Humans verify whether the AI’s decision paths make logical sense.
- Cross-Validation: Testers compare AI-generated explanations with domain expertise.
- User-Centric Clarity: QA ensures that technical explanations can be understood by non-technical stakeholders.
- Feedback Integration: Human feedback on unclear reasoning helps refine the model’s interpretability mechanisms.
An AI testing ecosystem that values transparency is not one where humans blindly trust their results, but rather where they have the confidence to question them.
Auditable QA and the Role of Human Oversight
In the regulated industry, auditability is as important as accuracy. Every aspect of AI behavior, every decision made by a model or an experiment run, needs to be reviewable.
How HITL Strengthens Auditing:
- AI test logs are verified by people for completeness and accuracy.
- They ensure that explanations of failure are consistent and understandable.
- They also audit AI-generated data periodically to align with data governance guidelines.
Auditable QA doesn’t mean slowing down innovation. It means institutionalizing trust, ensuring that every automated action can be explained in terms that a human can understand. The result is an open, verifiable, and trustworthy QA system.
HITL as the Guardian of Trust
In this increasingly AI-driven world, algorithms can affect health diagnoses, hiring decisions, credit approvals, and courtroom sentences. In that world, trust is the coin of AI adoption, and testing is the guardian of that trust.
Testing now pursues a more profound aim: to ensure that intelligence, not just software, behaves responsibly. HITL has played a role in ensuring that the mission’s essence remains human. The human tester is now not simply a “bug hunter” but a trust auditor of digital intelligence. Trust depends on four pillars:
- Reliability: AI behaves consistently and predictably.
- Fairness: No group or individual is disadvantaged.
- Transparency: Every decision can be understood.
- Ethical Integrity: The system aligns with human values.
The HITL tester reinforces all these pillars, making QA the moral compass of the AI era.
HITL in Preventive Testing
Traditional QA served as a rear-view mirror; it discovered problems after they had happened. But with AI, that’s not sufficient. Preventive testing is all about anticipating possible problems and fixing them before you let the code out. Humans play a vital role in this shift:
- Anticipating Bias: Human analysts assess training data to address problems before they bias results.
- Imagining Edge Cases: Humans can extrapolate real-world uncertainties that AI can’t model.
- Ethical Pre-Assessment: Humans are acting as AI would act in morally challenging situations.
- Feedback Loops: Human observations retrain the AI’s internal models over time.
The fusion of AI foresight and human hindsight creates a closed-loop assurance system, one that continuously strengthens quality. Read more about Different Evals for Agentic AI: Methods, Metrics & Best Practices.
Designing HITL-Centric AI Testing Pipelines
A HITL testing pipeline is the bedrock of trustworthy AI validation. It makes sure that a human perspective is smoothly integrated throughout each stage of an automated testing process balancing the need for speed, accuracy and ethical responsibility. For this pipeline to be effective, it needs to be structured, measured, and iteratively improved based on feedback.
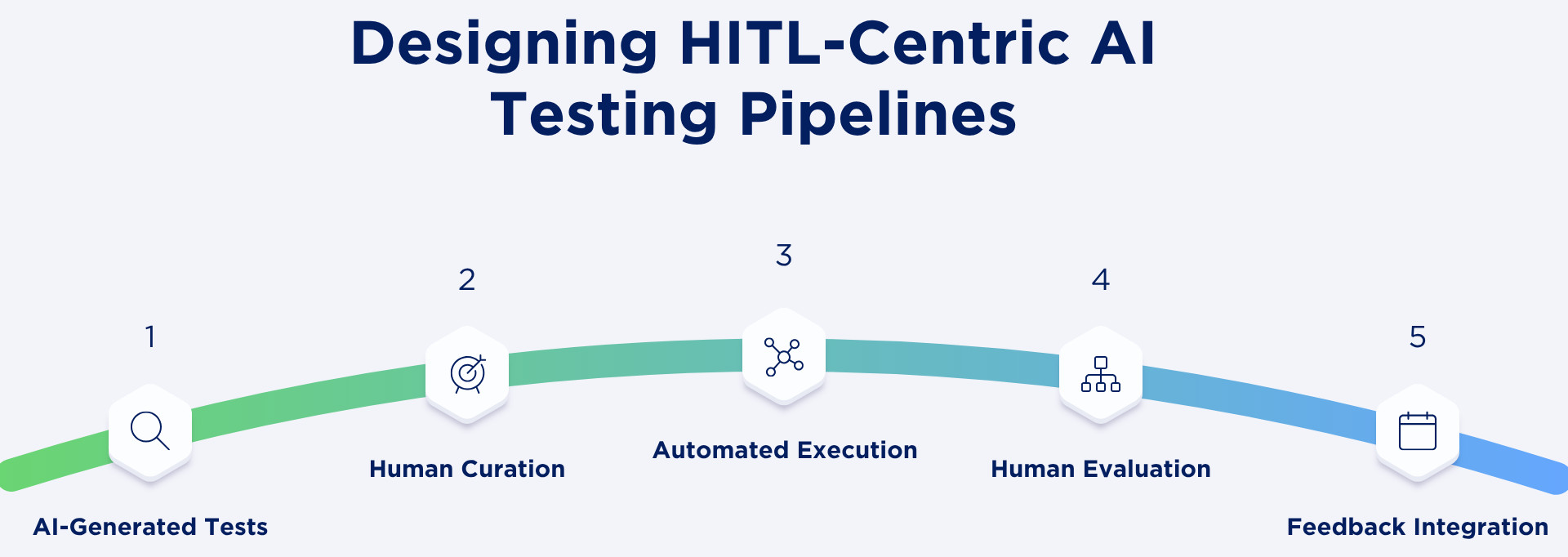
Typical HITL Pipeline:
- AI-Generated Tests: Gen AI automates the creation of test cases with natural language-based comprehension and information from prior records. This will help the testing coverage grow intelligently, based on user stories, edge cases, and unexpected conditions.
- Human Curation: These AI-created cases are reviewed by human testers to make certain they are relevant, bias-free, and ethically sound. They refine or discard any tests that could distort business logic, miss fairness, and inclusivity concerns.
- Automated Execution: The curated test cases are then automated by the system and run at scale after validation. The step provides fast insight cycles as well as a consistent fidelity for different setups and environments.
- Human Evaluation: The AI’s explanations, anomaly reports, and failure justifications are studied by humans to understand why things happened. Their thinking adds relevance and interpretation to the AI’s discoveries, so the results are actionable, trustworthy, and connected to human cognition.
- Feedback Integration: The corrective feedback that the human evaluators provide is continually incorporated back into the AI model to improve its comprehension and performance. This closed-loop feedback allows the system to be trained on human judgment and, in turn over time improves not only accuracy, but fairness and decision transparency.
Key metrics for HITL QA:
- Human Review Ratio (HRR): % of AI actions reviewed by humans.
- Bias Detection Rate (BDR): How often bias is caught before deployment.
- Explainability Index (EI): How understandable AI decisions are.
- Human-AI Agreement Rate (HAR): Frequency of alignment between human and AI evaluations.
- Ethical Assurance Score (EAS): Quantifies ethical and compliance checks.
These metrics make the intangible, trust, transparency, and fairness measurable.
The Future of Human-AI Collaboration in Testing
The future of QA is partnership, not dominance, between humans and AI in assurance. Testers will transition from executing test cases to creating comprehensive review frameworks, defining ethical limits, and interpreting intelligent results as AI matures. Within this new paradigm, AI is a force multiplier for human beings who serve as the conscience of testing, ensuring that automated decision-making continues to be trustworthy, fair and accountable.
Wrapping Up
Generative AI has been a powerful catalyst for the evolution of software, but trust will not be automated in an era of autonomous intelligence. Testing has advanced from discovering errors to assuring that AI behaves responsibly, ethically, and transparently. It’s now up to humans to serve as the moral compass of technology, leading intelligent machines toward responsibility and fairness.
Testers are not gatekeepers anymore; they are trust-keepers in this new age. As AI continues to expand the boundaries of possibility, it will be the human in the loop that demarcates what is and isn’t acceptable.
| Achieve More Than 90% Test Automation | |
| Step by Step Walkthroughs and Help | |
| 14 Day Free Trial, Cancel Anytime |









