Clean Code: Key Dos and Don’ts for Successful Development
|
|
What is the Clean Code?
Let’s talk about the code we write.
It’s not just about making the computer understand it. You also want humans, that is, other developers, to understand it. Imagine you’re writing a set of instructions for someone to follow – if it’s messy, full of jargon, or has shortcuts only you understand, it’ll be hard for others to use.
Clean code is like writing a story that’s easy for others to read and understand.
This blog post is an expanded version of the “Clean Code and Clean ATDD/TDD Cheat Sheet With Dos and Don’ts” by Urs Enzler which is a great read for anyone who is venturing into clean coding.
Let’s dive in.
Characteristics of Clean Code
Clean code helps by being:
- Easy to Read: Clean code uses clear and meaningful names for variables, functions, and classes so anyone can quickly understand what’s happening. It’s like labeling boxes in a storage room. Instead of simply calling it “Box 1,” you write “Winter Clothes.”
- Easy to Understand: It avoids unnecessary complexity. Each part of the code does one thing and does it well. This is like assembling furniture with clear instructions, instead of a confusing mix of diagrams.
- Easy to Maintain: It’s structured and organized, so if something breaks, it’s easy to find and fix. Imagine a tidy kitchen. You can find the right tool quickly without rummaging through clutter.
- Easy to Extend: If you need to add new features, you can do so without rewriting everything. It’s like building with Lego bricks – you can easily add more pieces without tearing the whole thing apart.
- Easy to Avoid Bugs: If you can understand the code, then you can write better code that does not introduce bugs.
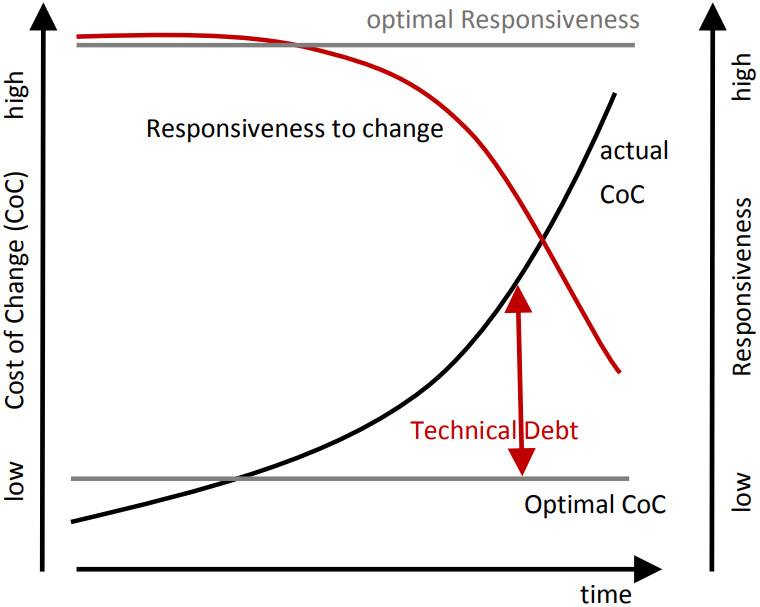
Here’s a great representation of the cost of change in a project (as shown in the cheat sheet).
Writing clean code from the start in a project is an investment. It keeps the cost of change as constant as possible throughout the lifecycle of a software product. Therefore, the initial cost of change is a bit higher when writing clean code (grey line) than quick and dirty programming (black line), but it is paid back relatively soon. Especially if you keep in mind that most of the cost has to be paid during maintenance of the software.
On the other hand, unclean code results in technical debt that increases over time if not refactored into clean code. There are other reasons leading to technical debt, such as bad processes and lack of documentation, but unclean code is a major driver. As a result, your ability to respond to changes is reduced (red line).
Principles to Write Clean Code
As an application grows, so does the code base. You need to follow practices and rules to make sure that the code is scalable and legible in the times to come. Let’s look at them.
| Principle | Explanation | |
|---|---|---|
| ✅ | Loose Coupling | Two classes, components, or modules are coupled when at least one of them uses the other. The less these items know about each other, the looser they are coupled. A component that is only loosely coupled to its environment can be more easily changed or replaced than a strongly coupled component. |
| ✅ | High Cohesion | Cohesion is the degree to which elements of a whole belong together. Methods and fields in a single class and classes of a component should have high cohesion. High cohesion in classes and components results in simpler, more easily understandable code structure and design. |
| ✅ | Keep Change Local | When a software system has to be maintained, extended and changed for a long time, keeping change local reduces involved costs and risks. Keeping change local means that there are boundaries in the design that changes do not cross. |
| ✅ | It is Easy to Remove Components | We normally build software by adding, extending, or changing features. However, removing elements is important so that the overall design can be kept as simple as possible. When a block gets too complicated, it has to be removed and replaced with one or more simpler blocks. |
| ✅ | Mind-sized Components | Break your system down into components that are of a size you can grasp within your mind so that you can predict the consequences of changes easily (dependencies, control flow, …). |
In order to write clean code, you need to pay attention to various aspects of the software development process. Here are some of the important ones:
- Code smell
- Design (of code, class, packages, project structure, etc.)
- Environment setup
- Dependencies
- Naming conventions
- Methods and their behaviors
- Exception handling
- Legacy code
Based on what your investigations reveal, you can refactor, reengineer, remove, or keep the code.
Code Smell
In programming, a code smell is a sign that your code isn’t as clean, efficient, or maintainable as it could be. It is like a bad odor in your house – it doesn’t mean something is definitely broken, but it’s a sign that something might be wrong or could cause trouble later.
Thus, code smell is
- Not a Bug: A code smell doesn’t stop your program from working, but it might make it harder to work with in the future.
- Indicates Deeper Problems: It’s often a symptom of poor design or rushed development.
Tell-Tale Signs of Code Smells
You can characterize code smell by observing your code’s behavior. You’ll observe some, if not all, the signs.
- Rigidity: The software is complex to change. A small change causes a cascade of subsequent changes.
- Fragility: The software breaks in many places due to a single change.
- Immobility: You cannot reuse parts of the code in other projects because of the risks involved and the high effort required.
- Viscosity of Design: This refers to how easy it is to make changes to the code while keeping it clean and aligned with good design principles. Code smell might make it preferable to take a shortcut and introduce technical debt, as it requires less effort than doing it right.
- Viscosity of Environment: This refers to how easy or hard it is to work with the development tools and processes. Building, testing, and other tasks take a long time. Therefore, these activities are not executed properly by everyone, and technical debt is introduced.
- Needless Complexity: The design contains elements that are currently not useful. The added complexity makes the code harder to comprehend. Therefore, extending and changing the code results in higher effort than necessary.
- Needless Repetition: Code contains exact code duplications or design duplicates (doing the same thing in a different way). Making a change to a duplicated piece of code is more expensive and more error-prone because the change has to be made in several places with the risk that one place is not changed accordingly.
- Opacity: The code is hard to understand. Therefore, any change takes additional time to first reengineer the code and is more likely to result in defects due to not understanding the side effects.
How to Deal With Code Smells?
- Refactor: Rewrite or improve the code without changing what it does.
- Keep It Simple: Follow good practices like writing short functions and using clear names.
- Review Regularly: Spot smells early through code reviews and testing.
Code Design
Here are a list of do’s and don’ts for writing clean code:
| Do’s ✅ | Don’ts ❌ |
|---|---|
|
Keep it Simple, Stupid (KISS)
Write simple and straightforward code that does the job. Simplicity reduces bugs and makes your code easier to maintain.
|
Don’t Repeat Yourself
Instead of duplicating a piece of code, create a reusable function.
|
| Follow standard conventions for architecture, naming, coding, and design. | Avoid Multiple Languages in One Source File |
|
Break Code Into Smaller Pieces
Divide code into small, reusable functions and classes. Smaller pieces are easier to understand and maintain.
|
Don’t Overload Classes or Functions
Avoid cramming too many responsibilities into one class or function.
|
|
Boy Scout Rule
Leave the campground (or code base in this context) cleaner than you found it.
|
Code at the Wrong Level of Abstraction
Functionality is at the wrong level of abstraction, e.g., a PercentageFull property on a generic IStack<T>.
|
|
Root Cause Analysis
Always look for the root cause of a problem. Otherwise, it will get you again.
|
Fields Not Defining State
Fields holding data that do not belong to the state of the instance but are used to hold temporary data. Use local variables or extract them to a class, abstracting the performed action.
|
|
Keep Configurable Data at High Levels
If you have a constant such as a default or configuration value that is known and expected at a high level of abstraction, do not bury it in a low-level function. Expose it as an argument to the low-level function called from the high-level function.
|
Avoid Over Configurability
Prevent configuration just for the sake of it – or because nobody can decide how it should be. Otherwise, this will result in overly complex, unstable systems.
|
|
Don’t Be Arbitrary
Have a reason for the way you structure your code, and make sure that reason is communicated by the structure of the code. If a structure appears arbitrary, others will feel empowered to change it.
|
Micro Layers
Do not add functionality on top, but simplify overall.
|
|
Structure over Convention
Enforce design decisions with structure over convention. Naming conventions are good, but they are inferior to structures that force compliance.
|
Don’t Ignore Errors
Don’t skip error handling or assume, “This will never fail.”
|
|
Prefer Polymorphism To If/Else or Switch/Case
There may be no more than one switch statement for a given type of selection. The cases in that switch statement must create polymorphic objects that take the place of other such switch statements in the rest of the system.
|
Don’t Skip Tests
Unchecked code is more likely to break.
|
|
Separate Multi-Threading Code
Do not mix code that handles multi-threading aspects with the rest of the code. Separate them into different classes.
|
Class Design
A class should represent a single concept or entity, and it should be easy to understand, use, and maintain. Class design in clean code is about organizing your code into meaningful, reusable building blocks. By using class design principles, you can design classes that are easy to understand, maintain, and extend without breaking things. Let’s take a look at these principles.
| Principle | Explanation | Example | |
|---|---|---|---|
| ✅ | Single Responsibility Principle (SRP) | A class should have one, and only one, reason to change. If a class does too many things, changing one part can mess up other parts, leading to bugs. |
|
| ✅ | Open Closed Principle (OCP) | A class should be open for extension but closed for modification. You can add new features without altering existing code, which reduces the risk of breaking something. |
|
| ✅ | Liskov Substitution Principle (LSP) | If a class is a child of another class, it should be able to replace the parent class without causing issues. This ensures inheritance works properly without breaking the program. |
|
| ✅ | Dependency Inversion Principle (DIP) | Classes should depend on abstractions (interfaces) rather than concrete implementations. This makes the code more flexible and easier to change or extend. |
|
| ✅ | Interface Segregation Principle (ISP) | Classes should not be forced to implement interfaces they don’t use. Smaller, focused interfaces make classes simpler and reduce unnecessary code. |
|
Apart from these, there are a few more points you can keep in mind like:
- Classes should be small. A class should be small enough to understand without much effort. Smaller classes are easier to read, test, and reuse.
- Implement encapsulation. A class should hide its internal details and expose only what’s necessary.
- Keep related things together. All parts of a class should be closely related to its purpose.
Package Cohesion and Coupling
When working with packages in code (grouping related classes and functionalities), two key concepts are cohesion and coupling. Understanding these helps you design better, cleaner systems.
Package Cohesion
Cohesion is about how closely related the elements (classes, functions) inside a package are to each other. A cohesive package has elements that belong together and work towards a single purpose.
In simple terms …
Think of a package like a toolbox. If it’s cohesive, all the tools (code elements) are for one specific task, like fixing bikes. A messy toolbox with bike tools, cooking utensils, and gardening tools is not cohesive.
Principles for Package Cohesion
| Principle | Explanation | Example |
|---|---|---|
| Release Reuse Equivalency Principle (RREP) | A package should only include classes that are reused together and released together. | Think of a package like a meal combo at a restaurant. Everything in the combo (burger, fries, drink) is meant to be ordered and consumed together. You don’t want random items like sushi in a burger combo – it’s confusing and doesn’t fit. |
| Common Closure Principle (CCP) | Classes in a package should change for the same reasons and at the same time. | Imagine a drawer in your home labeled “winter clothes.” If the seasons change and you need to swap your winter gear for summer clothes, everything in that drawer gets updated together. It wouldn’t make sense to have random items like books in there. |
| Common Reuse Principle (CRP) | Classes in a package should be reused together. If you use one class from the package, you’re likely to use the others as well. | Think of a toolbox. All tools in the toolbox should be for a specific task, like bike repair. You wouldn’t want to carry a huge toolbox just to use one screwdriver, especially if most of the tools are irrelevant to your task. |
Package Coupling
Coupling refers to how tightly connected one package is to another. In clean code, you aim for low coupling – packages should work together without being overly dependent.
In simple terms …
If packages are like houses, the coupling is the number of roads connecting them. A few well-placed roads make traveling easy (low coupling), but a web of tangled roads makes it chaotic (high coupling).
Principles for Package Coupling
| Principle | Explanation | Example |
|---|---|---|
| Acyclic Dependencies Principle (ADP) | Packages should not have circular dependencies. A circular dependency happens when Package A depends on Package B, and Package B depends back on Package A, creating a loop. | Imagine two houses in a neighborhood. If House A depends on House B’s electricity, and House B depends on House A’s water supply, a problem in one house can cause chaos for both. This is a circular dependency, and it’s bad. |
| Stable Dependencies Principle (SDP) | A package should depend on more stable packages – those that are less likely to change. | Imagine building a house on a strong foundation (like a rock) versus a shaky one (like sand). If the foundation is unstable, the entire house is at risk when something shifts. Similarly, your package should depend on stable, reliable packages. |
| Stable Abstractions Principle (SAP) | A package that is stable (unlikely to change) should also be abstract (define interfaces), not filled with concrete implementations. | Abstractions allow flexibility while keeping the core package stable. Think of a library. A stable library offers general rules (like “don’t make noise”), but how you follow those rules (e.g., reading books silently, using headphones) depends on individual users. The rules are stable, and specific behaviors are flexible. |
Naming Conventions
Naming conventions are like creating labels for everything in your code so others (and future you!) can quickly understand what each part does. Good names make your code easier to read, debug, and maintain. Here are some do’s for naming conventions:
| Do’s | Explanation |
|---|---|
| Choose Descriptive / Unambiguous Names | Names have to reflect what a variable, field, or property stands for. Names have to be precise. |
| Choose Names at Appropriate Level of Abstraction | Choose names that reflect the level of abstraction of the class or method you are working in. |
| Name Interfaces After Functionality They Abstract | The name of an interface should be derived from the client’s usage of it. |
| Name Classes After How They Implement Interfaces | The name of a class should reflect how it fulfills the functionality provided by its interface(s), such as MemoryStream: IStream |
| Name Methods After What They Do | The name of a method should describe what is done, not how it is done. |
| Standard Nomenclature Where Possible | Don’t invent your own language when there is a standard. |
Methods
In clean code, methods (also called functions) are like small, focused tools that perform specific tasks. Writing clean methods is about making them simple, clear, and reusable so your code is easy to understand, debug, and maintain.
Here’s a list of do’s and don’ts for writing methods:
| Do’s ✅ | Don’ts ❌ |
|---|---|
|
Methods Should Do One Thing
Keep the purpose of the method clear.
|
Don’t Hardcode Values
Hard coding makes methods inflexible and more complex to adapt to changes.
|
|
Keep Methods Small
A method should do one thing and do it well. Ideally, it should fit within a few lines of code. Small methods are easier to read, test, and debug.
|
Don’t Return Multiple Unrelated Things
Returning too many things makes the method confusing and more challenging to use.
|
|
Use Parameters Wisely
Pass only the information the method needs. Avoid too many parameters (ideally 1-3). Fewer parameters make the method easier to use and test.
|
Don’t Use Global Variables Inside Methods
Global variables make methods unpredictable and harder to test.
|
|
Avoid Duplicating Code
If you’re writing the same logic in multiple places, put it in a method and reuse it.
|
Don’t Skip Error Handling
Methods that don’t handle errors properly can crash your program.
|
|
Return Results, Not Print Statements
A method should return data rather than printing it directly unless its job is specifically to display something.
|
Don’t Ignore Return Values
Ignoring return values means losing important data from the method.
|
|
Avoid Too Many Nested Levels
Limit nested if statements, loops, or other structures within a method.
|
Don’t Use Ambiguous Booleans
Methods with unclear boolean parameters are confusing.
|
|
Use Void Methods Sparingly
Void methods (methods that don’t return anything) should be used only when the action doesn’t produce a meaningful result.
|
Don’t Add Unnecessary Comments
Comments should explain why, not what. The code itself should be clear enough to explain what.
|
Source Code Structure
The structure of your source code is like the organization of a house. If everything is neatly placed where it belongs, you can easily find what you need.
| Principle | Explanation | |
|---|---|---|
| ✅ | Vertical Separation | Variables and methods should be defined close to where they are used. Local variables should be declared just above their first usage and should have a small vertical scope. |
| ✅ | Separation of Concerns | Keep unrelated tasks in different files or folders. |
| ✅ | Modularity | Break code into reusable, self-contained components. |
| ✅ | Environment-Specific Separation | Keep configs for development and production separate. |
| ✅ | Clear Naming | Use descriptive and consistent names for files and folders. |
| ✅ | Minimal Nesting | Avoid deeply nested folder structures. |
| ✅ | Consistency | Stick to a single way of organizing and naming across the project. |
| ✅ | Single Entry Point | Have one main file to initialize the application. |
Exception Handling
Exception handling is like a safety net for your code. It ensures that your program behaves gracefully when something unexpected happens, like missing files or invalid user input.
| Do’s ✅ | Don’ts ❌ |
|---|---|
|
Catch Specific Exceptions
Catch exceptions as specific as possible. Catch only the exceptions for which you can react in a meaningful manner.
|
Don’t Use Exceptions for Control Flow
Using exceptions for control flow has bad performance, is hard to understand and results in very hard handling of real exceptional cases.
|
|
Catch Where You Can React in a Meaningful Way
Only catch exceptions when you can react in a meaningful way. Otherwise, let someone up in the call stack react to it. This ensures the right part of the program deals with the issue.
|
Don’t Swallow Exceptions
Exceptions can be swallowed only if the exceptional case is completely resolved after leaving the catch block. Otherwise, the system is left in an inconsistent state.
|
|
Use Exceptions instead of Return Codes or null
In an exceptional case, throw an exception when your method cannot do its job. Don’t accept or return null. Don’t return error codes.
|
Don’t Overuse Exceptions
Exceptions should be used for truly exceptional situations, not for normal control flow.
|
|
Fail Fast
Exceptions should be thrown as early as possible after detecting an exceptional case. This helps to pinpoint the exact location of the problem by looking at the stack trace of the exception.
|
|
|
Use Meaningful Error Messages
Provide clear, descriptive messages when raising or handling exceptions.
|
Legacy Code to Clean Code
Transitioning from legacy code (old, messy, or hard-to-maintain code) to clean code (modern, readable, and maintainable code) can be tricky since the fear of breaking the entire structure is always there. Here are some do’s that will help you with it:
| Principle | Explanation | |
|---|---|---|
| ✅ | Always have a Running System | Change your system in small steps from a running state to a running state. |
| ✅ | Identify Features | Identify the existing features in your code and prioritize them according to how relevant they are for future development (likelihood and risk of change). |
| ✅ | Introduce Boundary Interfaces for Testability | Refactor the boundaries of your system to interfaces so that you can simulate the environment with test doubles (fakes, mocks, stubs). |
| ✅ | Write Feature Acceptance Tests | Cover a feature with Acceptance Tests to establish a safety net for refactoring. |
| ✅ | Identify Components | Within a feature, identify the components used to provide the feature. Prioritise components according to relevance for future development (likelihood and risk of change). |
| ✅ | Refactor Interfaces Between Components | Refactor (or introduce) interfaces between components so that each component can be tested in isolation from its environment. |
| ✅ | Write Component Acceptance Tests | Cover the features provided by a component with Acceptance Tests. |
| ✅ | Decide for Each Component: Refactor, Reengineer, Keep |
Decide whether to refactor, reengineer, or keep each component.
* Refactor Component: Redesign classes within the component and refactor step by step. Add unit tests for each newly designed class.
* Reengineer Component: To reimplement the component, use ATDD and TDD (see the Clean ATDD/TDD cheat sheet).
* Keep Component: If you anticipate only a few future changes to a component and the component had few defects in the past, consider keeping it as it is.
|
Code Refactoring
Over time, as projects grow and evolve, the codebase can become cluttered, with duplicated logic, unclear names, or overly complex methods. Refactoring helps clean up this mess by reorganizing and simplifying the code. This makes it easier for developers to understand, debug, and extend the code in the future. It also reduces technical debt and ensures that small fixes today prevent bigger problems later. By regularly refactoring, you maintain a high standard of code quality, enable faster development, fewer bugs, and a more collaborative coding environment.
Refactoring Patterns
| Principle | Explanation | |
|---|---|---|
| ✅ | Reconcile Differences – Unify Similar Code | Change both pieces of code stepwise until they are identical. Then extract. |
| ✅ | Isolate Change | First, isolate the code to be refactored from the rest. Then refactor. Finally, undo isolation. |
| ✅ | Migrate Data | Move from one representation to another by temporary duplication of data structures. |
| ✅ | Temporary Parallel Implementation | Refactor by introducing a temporary parallel implementation of an algorithm. Switch one caller after the other. Remove old solution when no longer needed. This way, you can refactor with only one red test at a time. |
| ✅ | Demilitarized Zone for Components | Introduce an internal component boundary and push everything unwanted outside of it into the demilitarized zone between the component interface and the internal boundary. Then, refactor the component interface to match the internal boundary and eliminate the demilitarized zone. |
| ✅ | Refactor before adding Functionality | Refactor the existing code before adding new functionality so that the change can easily be made. |
| ✅ | Small Refactorings | Only refactor in small steps with working code in-between so that you can keep all loose ends in your head. Otherwise, defects sneak in. |
Conclusion
To write clean code requires a multi-pronged approach. While there are many principles and guidelines out there, you need to figure out what works best for you. Assess the resources you have at hand and build an approach accordingly.
Additional Resources
- Maximize Your Test Script Quality: Coding Standards and Best Practices
- Latent Defects Decoded: The Hidden Perils in QA
- Masked Defects Uncovered: Shining Light on the Hidden Flaws
- STLC vs. SDLC in Software Testing
- Managing Your Test Environment: What You Need to Know
- How to Get The Best ROI in Test Automation
- What is the Cost of Quality in Software Testing?
- Best Practices for Scaling Test Automation
| Achieve More Than 90% Test Automation | |
| Step by Step Walkthroughs and Help | |
| 14 Day Free Trial, Cancel Anytime |









