Data-driven Testing: How to Bring Your QA Process to the Next Level?
|
|
Have you ever encountered a test case where you need to test the same scenario multiple times by changing the input data? In such a situation, manually changing the test data each time can be tedious, especially if the test itself is automated. It would help if you had a way to build your test data so that you can run a given test with varying inputs, and this is precisely what the data-driven testing approach is all about. If you often find yourself needing to work with different permutations of parameter values, then this is your way ahead.
| Key Takeaways: |
|---|
|
What is Data-driven Testing?
Data-driven testing is a great way to optimize your testing strategy. This approach focuses on segregating the test logic from the data set. This helps decouple the two so that changes can be made easily to the necessary portions of the tests. You could provide this data set in the form of files that are in XML, SQL database, Excel sheets, CSV, or other formats. Through this form of testing, the expectation is to mimic real-world data formats so that the system is thoroughly vetted before release. This can be achieved by mimicking production databases using data masking or using services or methods that generate such data.
For example, you need to test a sign-up form that requires the user’s name, phone number, and email address. While doing so, you want to make sure that you also check numerous negative scenarios, such as an invalid phone number or email address format. This means that you want to fill out the same sign-up form multiple times, but with different input parameters.
The goal behind data-driven testing is to focus on organizing the code in such a way that the dataset values can be sent in as parameters. Hence, it is also known as parameterized testing. During run time, for each iteration of the test case, the parameter variables are replaced by data values.
Read: Data-driven Testing Use Cases.
When to Use Data-driven Testing?
This approach is best used when:
- The same scenario needs to be tested over and over again with different input values.
- An existing test scenario needs to be improved from a coverage perspective.
- Negative test cases need to be checked. Thus, invalid data rows are added to the data set.
Designing Effective Test Data for Data-Driven Testing
The success of data-driven testing depends heavily on the quality and intent behind the test data being used. Simply adding large volumes of data does not automatically improve test coverage. Instead, effective data-driven testing requires carefully designed datasets that reflect real-world usage, edge cases, and business rules. Test data should be purposeful, with each data row contributing meaningful validation rather than repeating similar outcomes.
Well-designed test data considers relationships between inputs rather than treating each field in isolation. For example, certain combinations of values may only be valid under specific conditions, such as user roles, account states, or geographic constraints. Data-driven testing enables testers to model these dependencies directly within datasets, making it easier to validate complex business logic without complicating test scripts.
Another important aspect of test data design is balance. While it is important to include negative and boundary values, excessive invalid data can reduce clarity and increase execution noise. A thoughtful mix of valid, invalid, boundary, and edge-case data ensures that tests remain focused, readable, and effective while still uncovering defects that matter most to end users.
Advantages of data-driven testing
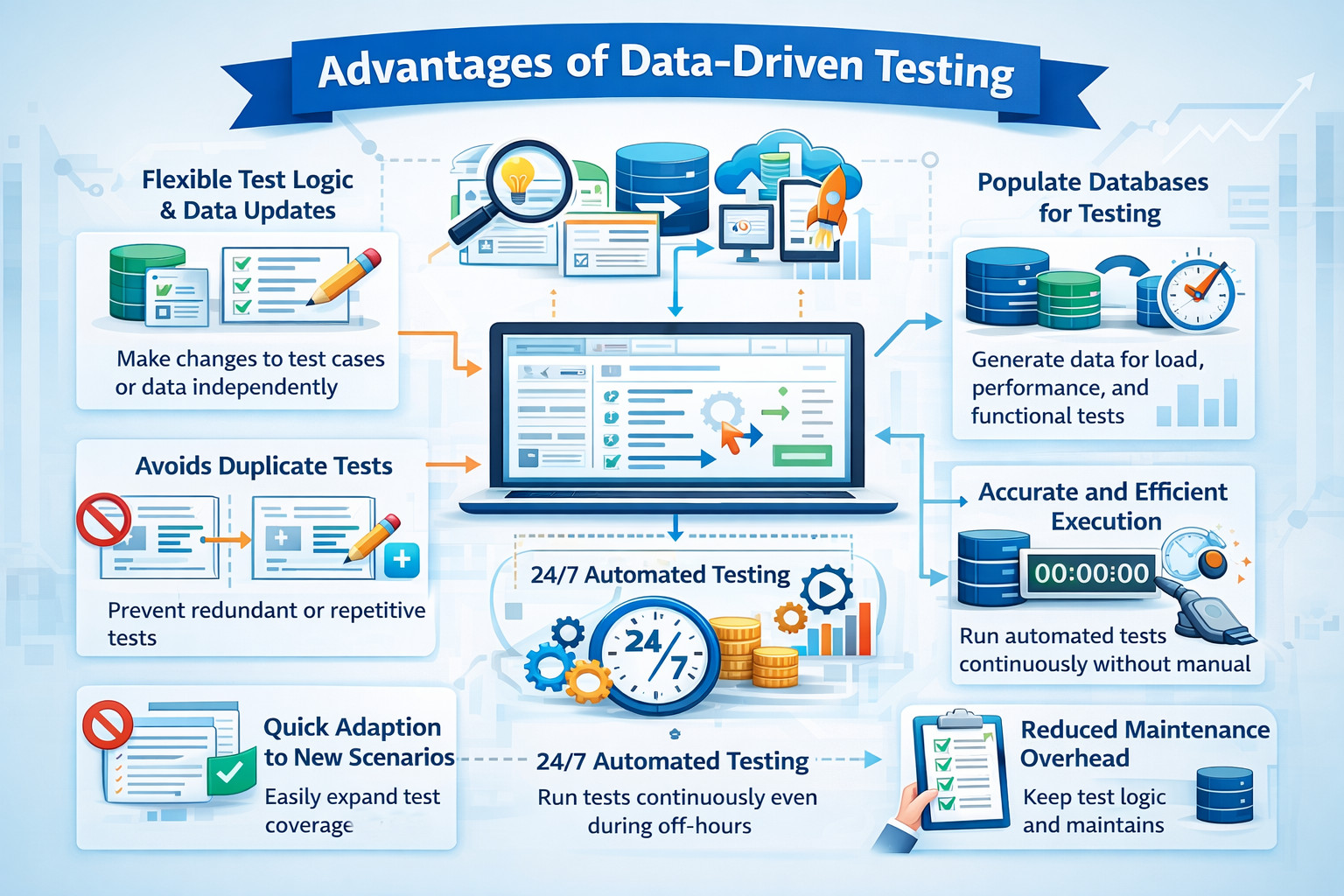
The advantages of data-driven testing are as follows.
- Due to the segregation of test logic and test data, it is easier to make updates to either. This comes in handy in complex test scenarios where multiple tests are interdependent.
- It can be used to populate the database for load, performance, or functional testing, or even for demo purposes.
- Writing duplicate or redundant tests can be avoided using this method.
- In situations where new issues or use cases are reported, if the test logic already exists, then modifications to the data set can help prevent such issues in the future.
- If automation is used, then the tests can run for hours without manual intervention, even during off-hours.
- With automation, greater accuracy can be achieved as opposed to a manual tester doing the same activity. It is a repetitive task, and due to the chance of human error, there is a possibility that issues may get leaked, no matter how experienced the tester is.
- Not having to hard-code data makes the test logic concise and also allows for clean and lean data storage methods. This also reduces test maintenance.
Read: Dynamic Data in Test Automation: Guide to Best Practices.
Data-driven Testing Framework
Now that you know when to opt for data-driven testing, let’s look into what needs to be done to implement it.

Step 1: Identify the scenarios that need input in the form of data sets
This can be done by referring to the above sections.
Step 2: Identify a data storage source to save the data set in and connect it
The data set needs to be stored in a place that can be accessed through your code. This compatibility needs to be checked. Also, when doing so, check for specifications of the source, like the number of rows that can be supported, the type of characters, and so on. These specifications should not hamper your data set.
Step 3: Create test data
The data set can be generated manually or through a tool that creates such data. This data can then be stored in the identified data source.
Step 4: Segregate the code and data set part of the test cases
If there are any hard-coded test values or custom logic to produce such data, now is the time to clean it up. Ideally, your test logic should be concise and take data as input parameters. Also, try to break the logic into reusable chunks so that those methods can be reused.
Step 5: Execute the tests using the proper tools
For this step, ensure that you use an automation tool that serves your needs.
Step 6: Use the results to make necessary changes
Depending on the test logic written and the automation tool used, the before and after states will be saved. These can be used to compare and verify if the expectation is met.
Read: Test Data Generation Automation.
Test Data Reusability and Scalability
As test suites grow, managing test data effectively becomes just as important as maintaining test logic. One of the key strengths of data-driven testing is the ability to reuse datasets across multiple test scenarios, teams, and testing types. Well-structured data sets can support functional testing, regression testing, and even non-functional testing without duplication.
Scalability in data-driven testing comes from organizing data in a way that allows it to evolve alongside the application. Instead of embedding assumptions directly into test scripts, reusable datasets make it easier to adapt to changing requirements by updating values rather than rewriting tests. This approach also promotes consistency, ensuring that similar scenarios are validated using the same data definitions across the test suite.
Reusable and scalable test data also improves collaboration. When test data is clearly defined and centralized, it becomes easier for teams to review, refine, and extend coverage over time. This reduces fragmentation and ensures that data-driven testing remains an asset rather than a maintenance burden as systems and teams grow.
Some Pointers for Testers
Below are some practical tips to keep in mind when adopting a data-driven testing approach to ensure effectiveness, scalability, and long-term maintainability.
- Design test cases and datasets thoughtfully so that each data variation adds meaningful coverage and helps uncover real vulnerabilities rather than repeating similar outcomes.
- Write test logic that is independent of specific data values, allowing the same test to run seamlessly with different datasets without modification.
- Ensure a balanced mix of positive, negative, boundary, and edge-case scenarios to validate both expected behavior and failure handling.
- Treat test datasets as immutable inputs during execution and avoid altering data values within test logic to prevent inconsistent or misleading results.
- Maintain consistency in the chosen data storage format and location to centralize test data management and improve collaboration across teams.
- Review test execution reports carefully after each run to identify patterns, data-specific failures, and opportunities to refine datasets for better coverage.
Data Privacy, Compliance, and Security in Data-Driven Testing
As applications handle increasing amounts of user and business data, test environments have become an extension of an organization’s overall data ecosystem. This makes it essential for data-driven testing practices to address privacy, regulatory compliance, and security with the same rigor applied to production systems.
Protecting Sensitive Test Data
Data-driven testing often relies on production-like data to achieve realistic coverage, but this also increases the risk of exposing sensitive or regulated information. To balance realism with responsibility, test data should be handled in a way that minimizes risk while still supporting effective validation. Avoiding the direct use of raw production data and protecting sensitive fields are essential steps in reducing unintended data exposure.
- Avoid using raw production data directly in test environments
- Apply data masking, anonymization, or tokenization to sensitive fields
- Prefer synthetic data generation where possible
Meeting Compliance and Regulatory Requirements
Test data used during automation and validation is subject to the same regulatory expectations as production data. Compliance with data protection laws ensures that organizations remain aligned with legal and ethical standards while conducting testing activities. Data-driven testing strategies should explicitly account for regulatory obligations across all environments.
- Ensure compliance with regulations such as GDPR, HIPAA, and regional data protection laws
- Define clear data retention and cleanup policies
Securing Test Data Access and Usage
Beyond privacy and compliance, secure handling of test data is critical to maintaining trust and system integrity. Test datasets should be protected from unauthorized access and unintended modification. Clear access controls and disciplined usage practices help ensure that data-driven tests remain reliable and safe.
- Restrict access to test datasets using role-based permissions
- Store test data securely and treat it as read-only during test execution
How does testRigor Handle Data-driven Testing?
Among the various tools available in the market to generate and test with data sets involved, testRigor is one such tool. It comes loaded with features and outshines most other tools due to its ability to allow commands in plain English, as well as practically eliminating test maintenance.
A key differentiator in testRigor’s approach is that data-driven testing does not require users to write or manage complex scripts, loops, or external frameworks. By abstracting test logic and data handling into natural language instructions, testRigor enables both technical and non-technical users to design scalable data-driven tests without deep programming knowledge. This significantly lowers the barrier to adoption while still supporting enterprise-level testing needs.
When it comes to data-driven testing, testRigor allows you to define both global variables and data sets in the test data section. You can also upload any existing data set files from your computer and use them for your tests.
'generate unique email, then enter into "Email" and save as "newEmail"
generate from regex "[A-Z][a-z]{15}", and save as "generatedName"
Beyond basic uniqueness, testRigor supports intelligent data generation that adapts to the context of the test. This makes it possible to generate realistic, format-compliant data on the fly, reducing dependency on static files and minimizing test data maintenance. Such capabilities are particularly useful in large test suites where data freshness and variability are critical for reliable results.
Feel free to refer to the documentation section and search for more information on testRigor’s features.
Conclusion
Data-driven testing is a great way to expand the test coverage and bring your testing process to the next level. When combined with automation, it can be an extremely efficient way to test thoroughly while also being efficient with reusing the same test case with various inputs. Just be sure that the test scenarios are designed in a way that holds true to the essence of data-driven testing, that is, decoupling test logic and test data.
| Achieve More Than 90% Test Automation | |
| Step by Step Walkthroughs and Help | |
| 14 Day Free Trial, Cancel Anytime |









