What are LLMs (Large Language Models)?
|
|
Language is the foundation of human communication. Over the centuries, we have developed countless tools to understand, translate and interact with different languages. However, with the advance of Artificial Intelligence, there is a huge transformation in how machines understand process human language. The most prominent advancement in this domain is the development of Large Language Models, or simply LLMs.
Large Language Models have revolutionized natural language processing by enabling machines to generate text similar to human style, answer queries, translate languages and also to have conversations smoothly with humans. From search engines to chatbots and many more, LLMs are everywhere.
But what exactly are LLMs? How do they work, and why are they so impactful? This article will explore the world of Large Language Models, understanding more about their structure, functioning, applications, benefits, challenges, and future prospects.
What Are LLMs?
Large Language Models are part of Artificial Intelligence models that are designed to understand, interpret, and generate text in a human understandable format. The name “Large” is because the models are trained on huge datasets that contain text from books, articles, websites, and other sources. These models have billions of parameters that help to understand and generate text that resembles similar to human writing. These parameters also help to determine the relationship between words, phrases, and concepts. For example:
- GPT-3: 175 billion parameters
- GPT-4: Estimated to have over 1 trillion parameters (not officially disclosed)
- PaLM 2 (Google): 540 billion parameters
The larger the number of parameters, the more powerful the model will be in handling complex language tasks.
Different Types of Large Language Models
Based on the type or the usage, LLMS are classified into different types. Let’s understand about the common types:
- Zero-shot Model. This is a general model trained on a generic corpus of data. It can provide reasonable results for general use cases directly without further training. GPT-3 is frequently referred to as a zero-shot model.
- Fine-tuned or Domain-specific Models. By adding further training atop some zero-shot models like a GPT-3, we arrive at a fine-tuned, domain-specific model. A concrete example of this is OpenAI Codex, a GPT-3-based domain-specific LLM for programming.
- Language Representation Model. One example of a language representation model is Google’s Bert. It uses transformers which are more suited to NLP.
- Multimodal Model. It is a step away from the pure text inputs for which LLMs were originally tuned in toward being able to process both text and images (multimodal). An example of such a model is GPT-4.
Core Objectives of LLM in AI
The primary objective of LLM is to understand and generate text that is human-like. Let’s go further to understand how this is achieved.
Learning Patterns, Grammar, and Context from Data
LLMs are trained on massive datasets that contain text from different sources. Through this training, they:
- Learn Patterns in Languages: Understand the structure of the sentences, common word combinations, and stylistic patterns.
- Understand Grammar: Understand the rules and variations of grammar without teaching.
- Absorb Context: Able to interpret words based on their surrounding context, which helps to handle ambiguity and long-form text.
For example, the phrase “apple” can be a fruit or a company. LLMs infer the meaning based on the ‘context‘ like:
- “Are you having apple for lunch?” – Fruit
- “This week Apple released a new iPhone” – Company
Predicting the Most Probable Next Word
The core of LLMs is language modeling, which means predicting the next word in a sequence based on the words that come before it.
- During training, LLMs repeatedly guess the next word and adjust their model to improve accuracy.
- With this approach, LLMs can build a probabilistic understanding of the model.
- Over the period of time, LLMs will be able to generate logical, fluent, and natural-sounding sentences.
For example, From the user input “The sky is”, LLM can predict the next word based on the pattern like:
- “blue” is a common next word.
- “clear” or “cloudy” are also reasonable predictions.
Generating Coherent and Contextually Appropriate Text
Once the LLM is trained, it can generate text that is grammatically correct and also contextually relevant. This experience allows the model to:
- Answer questions accurately.
- Write essays, articles, or creative content.
- Generate code, emails, or summaries.
- Engage in human-like conversations.
LLMs adjust their output based on the context provided by the user, making sure the generated text aligns with the conversation or task.
For example, if the user prompts, “Write a professional email to a client about a project update.”. Then, the LLM generates a formal and structured email.
Learning from Data Instead of Pre-written Rules
Traditional rule-based models require developers to write explicit rules for every language scenario. However, this is not required with LLMs. LLMs learn language patterns from data. This helps them to:
- More Flexible: Capable of handling diverse topics, writing styles, and complex queries.
- More Adaptive: They can generalize from training data to respond to new, unseen inputs.
LLMs vs.Traditional NLP Models
Before LLMs, natural language processing relied on statistical models, which analyzed word frequencies and co-occurrences, rule-based systems that required manually defined grammar patterns, and shallow machine learning models that could only handle specific tasks with limited context awareness. These traditional approaches struggled with understanding deeper linguistic relationships and often failed to generalize across different tasks.
LLMs represent a paradigm shift by processing language contextually. They consider entire sentences or paragraphs instead of isolated words. Unlike earlier models that treated words independently, LLMs understand meaning based on context. It allows them to interpret ambiguous terms correctly. Additionally, they generalize across multiple tasks—such as translation, summarization, and conversation. This happens without requiring separate models for each, making them far more flexible and powerful.
How LLMs Work: The Fundamentals
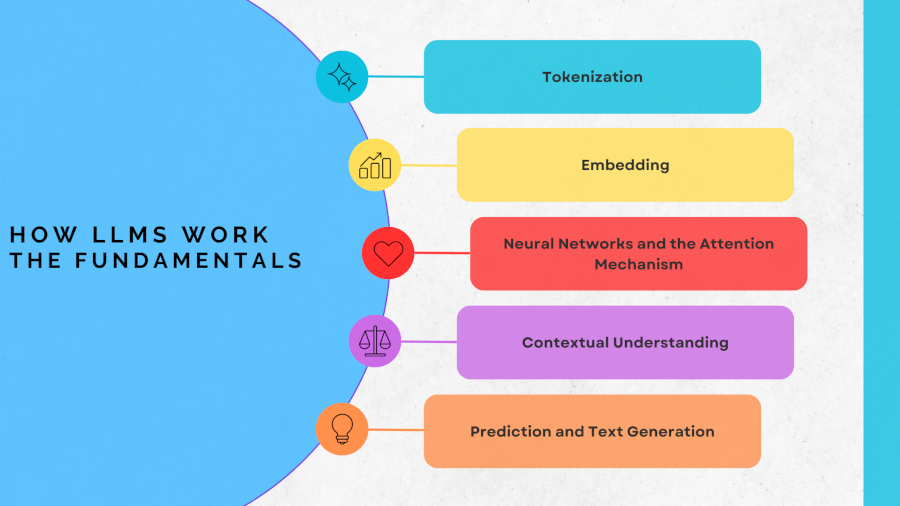
At the core, LLMs are probabilistic models, meaning they rely on statistical relationships between words and phrases to generate coherent and contextually appropriate responses. Let’s go through the key components of Large Language Models.
Tokenization
Before the LLM processes the text, the input is first tokenized. Tokenization means the process of breaking down the prompt or sentences into smaller units called tokens. These tokens can be:
- Whole words (e.g., “cat”)
- Subwords (e.g., “play” and “ing” in “playing”)
- Characters (in some models)
["The", "cat", "is", "sleeping", "."]
Tokenization helps the model to process the text in a structured manner.
Embedding
Once tokenized, these tokens are converted into numerical representations called embeddings. They are high-dimensional vectors that capture the semantic meaning of the words.
For example, the word “king” may have an embedding vector close to that of “queen”, reflecting their semantic similarity. Embeddings enable LLMs to understand words in relation to each other.
Neural Networks and the Attention Mechanism
Modern LLMs use deep neural networks, known as transformer architectures, mainly designed for processing sequential data and analyzing text. The key innovation in transformer architecture is the attention mechanism. This allows the model to determine which words in the sentences are most relevant while making predictions.
For example, consider the sentence, “The cat is sleeping on the mat.” The attention mechanism helps the model recognize that “sleeping” is more related to “cat” than to “mat.”
The attention mechanism assigns different weights to words based on their importance. It also helps the model consider range dependencies (e.g., understanding words even if they are far apart in a sentence).
Contextual Understanding
Traditional models are used to process words independently. But LLMs consider context to derive meaning. For example, consider below two sentences:
- “Apple is a fruit.”
- “Apple released a new iPhone.”
Here, “Apple” refers to a fruit in the first sentence and a company in the second sentence. LLMs understand the correct meaning based on the surrounding words. This ability helps LLM to understand different meanings of the same word, follow the conversational flow, and also maintain coherence in long passages of text.
Prediction and Text Generation
LLMs generate text by predicting the next word or token based on the probability. Consider the input, “The sun is shining and the sky is…”. The model will calculate the most probable next words like:
- “blue” (high probability)
- “cloudy” (moderate probability)
- “falling” (low probability)
It then selects the most appropriate option and continues generating text word by word.
Large Language Models: Key Components
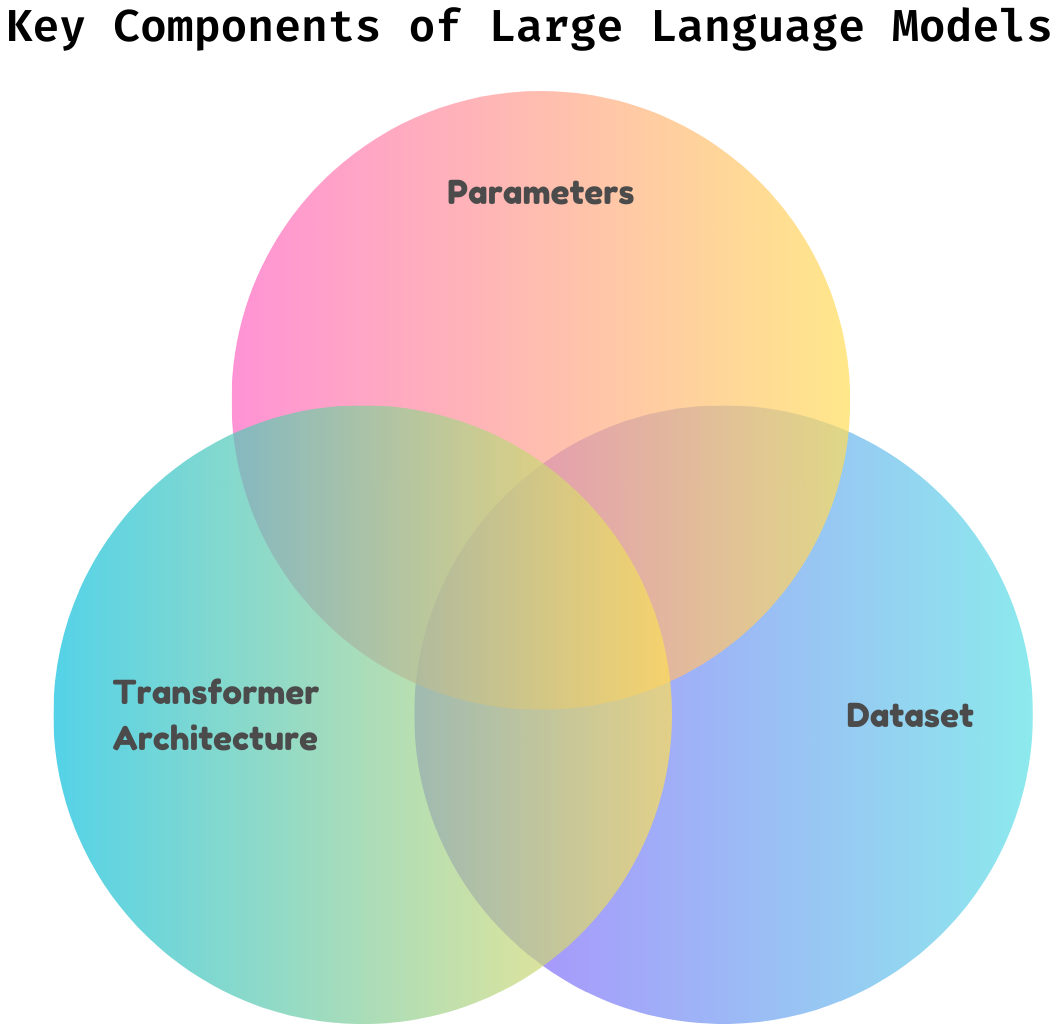
Large Language Models (LLMs) like GPT, BERT, and LLaMA are advanced artificial intelligence systems designed to understand and generate human-like language. Their success is driven by several fundamental components that work together to enable their capabilities. Let’s go through the key components of LLM’s
- Parameters: They are the learnable weights within a neural network that determine how the model processes and transforms input text into output. Parameters are the core knowledge the model acquires during training.
- Dataset: It is the collection of text data used to train the LLM. The quality, diversity, and size of the dataset are crucial for building a powerful language model.
LLMs are trained on massive text datasets, including:
- Wikipedia articles: General knowledge and factual content.
- Books: Rich in literary, formal, and diverse writing styles.
- Scientific Papers: Technical, academic knowledge.
- News Websites: Up-to-date information and journalistic writing.
- Social Media Content: Informal conversations, slang, and modern expressions.
- Transformer Architecture: Introduced in 2017 by Vaswani et al., the Transformer model is the backbone of LLMs. Key components of Transformers include:
- Self-attention Mechanism: Allows the model to focus on important parts of the input.
- Positional Encoding: Helps the model understand the order of words.
- Feedforward Layers: Process the attention output.
Training Large Language Models
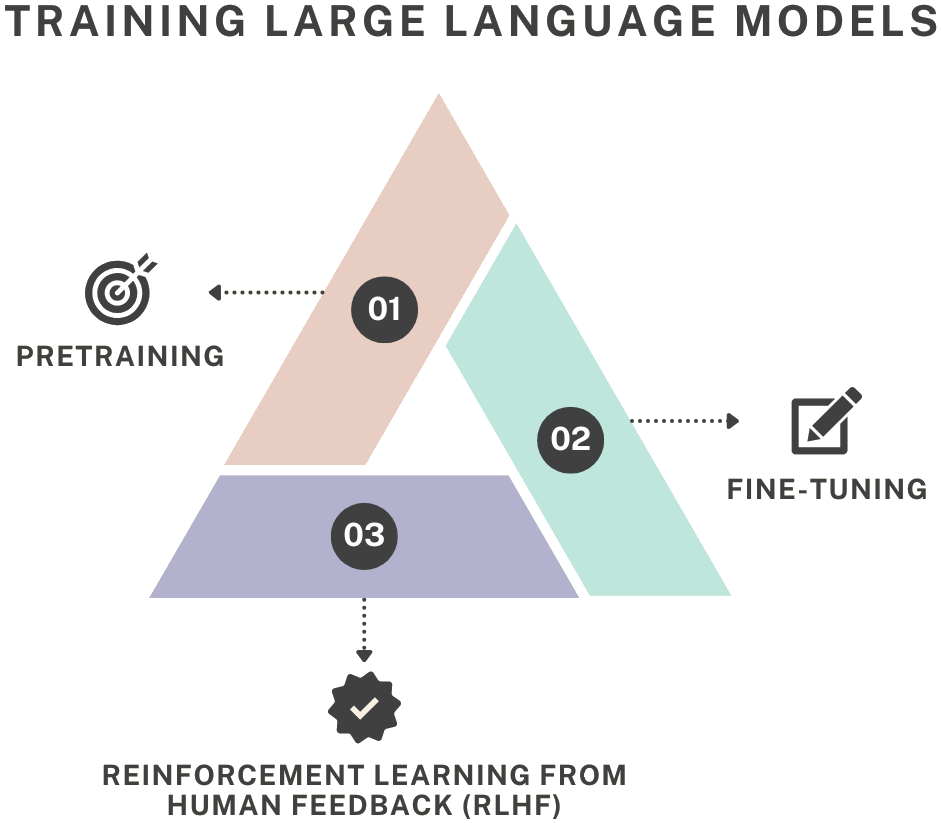
LLMs are trained in a sequential process that first involves inputting petabytesof text data into neural networks. And then fine-tuning the parameters of those networks to minimize prediction errors. By doing so, the model learns to recognize language patterns, grammar, and context. There are three main stages of training LLMs.
Let’s understand each one:
- Pretraining: This is the first step in which an LLM is trained on huge and varied datasets with the help of unsupervised learning. The model learns general language properties, like relationships between words and syntax, and also general patterns in the language. It either predicts the next word or fills in masked words based on context. It is trained on text from sources such as books, Wikipedia, and websites. In this phase, a wide understanding of human language is developed.
- Fine-tuning: Fine-tuning is the second phase, where the pre-trained LLM is trained further on task-specific or domain-specific data using supervised learning. This step helps the model specialize in fields like medicine, law, or customer support by providing labeled examples. It enhances the model’s performance on specific applications, making it more accurate and reliable for particular tasks.
- Reinforcement Learning from Human Feedback (RLHF): It is a modern fine-tuning approach where human evaluators rank the model’s responses based on quality and helpfulness. This feedback is used to train a reward model, which guides the LLM to produce better outputs using reinforcement learning techniques. It makes sure that the model’s responses are more accurate, polite, and aligned with human preferences. RLHF improves safety and user satisfaction in conversational models like ChatGPT.
Applications of LLMs in Real Life
Large Language Models have transformed various industries by enabling machines to understand and generate human-like text. With this feature, LLMs support different businesses and even everyday activities by automating tasks, improving productivity, and improving communication. Let’s see the most notable real-life applications of LLMs.
- Chatbots and Virtual assistants: LLMs enable conversational AI systems like ChatGPT, Google Bard, and Microsoft Copilot to engage in human-like conversations. And also assist users with tasks.
- Content Generation: LLMs automatically create articles, advertisements, social media posts, product descriptions, etc. They are even used for creative writing by businesses and individuals.
- Language Translation: LLMs power translation tools like Google Translate are used for accurate and context-aware translation between multiple languages.
- Sentiment Analysis: Businesses use LLMs to analyze customer reviews and social media comments. It helps in identifying positive, negative, or neutral sentiments.
- Code Generation: LLMs like GitHub Copilot assist developers by suggesting code snippets, completing functions, and improving coding efficiency.
Challenges and Limitations of LLMs
While Large Language Models (LLMs) have shown remarkable capabilities, they also face several challenges and limitations. These issues can affect their accuracy, reliability, fairness, and safety. And so, it is crucial to understand their shortcomings when using them in real-world applications.
- Bias in Training Data: LLMs are trained on data scraped from the internet. And when they are aggregated, it can comprise biased or prejudicial content. As a result, they can reinforce negative stereotypes and generate biased results. This poses ethical problems, particularly in sensitive fields like hiring, law or healthcare, where LLMs are used.
- Misinformation and Hallucinations: LLMs can generate false or misleading information. This phenomenon is known as hallucination. They sometimes present inaccurate facts with confidence, which can mislead users and cause harm, especially in domains requiring factual precision like medicine or law. Verifying the model’s output is often necessary but can be time-consuming.
- High Computational Costs: The training and deployment of such LLMs are computationally expensive, requiring high-performance GPUs in tandem with large quantities of electricity.
| Advantages | Limitations |
|---|---|
| Human-like Text Generation: LLMs produce fluent and coherent text, enabling natural conversations and content creation. | Bias and Ethical Concerns: LLMs can reflect biases from their training data, leading to unfair or offensive outputs. |
| Versatile Applications: Useful for tasks like chatbots, content creation, translation, coding, and summarization. | Hallucinations and Misinformation: LLMs can generate false or misleading information with confidence. |
| Improved Productivity: Assists professionals by automating repetitive writing, coding, and data processing tasks. | High Computational Costs: Training and deploying large models require expensive hardware and energy resources. |
| Language Understanding: Advanced models can understand complex queries and contexts across multiple languages. | Lack of True Understanding: LLMs lack genuine reasoning and comprehension; they predict based on patterns. |
| Customization Potential: LLMs can be fine-tuned for specific industries like law, healthcare, and finance. | Limited Explainability: The inner workings of LLMs are often opaque, making it hard to explain their outputs. |
| Accessibility: Pretrained models like ChatGPT and open-source LLaMA provide easy access to powerful AI tools. | Data Privacy Risks: Using LLMs with sensitive information can raise privacy and security concerns. |
Popular Large Language Models
Large Language Models (LLMs) are developed by various organizations to understand, process, and generate human-like text. Some of the most notable LLMs include GPT, BERT, and LLaMA, each with unique features and purposes.
GPT (Generative Pre-trained Transformer) Series
The GPT series, developed by OpenAI, is known for generating high-quality, human-like text based on prompts.
- GPT-3 (2020) introduced 175 billion parameters, making it one of the largest and most capable models of its time.
- GPT-4 (2023) is a multimodal model that can process both text and images, expanding its capabilities beyond pure text understanding.
BERT (Bidirectional Encoder Representations from Transformers)
BERT, developed by Google in 2018, is designed for natural language understanding tasks like question answering and sentiment analysis.
Unlike GPT, BERT reads the context from both the left and right sides of a word simultaneously (bidirectional approach), allowing it to understand the meaning of words in context better. It is widely used in search engines, including Google Search, to improve search result accuracy.
LLaMA (Large Language Model Meta AI)
LLaMA, developed by Meta (formerly Facebook), is an open-source LLM primarily designed for research purposes. It is optimized for efficiency, offering high performance with fewer parameters compared to GPT models, making it accessible to researchers and smaller organizations.
LLaMA’s open-source nature allows developers to customize and fine-tune the model, promoting transparency and innovation in the AI community.
The Future of Large Language Models
Large Language Models (LLMs) are rapidly evolving, with future developments aimed at expanding their capabilities and improving efficiency. Advancements are expected to make LLMs more versatile, specialized, and accessible, driving their adoption across various industries.
- Multimodal Models: Future LLMs will process text, images, audio, and perhaps video as well. This allows for more sophisticated haptic learning and understanding of different types of data, thus leading to more interactive/capable AIs. These models can now analyze visual content, understand speech, and generate richer outputs, all of which can be used in the real world.
- Domain-Specific Models: More specialized LLMs, based on domains (like science, law, or finance), will produce much more accurate results for that field than a GPT-4 or Claude could. These models will be trained on data of a similar expertise-level, designed to assist professionals with conducting research, documentation, or making decisions.
- Efficiency Improvements: New approaches are being created that are designed to cut down how much computation it takes to get an LLM running and make them faster and more effective. By opening access to advanced AI models, smaller businesses and researchers can take advantage of powerful language models.
Additional Resources
- AI Assistants vs AI Agents: How to Test?
- What is AIOps?
- How to Test Prompt Injections?
- How To Test for SQL Injections – 2025 Guide
- Machine Learning Models Testing Strategies
- AI Engineer: The Skills and Qualifications Needed
- Top 10 OWASP for LLMs: How to Test?
- AI Features Testing: A Comprehensive Guide to Automation
Conclusion
LLMs have entirely changed how machines process and interact with human language. Their capabilities to comprehend and generate natural language have opened new avenues for AI-enabled applications. Now, though LLMs can have many pros, they also bring many ethical, computational, and reliability issues. For now, LLMs are a research tool with a potential future of higher-grade AI systems that help facilitate interactive human-computer communication.
Understanding LLMs is a technical necessity for a glimpse into the future of human-AI collaboration.
| Achieve More Than 90% Test Automation | |
| Step by Step Walkthroughs and Help | |
| 14 Day Free Trial, Cancel Anytime |









