What is Chaos Engineering? Breaking Systems to Build Resilience
|
|
Software systems today are complex, interconnected, and distributed. They range from cloud-native microservices to massive-scale web platforms and serve billions of users every day, and are expected to perform reliably under diverse conditions. However, despite rigorous testing and assurance of good performance, failures still occur due to network outages, software bugs, hardware failures, or unexpected user behavior.
These failures, which cause costly outages for companies, are much harder to predict. They hurt customers trying to shop, transact business, and get work done. This is where Chaos Engineering comes into play.
| Key Takeaways: |
|---|
|
This article on chaos engineering explores the concept in detail, as well as its principles, methodologies, tools, benefits, and challenges. The article also provides various real-time examples that use chaos engineering to test their systems.
Chaos Engineering: Definition
Chaos engineering is a disciplined approach to identifying failures in software systems before they turn into outages.

The system is proactively tested in chaos engineering to see how it behaves under stress. The failures are identified and fixed before they end up in production. Chaos engineering is often misunderstood as reckless system breaking. In reality, it is a scientific and controlled approach to testing failures. It is performed to build confidence in the system’s capability to withstand turbulent conditions in production.
In other words, in chaos engineering, things are literally “broken on purpose” to learn how to build more resilient systems.
Three key elements that stand out in chaos engineering definitions are:
- Experimentation: Chaos Engineering does not destroy systems randomly. It follows a hypothesis-driven approach, where experiments are carried out in a controlled manner to test assumptions.
- Building Confidence: The goal of chaos engineering is not to break the system but to strengthen it by identifying hidden weaknesses before they cause major outages.
- Production Context: The most valuable insights are obtained from production environments, where real-world traffic and dependencies exist.
By introducing chaos in the system, failures are identified. Developers then start mitigating them. Developers use solutions such as OpenText Professional Performance Engineering, OpenText Enterprise Performance Engineering, or OpenText Core Performance Engineering to introduce chaos engineering into their workflows. These solutions make it easy to run other chaos engineering experiments directly within the software.
Chaos Engineering Principles
The following are the core principles of chaos engineering to ensure effective and safe experiments.
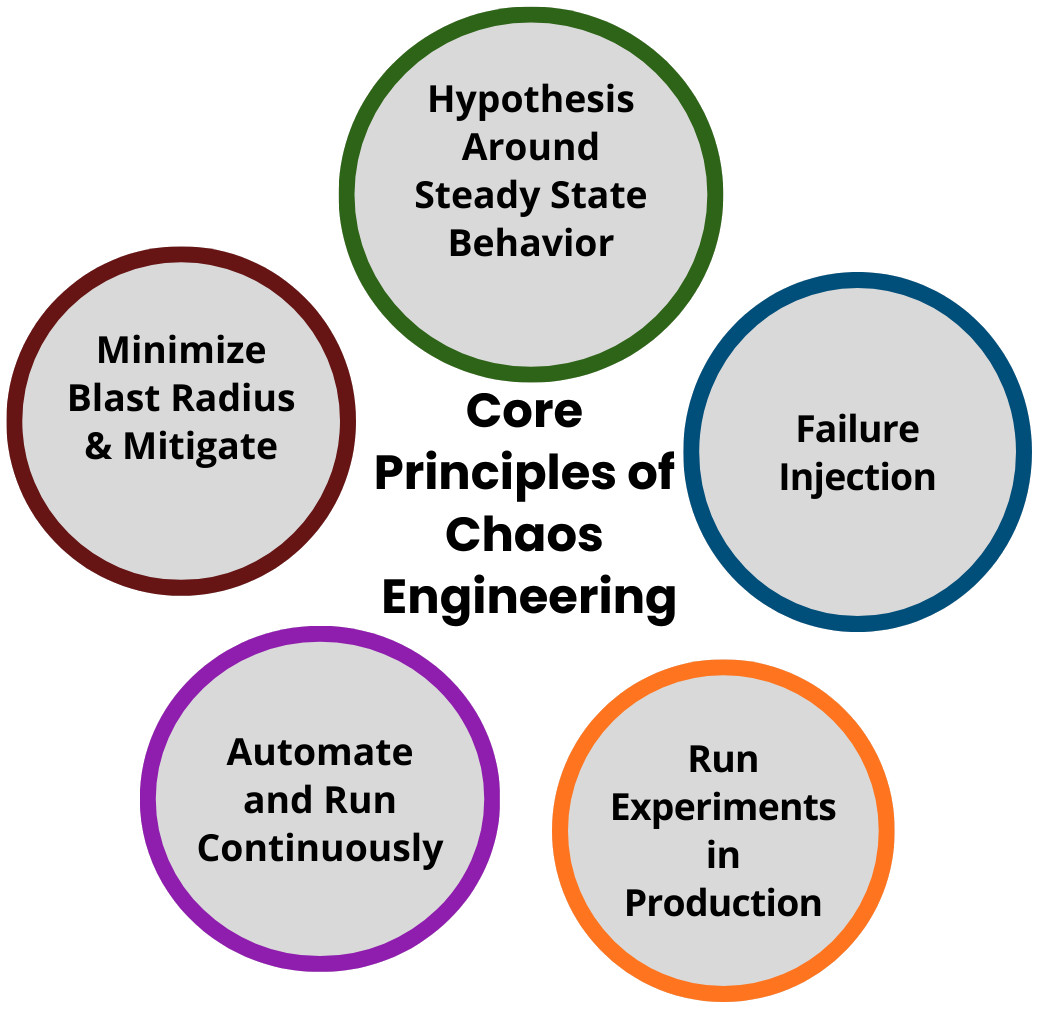
1. Hypothesis Around Steady State Behavior
Chaos engineering starts with hypothesizing how a system should behave under certain failure conditions.
The chaos experiments begin with the assumption that “the system will continue operating within acceptable parameters even if component X fails.” Based on this assumption, the chaos experiments are designed to test what could go wrong in the system. What potential vulnerabilities can be exploited?
2. Failure Injection
Chaos engineering introduces real-world failure modes such as network latency, server crashes, infrastructure malfunction, application failures, or disk exhaustion. Failures are intentionally injected into the system to test how it withstands these failures.
3. Run Experiments in Production
Experiments for chaos engineering are primarily conducted in production environments as they provide the most accurate results. Experiments start small to mitigate risks, with strict monitoring and automated rollbacks. Various failure scenarios, such as server crashes, network latency, or database failures, are simulated in a controlled environment to validate or invalidate the hypothesis and identify weaknesses in the system.
4. Automate and Run Continuously
Chaos experiments are repeatable and often automated to ensure consistency and continuity. It ensures that resilience is maintained as systems evolve,
Data from these experiments is used to identify potential failure points as developers closely monitor the system throughout the experiment.
Data collected involves metrics, logs, and other relevant data to analyze how the system responds to failure conditions.
5. Minimize Blast Radius & Mitigate
Experiments begin with small, controlled failures (minimum blast radius) to avoid large-scale outages. If an issue is identified, the experiment is ended, and developers work on mitigating the risk. If the experiment is successful, it is scaled further.
Methodology of Chaos Engineering
Chaos engineering is implemented using a structured methodology outlined below:
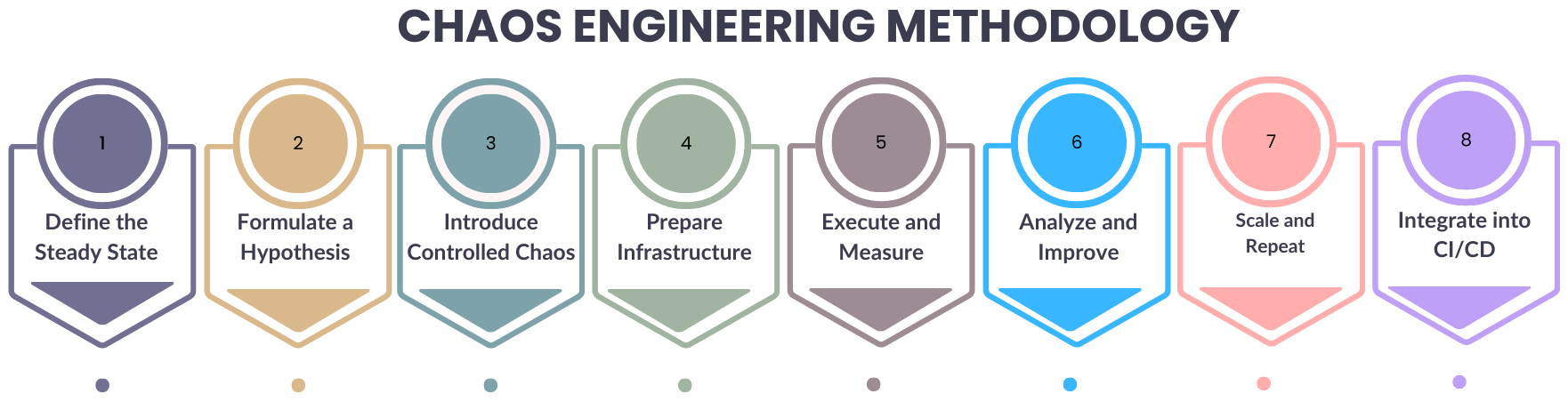
Step 1: Define the Steady State
Clearly define the objectives of the chaos engineering initiative and identify key performance indicators (KPIs) that represent system health (e.g., availability, response times, error rates). Determine various aspects of the system, such as resilience, scalability, and fault tolerance, that you want to test and improve.
Step 2: Formulate a Hypothesis
Develop hypotheses that define the system’s behavior under various failure conditions. The hypotheses serve as the basis of chaos experiments.
An example of hypothesis testing is that the system will reroute queries and maintain acceptable performance if one database node is shut down.
Step 3: Introduce Controlled Chaos
Design controlled experiments to simulate various failure scenarios once the hypothesis is formulated. Decide how to inject failure into the system, which metrics to monitor during the experiment, and design which failure modes to test. Consider the impact of experiments on users and business operations.
Step 4: Prepare Infrastructure
Prepare required infrastructure and tools for chaos experiments. This will involve setting up testing environments, deploying monitoring systems, and configuring automation scripts for failure injection.
Step 5: Execute and Measure
Execute the planned chaos experiments in a controlled manner. Closely monitor the metrics during the experiment to see whether the hypothesis holds. Collect relevant data like metrics, logs, and observations during the experiment.
Step 6: Analyze and Improve
Analyze the experiment results to verify the hypothesis. If the system fails to handle the disruption, document the findings and implement resilience improvements.
Step 7: Scale and Repeat
If the experiment succeeds, it should be expanded over time to cover more failure types, components, and scenarios. Additionally, more experiments should be conducted to validate the effectiveness of these improvements.
Step 8: Integrate into Continuous Improvement
Finally, chaos engineering should be integrated into continuous improvement processes and the development, testing, and deployment pipelines to continuously validate and improve the system’s resilience.
Common Chaos Engineering Experiments
The following table lists some of the most frequent chaos experiments:
| Failures | Experiments Performed |
|---|---|
| Infrastructure Failures |
|
| Network Faults |
|
| Application-Level Failures |
|
| Dependency Failures |
|
| Security Chaos (emerging practice) |
|
Chaos Engineering Tools
Various tools and technologies support chaos engineering practices. These tools help engineers conduct controlled experiments, simulate failure scenarios, and analyze system behavior. Some of these tools used in chaos engineering include:
- Chaos Monkey: Netflix developed this tool to terminate instances in the production environment randomly. It is a popular open-source tool that helps teams test their systems’ resilience to instance failures in cloud-based architectures.
- Gremlin: This commercial chaos engineering platform offers a wide range of failure injection capabilities. It supports injecting various failure modes across different cloud providers and infrastructure components, such as CPU spikes, network partitioning, and blackhole attacks.
- Chaos Toolkit: It is an open-source, extensible framework for designing, running, and analyzing chaos experiments. Experiments can be defined and chaos orchestrated across different infrastructure and services using a command-line interface and Python-based DSL (Domain-Specific Language).
- Chaos Mesh: It is an open-source chaos engineering platform from the CNCF (Cloud Native Computing Foundation) that enables engineers to conduct chaos experiments in Kubernetes environments by injecting faults into pods, containers, networks, and other Kubernetes resources. Read: What are Docker and Kubernetes and why do I need them?
- Pumba: It is an open-source chaos engineering tool designed explicitly for Docker containers. Users can use it to introduce chaos actions, such as network delays, packet loss, and container restarts, to simulate real-world failures and test containerized applications’ resilience.
- LitmusChaos: This is a Kubernetes-native chaos engineering tool. It can run chaos experiments initially in the staging environment and eventually in production to find bugs and vulnerabilities.
- AWS Fault Injection Simulator (FIS): It is a cloud-native service for chaos testing in AWS environments. It is a managed service that enables you to perform fault injection experiments on your AWS workloads.
Benefits of Chaos Engineering
Here are the key benefits of chaos engineering:
- Improved System Resilience: As weak points are proactively identified, organizations build self-healing and fault-tolerant architectures.
- Reduced Downtime and Outage Costs: Chaos engineering helps minimize outages and downtime. It enables organizations to create a more informed blueprint for tackling future issues.
- Better Incident Response: As teams practice responding to simulated failures, they improve their readiness during real incidents and provide a better response.
- Cultural Transformation: Chaos engineering encourages teams to view failures as learning opportunities rather than finger-pointing events.
- Customer Confidence: End-users enjoy more reliable services, enhancing trust and brand loyalty.
- Increased Scalability: Chaos engineering experiments identify how a system allocates resources. Introducing chaos experiments demonstrates how the system handles loads, showing the weak points and the bottlenecks that are likely to occur.
- Improved Data Security: Disruptions can come from any source, such as bad code, server issues, or external threats. Chaos engineering helps identify exploitable issues so organizations can introduce patches and bug fixes to keep their services secure.
Challenges and Risks
While chaos engineering offers various benefits, it is not without challenges:
- Cultural Resistance: Stakeholders might resist the adoption of chaos engineering because they fear deliberately breaking systems, especially in production. Overcoming cultural barriers and encouraging experimentation and resilience may require organizational buy-in, education, and change management efforts.
- Risk of Customer Impact: Poorly designed chaos experiments can cause real downtime and thus risk losing customers.
- Complexity: Implementing chaos engineering in distributed systems can be challenging. These systems are inherently difficult to test due to their complex system architecture, dependencies, and interactions between components.
- Tooling Costs: Though many open-source tools exist that support chaos engineering, using commercial solutions may be expensive.
- Measurement Difficulties: Defining and effectively measuring the steady state is often challenging. Teams need sophisticated monitoring and analysis tools for collecting relevant metrics, logs, observations, and interpreting experiment results.
- Resource-Intensive: Chaos experiments require significant resources like time, infrastructure, and personnel. Other tasks, such as creating realistic testing environments, setting up monitoring systems, and analyzing experiment results, are also resource-intensive, especially for large-scale or mission-critical systems.
- Safety Concerns: Injecting chaos into production environments carries risks like potential service disruptions, data loss, and negative impact on users.
Real-World Examples
Below are a few examples of chaos engineering in the real world:
- Netflix: Hailed as the pioneer in chaos engineering. Netflix uses Chaos Monkey and the broader Simian Army (a suite of tools simulating various failures) to ensure its streaming service remains reliable across global infrastructure.
- Amazon: AWS (Amazon Web Services) uses the Fault Injection Simulator to help customers test system resilience in cloud environments.
- Google: Practices large-scale resilience testing through DiRT (Disaster Recovery Testing) exercises. All the data centers are shut down to validate disaster recovery procedures.
- Financial Sector: Banks and fintech companies use chaos engineering to validate high-availability systems that must remain operational under extreme conditions.
Best Practices for Adopting Chaos Engineering
Teams should follow the best practices below for adopting chaos engineering:
- Start Small: Start with low-risk experiments in staging or on non-critical services before going full-scale.
- Automate Monitoring: Use automated monitoring tools to ensure real-time observability of metrics.
- Use Feature Flags: These help to roll back experiments instantly if something goes wrong.
- Communicate Clearly: All stakeholders must be informed before running experiments.
- Integrate with CI/CD: Make chaos tests part of development, testing, and deployment pipelines.
- Iterate and Expand: Slowly scale up the scope of experiments.
The Future of Chaos Engineering
Chaos Engineering continues to evolve, with emerging trends such as:
- Security Chaos Engineering: Chaos principles are being extended to security testing.
- AI-Driven Chaos Experiments: Machine learning predicts failure scenarios and automates experiment design.
- Regulatory Adoption: Critical sectors like finance and healthcare may mandate resilience testing.
- Wider Enterprise Adoption: More organizations beyond tech companies will adopt chaos engineering as tools and technologies supporting chaos engineering emerge.
- Integration with SRE Practices: Chaos Engineering complements Site Reliability Engineering (SRE), focusing on resilience and reliability.
Conclusion
Chaos engineering can be seen as a paradigm shift in how software reliability is perceived. Organizations embrace failures as opportunities to learn and strengthen their systems with chaos engineering instead of fearing them. By systematically introducing chaos in a controlled manner, organizations can identify hidden weaknesses, reduce downtime, improve resilience, and encourage a culture of continuous improvement.
Chaos engineering is set to play a pivotal role in ensuring that digital infrastructure remains reliable, robust, and capable of serving billions of users worldwide in distributed environments.
| Achieve More Than 90% Test Automation | |
| Step by Step Walkthroughs and Help | |
| 14 Day Free Trial, Cancel Anytime |









