RAG vs. Agentic RAG vs. MCP: Key Differences Explained
|
|
Large Language Models (LLMs) have drastically changed the way software systems process information, produce responses, and aid humans in making decisions. But for all their wizardry at reasoning and natural language, LLMs have a fundamental limitation; They do not intrinsically “understand” your data.
All those techniques, including RAG, Agentic-RAG, and Model Context Protocol, are there to address a single, core problem: How do we safely, reliably, and intelligently connect LLMs to real, external, constantly changing knowledge?
At first sight, these three ideas seem to be similar. All of them are based on “feeding context” into AI models. But architecturally, philosophically, and operationally, they are three stages of AI system design that really could not be more different from one another.
| Key Takeaways: |
|---|
|
Why LLMs Need External Knowledge
Before we compare solutions, it is important that we have a clear understanding of the problem at hand. LLMs are modeled on static data and thus lack runtime intelligence about the news, organization or fast-changing facts, leading to outdated, incomplete or overly generic responses when precise current or domain-specific knowledge is required.
Read: What are LLMs (Large Language Models)?
The Knowledge Boundary of LLMs
LLMs are trained on static snapshots of data and do not have access to a real-time system unless connected to it. When in doubt, they hallucinate with confidence and don’t have an independent means of checking the objective truth value of their performance. It is not related to the context outside of a window, and they cannot recall or think over large datasets.
Even the most advanced model is blind to your internal documents and unaware of your APIs unless they are explicitly integrated. It remains ignorant of recent updates because its knowledge is not continuously refreshed in real time. By default, it is also incapable of dynamically querying systems or validating information on its own.
As soon as companies attempted to utilize LLMs in enterprise Q&A, code intelligence, QA analysis, incident investigation, compliance reasoning, and decision support, they encountered serious limitations. Prompting was not sufficient in bridging generic model knowledge and current organization-specific information that could be confirmed. This fact made it clear that LLMs were dependent on external data and systems to be really useful in concrete enterprise scenarios.
Retrieval-Augmented Generation (RAG)
RAG (Retrieval-Augmented Generation) was introduced to fill the gap between powerful language models and the actual dynamic knowledge that enterprises depend on every day. To truly know its worth and the extent of its powerlessness, we need to see through marketing claims and examine RAG for what it actually is: an architectural abstraction.
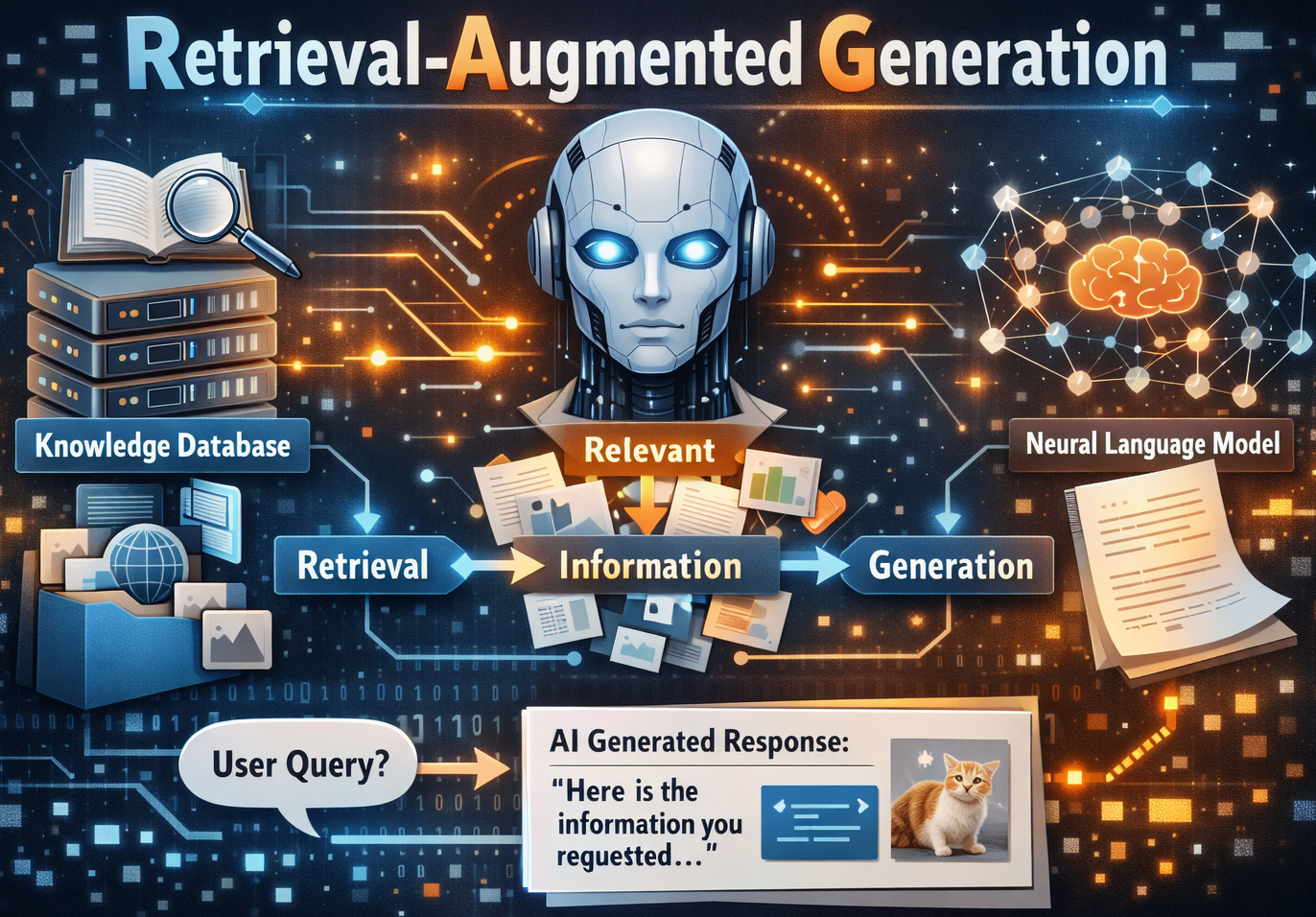
What RAG Actually is
Retrieval-Augmented Generation (RAG), an architectural paradigm in which the retrieval of documents from an external knowledge source is sparked by a user’s query. This extracted content is then injected into the LLM prompt to enable the model to generate an answer based on its training data and available context. In other words,
RAG = LLM + Search + Prompt Injection, essentially lacking reasoning or memory or any kind of autonomy.
Why RAG Emerged
RAG was proposed to address three fundamental limitations of vanilla LLM usage: hallucinations, stale knowledge, and not being domain-specific. By anchoring model responses relative to retrieved external evidence, the approach substantially mitigates guessing and overconfidence. As the outcome, RAG significantly boosts factual correctness, domain fidelity, and reliability.
Read: Retrieval Augmented Generation (RAG) vs. AI Agents.
Typical RAG Architecture
- Document Store: Holds source content such as PDFs, wikis, tickets, and logs that serve as the knowledge base.
- Chunking Strategy: Splits large documents into smaller, manageable pieces suitable for embedding and retrieval.
- Embedding Model: Converts text chunks into numerical vectors that capture semantic meaning.
- Vector Database: Stores embeddings and enables fast similarity-based searches.
- Retriever: Selects the most relevant chunks based on the user query and embedding similarity.
- Prompt Assembler: Injects the retrieved content into a structured prompt for the model.
- LLM: Generates the final response using its training data combined with the injected context.
The overall flow is linear and deterministic, with each step executed once in a fixed sequence.
Strengths and Weaknesses of RAG
RAG is widely adopted because it offers a simple and reliable way to ground LLM responses in external knowledge. However, beneath this simplicity lie structural limitations that become evident as use cases grow more complex.
| Advantages of RAG | Disadvantages of RAG |
|---|---|
| Conceptually simple and easy to understand | Lacks reasoning about what or why to retrieve |
| Relatively easy to implement and maintain | Retrieval is similarity-based, not intent-driven |
| Cost-efficient compared to agentic systems | Cannot ask follow-up questions or refine retrieval |
| Transparent and deterministic behavior | Single-shot context with no ability to request more information |
| Predictable outputs due to a fixed pipeline | Cannot verify answers or backtrack when wrong |
| Works well for document-based Q&A and search | Highly sensitive to chunk size and retrieval ranking |
| Effective for support bots and internal docs | Fragile prompts where small changes impact results |
| Suitable for static knowledge bases | No memory, planning, or self-reflection capabilities |
Agentic RAG: When Retrieval Becomes Intentional
Agentic RAG is the next generation of retrieval-augmented systems, in which retrieval is motivated by intent rather than a fixed pipeline. That is not just about one-shot context injections, though, but AI systems that can think and adapt for themselves.
Why Agentic RAG Exists
Even as teams tried to create more advanced AI, they rapidly reached a limit with standard RAG. They wanted systems that could decide what and when to retrieve without stacking multiple retrievals, use tools, reflect on their own answers, and retry when they weren’t sure. This active role of decision-making and adaptive retrieval is what immediately gave rise to Agentic RAG.
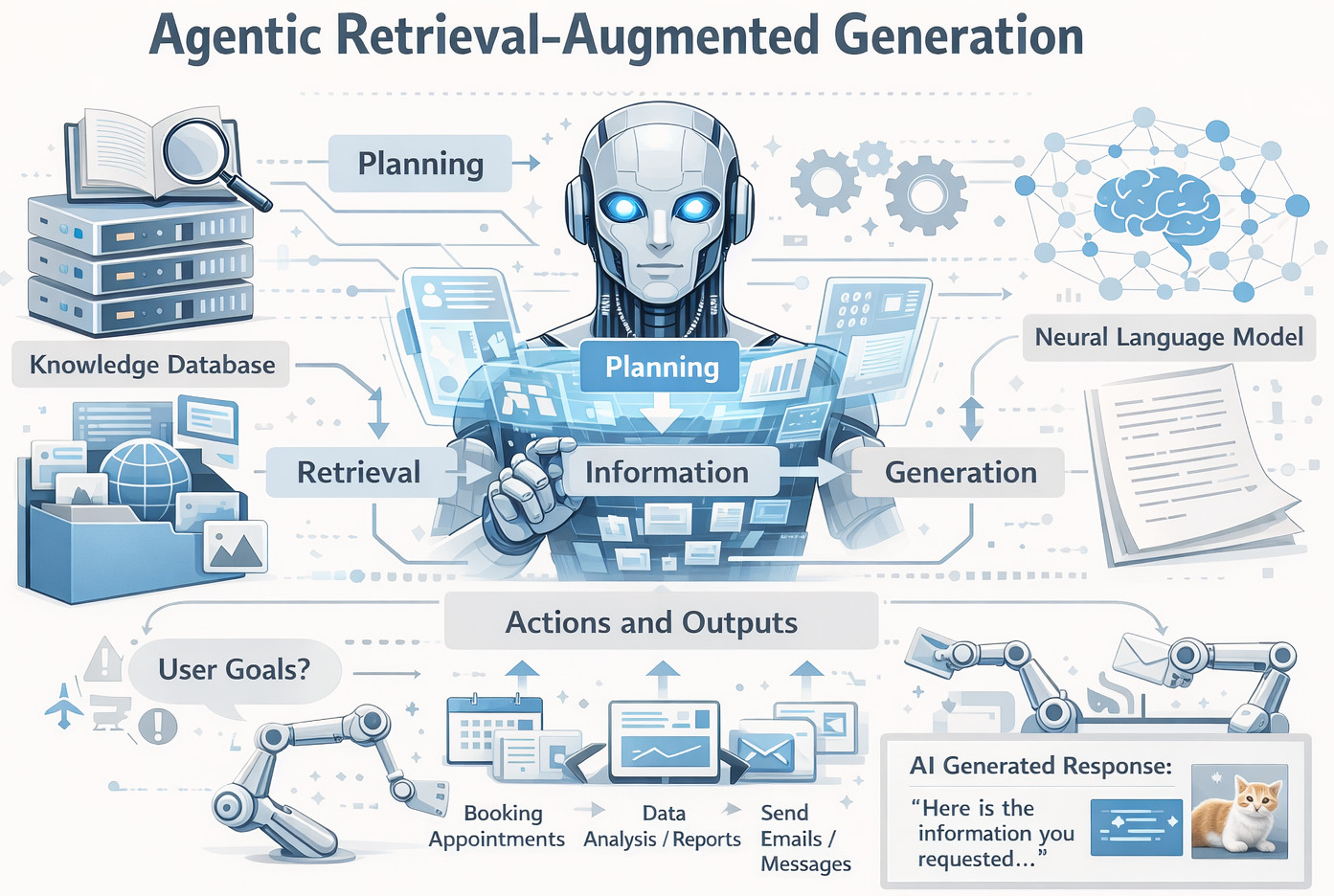
What is Agentic RAG?
Agentic RAG is an extension of classic RAG by introducing autonomy and reasoning to the retrieval. It doesn’t use a single “retrieve once, answer once” flow, but rather follows an iterative loop of thinking, retrieving, considering, and retrieving again until it gets to a confident conclusion. In this manner, the LLM behaves as a proactive agent seeking ahead, choosing its devices, seeking advice, and thinking about results so that it iterates towards improvement.
Read: Different Evals for Agentic AI: Methods, Metrics & Best Practices.
Core Components of Agentic RAG
- Planner or Reasoning Loop: Defines the order in which the agent will act, considering the goal and intermediate results.
- Multiple Tools: Allow the agent to be able to collect information, make an api call, do math or interact with databases when necessary.
- Memory Layer: It stores past interactions and decisions as an intermediate result to make them consistent across steps.
- Decision Logic: Determines the next action or tool, and retrieval strategy based on its current context of operation.
- Retry and Evaluation Mechanisms: Determine the quality of an answer, trigger re-retrieval or alternative reasons if low confidence.
Difference Between Agentic RAG and Regular RAG
Standard RAG and Agentic RAG may sound similar, but they represent fundamentally different approaches to how AI systems retrieve and reason over information. Understanding these differences is critical to choosing the right architecture for complex, real-world use cases.
| Dimension | Standard RAG | Agentic RAG |
|---|---|---|
| Retrieval | Single, one-time retrieval based on similarity search | Iterative retrieval where the agent can refine queries and fetch additional context as needed |
| Control | System-driven flow with a fixed pipeline | Model-driven flow where the LLM decides the next action |
| Reasoning | Implicit and limited to prompt interpretation | Explicit reasoning loop that plans, evaluates, and adapts |
| Tool Usage | Static and predefined at design time | Dynamic selection and chaining of tools at runtime |
| Error Recovery | No built-in recovery; incorrect answers pass through | Built-in evaluation and retry mechanisms |
| Memory | No memory beyond the prompt context | Optional memory to retain intermediate state and past insights |
This makes Agentic RAG fundamentally more adaptive, resilient, and capable of handling complex, real-world tasks.
Advantages and Limitations of Agentic RAG
Agentic RAG significantly expands what retrieval-augmented systems can do by introducing reasoning, autonomy, and adaptability. However, these gains come with important trade-offs that teams must understand before adopting this approach.
| Advantages of Agentic RAG | Limitations of Agentic RAG |
|---|---|
| Enables multi-step and iterative reasoning | Introduces significant architectural complexity |
| Supports conditional and dynamic retrieval | Higher latency due to multiple reasoning steps |
| Allows intelligent tool selection and chaining | Harder to debug when failures occur |
| Can evaluate and self-correct responses | Self-evaluation is imperfect and can still fail |
| Expands context progressively as needed | Risk of over-retrieval and unnecessary exploration |
| Well-suited for complex investigations and analysis | Often excessive for simple or deterministic use cases |
| Powers AI copilots and autonomous assistants | Less predictable behavior and possible intent drift |
MCP (Model Context Protocol): A Structural Shift
MCP (Model Context Protocol) is a radical break from existing paradigms of how large-scale language models can be interfaced with external knowledge and systems. Rather than piling retrieval machinery atop models, MCP redoes context itself as a solid, utilitarian base for cognition.
Read: What is Model Context Protocol (MCP)?
Why MCP is Fundamentally Different
RAG and Agentic RAG both view the context as being fetched and injected on demand. MCP, however, presents the notion of context as a first-class infra level on top of which models have reliable access and agility to reason over. This abstraction from ‘context as payload’ to ‘context as infrastructure’ is single-handedly the most valuable distinction in this whole article, and radically shifts how AI systems are conceived.
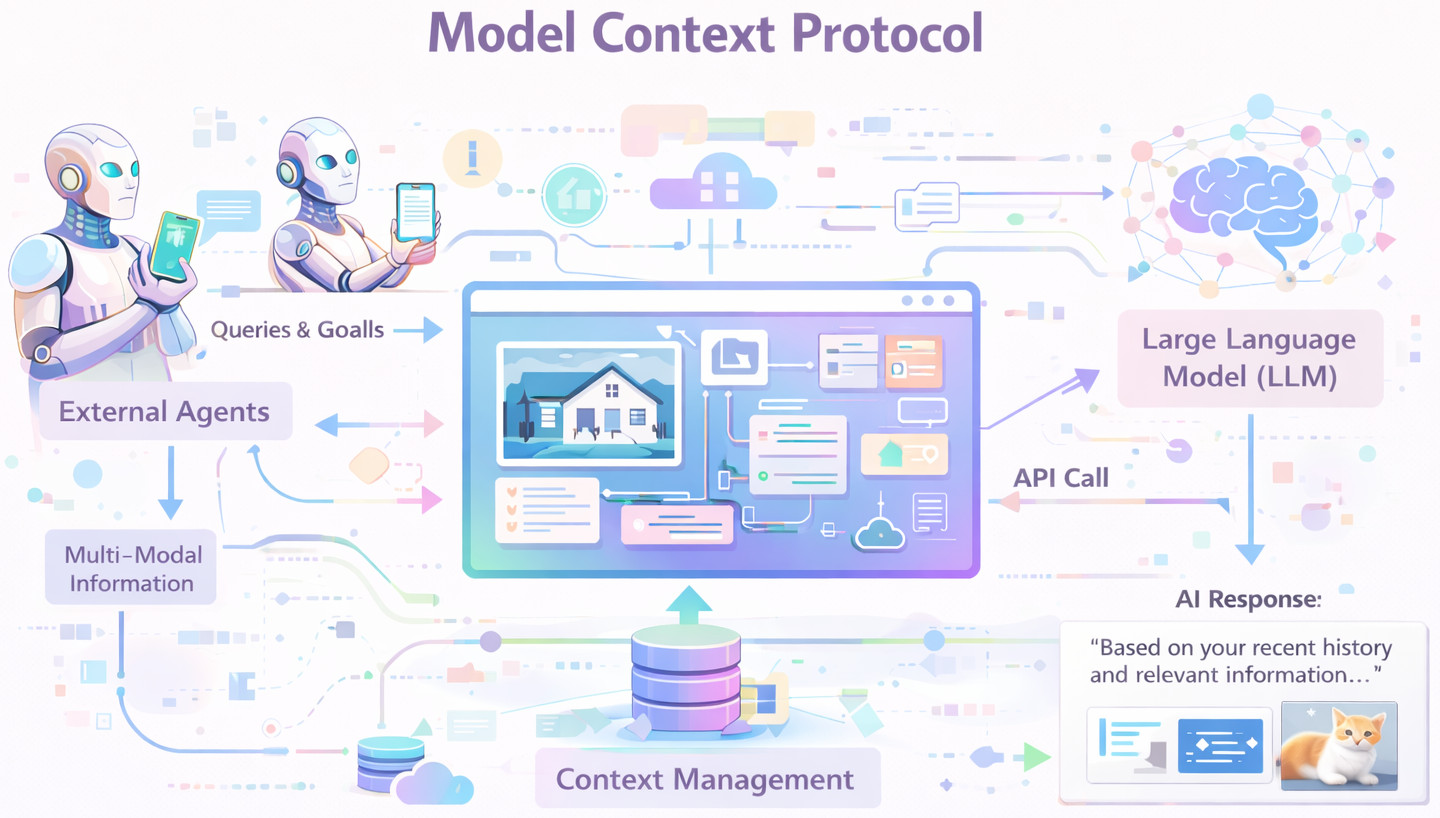
What is MCP?
Model Context Protocol (MCP) is a well-defined protocol comprising an interface to ensure that accesses and usage of external context from the model will be constant and secure. It defines how tools expose data, how permissions are applied and enforced, how context is accessed dynamically, and models that can interface with systems without resorting to brittle prompt injection or ad-hoc integrations.
MCP isn’t a retrieval mechanism, prompting method, or agent architecture built on top of a model. Rather, it is a protocol layer which mediates the flow of context that provides models with structured, reliable, and regulated context or in coder’s words: It gives AI applications inbound.
The Core Idea Behind MCP
The fundamental idea of MCP is that one would like to avoid having to stuff gigantic amounts of data into prompts. Rather, MCP enables models to ask for the specific context they want when they want it via structured and governed interfaces. This change displaces how models connect to systems, data, and understanding.
MCP vs. Prompt Injection
In RAG, context is indiscriminately injected into the prompt without any guarantees about its sufficiency or relevance. The model cannot ask for more data, process what it receives, and then double-check that this was the data from where you think it comes. Thus, the quality of the response is strongly dependent on prompt generation and retrieval correctness.
Read: Prompt Engineering in QA and Software Testing.
In MCP, models explicitly request context information through clear interfaces instead of passive prompt injection. Systems define what data can be accessed, permissions are enforced, and the responses are strongly typed structures of information, not just raw text. This results in a controlled, testable, and much more reliable way of the models interacting with other systems.
MCP Architecture
- MCP Servers: Expose tools and data through standardized, structured interfaces.
- Context Providers: Supply relevant information dynamically based on model-initiated requests.
- Permission Boundaries: Enforce access control and ensure models only see authorized data.
- Structured Schemas: Define typed, predictable data formats instead of unstructured text.
- Model-initiated Requests: Allow the model to actively request context rather than receive injected prompts.
Why MCP is a Paradigm Shift
MCP achieves a nice separation of concerns by specifying explicit contracts between models and systems, strong security boundaries, and governance. This design allows for reusability of context access, as well as making it auditable and easier to evolve without breaking other people’s applications. In this way, MCP makes context management something more than ad-hoc prompt logic: A solid engineering layer.
This paradigm shift is comparable to how HTTP standardized web communications, SQL established database access, and APIs have enabled transactions to be standardized between services. Each of these abstractions abolished brittle, bespoke interfaces in favor of reasonable and interoperable ones. MCP uses the same logic for AI models interacting with tools and data.
RAG vs. Agentic RAG vs. MCP: Architectural Comparison
Although RAG, Agentic RAG and MCP are usually mentioned together but they share a fundamentally different architectural view. It is important to comprehend how each of these schemes handles the concepts of context, intelligence, and control for building scalable and dependable AI systems.
| Aspect | RAG | Agentic RAG | MCP |
|---|---|---|---|
| Context Delivery | Context is injected directly into the prompt in a single step | Context is retrieved iteratively through agent-driven decisions | Context is explicitly requested through a standardized protocol |
| Intelligence Location | Minimal intelligence, mostly prompt-driven | High intelligence embedded in agent reasoning loops | Intelligence is delegated to system design and infrastructure |
| Governance | Weak governance with limited control over data exposure | Weak to moderate governance, depending on agent design | Strong governance is enforced through protocol rules and permissions |
| Security Model | Prompt-based and fragile | Tool-based with partial isolation | Protocol-based with explicit access boundaries |
| Scalability | Limited as context size and complexity grow | Complex and costly to scale due to orchestration overhead | High scalability due to standardized, reusable interfaces |
| Debuggability | High due to linear, deterministic flow | Low due to non-linear agent behavior | High due to clear contracts and structured interactions |
- RAG: “Here’s everything I found: answer now.”
- Agentic RAG: “Let me think about what I need, then answer.”
- MCP: “Let me ask the system for exactly what I’m allowed to know.”
Choosing the Right Architecture
Depending on the depth of the problem, governance requirements, and planned scalability, it should be the one. The table given above summarizes when RAG, Agentic RAG or MCP is the most suitable.
| Approach | When to Use It | Typical Examples |
|---|---|---|
| RAG | Data is static, queries are simple, accuracy matters more than reasoning, and cost and simplicity are priorities | Internal FAQ bots, documentation assistants, knowledge portals |
| Agentic RAG | Problems require multi-step reasoning, context is distributed, exploration is required, and you accept added complexity | Incident analysis, AI copilots, investigative assistants, and QA root-cause analysis |
| MCP | Strong governance is required, security and permissions matter, multiple tools and systems are involved, and long-term scalability is a goal | Enterprise AI platforms, regulated environments, developer tooling, and autonomous systems at scale |
The Evolutionary Path
RAG, Agentic RAG, and MCP are not conflicting ideas so much as competing stages of AI development. RAG adds grounding, Agentic RAG adds autonomy, and MCP provides the structure and governance necessary for scale and reliability.
Most mature AI systems will eventually use MCP as the foundation, layer agentic reasoning on top of it, and apply retrieval selectively where it provides the most value rather than as a default mechanism. This progression mirrors how software systems evolve from simple integrations to robust, platform-level architectures.
Conclusion
The right question to be asked isn’t which one is better, but how much intelligence, control, and scale you really need. RAG democratized a form of grounding, Agentic RAG freed reasoning and autonomy, and MCP professionalizes AI system architectures for production-grade systems. With AI moving from the experimental to the critical, this distinction is no longer a luxury; it’s a necessary precursor to building serious AI systems in the future.
| Achieve More Than 90% Test Automation | |
| Step by Step Walkthroughs and Help | |
| 14 Day Free Trial, Cancel Anytime |









