Does AI Confabulate or Hallucinate?
|
|
To anyone who has experimented with generative AI systems or large language models (LLMs), it’s pretty clear that these models are capable of producing content that sounds both perfectly accurate and fully confident. AI sometimes produces false information with surprising fluency, whether it is writing a scientific citation, misquoting a historical event, or writing logical steps that seem completely plausible.
While many researchers now argue that the term “AI confabulation” is more accurate. This phenomenon has also been referred to as “AI hallucinations.” The argument impacts how developers, legislators, and users understand the underlying causes of AI false results and how to solve them, making it more than just a semantic issue.
| Key Takeaways: |
|---|
|
The blog covers ideas behind AI confabulation and hallucinations, their differences, the reasons behind AI models’ hallucinations, and how organizations can reduce these issues in operational systems. In addition, we will also include examples, troubleshooting techniques, and the most recent developments in AI safety and hallucination mitigation.
What is an AI Hallucination?
In the field of artificial intelligence, a hallucination is any result produced by an AI system that is confidently delivered but is actually false, fabricated, or unsupported by data. These false outputs include:
- Invented facts, dates, or scientific claims
- Fabricated quotes, references, or URLs
- Logical reasoning that appears coherent but is fundamentally incorrect
- Incorrect summaries that distort source content
LLMs do not mean to mislead when they produce this type of false information. They only use their training patterns to forecast the next most possible word sequence. In different terms, an AI hallucination is a self-assured error based on probability rather than intention or perception.
Read: What are AI Hallucinations? How to Test?
What is AI Confabulation?
Why is this term preferred by some experts?
Many cognitive scientists and AI researchers believe that confabulation is a more accurate description of what generative models do. This is despite the fact that “hallucination” has become the mainstream term. Confabulation is the term utilized in psychology to explain how people mistakenly fill in memory gaps with made-up details that are often plausible but false. It occurs without dishonesty or error awareness.
This is more in line with how LLMs function:
- They lack perception and are unable to experience hallucinations.
- They do not forget because they lack episodic memory.
- They do fill in blanks when data is missing.
- They generate output that “sounds right,” whether or not it is.
“AI confabulation” more correctly captures the mechanism behind the errors because generative AI systems work by predicting probability distributions.
Do AI Systems Confabulate or Hallucinate?
Which term is more accurate?
| Term | Pros | Cons |
|---|---|---|
| AI Hallucination | Widely understood; intuitive metaphor | Implies senses, perception, and experience, AI does not have |
| AI Confabulation | Mechanistically accurate; matches gap-filling behavior | Less common; less familiar to non-experts |
So, do AI hallucinate or AI confabulate? The extent to which you interpret the terms will influence the answer.
While “confabulation” prevents implying that AI has consciousness or sensory experience, both terms point to LLM hallucinations or AI false results.
For the purposes of technical discussion, many now prefer:
- “Model Confabulation” when discussing the mechanics
- “AI Hallucination” when discussing user-facing behavior
What Causes AI Hallucinations?
The basic architecture and training process of generative AI are the source of hallucinations. As models are meant to predict rather than validate, they experience hallucinations.
Some of the main causes include:
- Architecture of LLMs: By selecting the most possible subsequent token, LLMs generate text. They don’t automatically validate:
- Factual foundation
- Logical coherence
- Adherence to external reality
-
Gaps or Noise in Training Data: The AI training data can have gaps and noise, such as:
- Incomplete
- Contradictory
- Biased
- Outdated
- Varied quality
When these models attempt to solve uncertainty, these gaps encourage confabulation in neural networks. - Overgeneralization: Patterns that seem logical but are factually wrong can be understood by LLMs. For example, “If one 19th-century novel was written in 1847, perhaps another was too.”
- User Prompts that Force an Answer: Even in scenarios where real data is not available, models are forced to generate something by leading, direct, or high-pressure prompts (“Just tell me the answer”, “Give me the citation”, etc.
- Lack of Grounding: Models only depend on internal statistical associations unless they are connected to external tools, search engines, or validation systems.
Misalignment and Ambiguous Instructions
Hallucination: On the one hand, hallucination:
- Implies a perceptual distortion
- Suggests sensory misinterpretation
- Not technically accurate for non-sentient systems
Confabulation: On the other hand, confabulation:
- Refers to invented details to fill knowledge gaps
- Matches LLM behavior (gap-filling)
- Highlights structural limitations, not perceptual errors
Why does the distinction matter? Because the words influence:
- public understanding
- regulatory conversations
- expectations about model capabilities
- the design of testing and mitigation strategies
When building guardrails or improving model dependability, “confabulation” is often a more helpful term for developers and researchers.
Read: Top 10 OWASP for LLMs: How to Test?
Examples of AI Hallucinations
Below are some usual real-world examples of hallucinations in generative systems.
-
Fabricated Citations: A model may invent fabricated:
- Journal titles
- Page numbers
- DOIs
- Nonexistent research findings
- False logical chains
Example: “Wind turbines increase seismic activity as their rotation affects tectonic plates.” The model generates a logical but false explanation. - Invented Precedents: LLMs may create fictitious court cases, an issue that has already had legal consequences.
- Incorrect Mathematical Reasoning: LLMs may implement formulas incorrectly or generate steps that seem to be correct but generate incorrect outcomes.
- Fictitious Biographies or Events: When enquired about unfamiliar subjects, models often confabulate details about people or places.
These explain why, in delicate scenarios like healthcare, law, or scientific research, AI reliability concerns need to be taken seriously.
AI Error Types and Where Hallucination Fits in
LLM errors fall into the following categories:
- Factual errors (hallucinations/confabulations)
- Reasoning errors
- Instruction-following errors
- Ambiguity errors
- Bias-induced errors
- Context truncation errors
- Probability-based overgeneralization
While hallucinations belong to a specific category of factual errors, they often interact with issues with reasoning and generalization.
AI Hallucinations vs. Human Error: A Useful Comparison
While human errors and AI hallucinations may seem similar at first glance, their root causes are quite different. Errors are due to cognitive biases, memory restrictions, or misperception. On the other hand, AI confabulation is due to statistical prediction rather than misinterpretation. This difference is important because AI false outputs arise from the underlying model architecture and training data. This needs a technical rather than psychological solution, whereas human errors are often connected to emotion or fatigue.
The Role of Evaluation Metrics in AI Hallucination Testing
Metrics designed to measure the frequency of hallucinations in AI models are becoming more and more critical to modern AI examination. To understand if trustworthy and reliable data support the output from an LLM, we can use standards such as FactScore, TruthfulQA, and domain-specific accuracy tests. These metrics allow for continuous observation, provide early drift detection, and help teams in deciding whether hallucination safeguards are working effectively in real-world settings. This methodical approach ensures that hallucination mitigation is a component of a quantifiable AI dependability strategy rather than relying on pure guesswork.
Read: What is AI Evaluation?
Detecting AI Hallucinations
How do systems detect and flag false outputs?
To catch hallucinations, developers must use a range of techniques:
- Confidence Scoring: In order to enable systems to detect low-confidence responses, modern LLMs are increasingly estimating their internal uncertainty.
- Retrieval-augmented Generation (RAG) Validation: Documents that have been collected need to be compared to the results.
- Checking Consistency: Validating for agreement by utilizing multiple models or by iteratively prompting the model.
- Formal Verification: Symbolic solvers validate the results for logical or mathematical tasks.
- Human-in-the-loop QA: Necessary for enterprise, legal, and healthcare use cases.
Read: How to Keep Human In The Loop (HITL) During Gen AI Testing?
Reducing AI Hallucinations in Production
AI safety, hallucination guardrails, and mitigation strategies are required for reducing AI hallucination in production. Organizations utilizing AI need long-standing methods to handle hallucinations. Important mitigation techniques include:
-
Grounding the Model: This means connecting LLMs to:
- structured databases
- search tools.
- verified knowledge stores
- Retrieval-Augmented Generation (RAG): It is a common method for reducing hallucinations, which offers context from external data before the model produces a response.
- Better Training Data: Data has been cleaned, optimized, and curated, and is less ambiguous.
- Instruction Tuning: AI-generated false facts can be highly reduced by teaching the model to admit uncertainty.
- System-level Guardrails: Rule-based systems that change or prevent responses from appearing speculative, risks from a medical and legal POV, and are unsupported.
- Post-generation Fact-checking: Model chains or external APIs for output verification.
- Role Prompting and Restrictions: Confabulation in LLMs is reduced by clearly defined roles (e.g., “Answer only using the offered context”).
- Enterprise hallucination testing: Nowadays, a lot of organizations execute structured tests:
- Prompt-adversarial tests.
- Perturbation tests.
- Accuracy standards.
Read: What is Adversarial Testing of AI?
How testRigor Helps Reduce AI Hallucinations
testRigor lets teams spot fake AI responses using automation for AI-powered processes. Instead of complex scripts, you write tests in plain English. So, checking if outputs are correct becomes quick and straightforward. It flags defects early, while keeping an eye on how things work in real-world settings outside the lab. Tests don’t break easily, need little maintenance, and give obvious outcomes. It is helping organizations keep live AI accurate, realistic, and trustworthy through the use of AI context, user intent, Vision AI, NLP, and other advanced AI algorithms.
Test Case 1: Let us check an AI agent with testRigor to see if it knows which film won the most recent Oscars (2025).
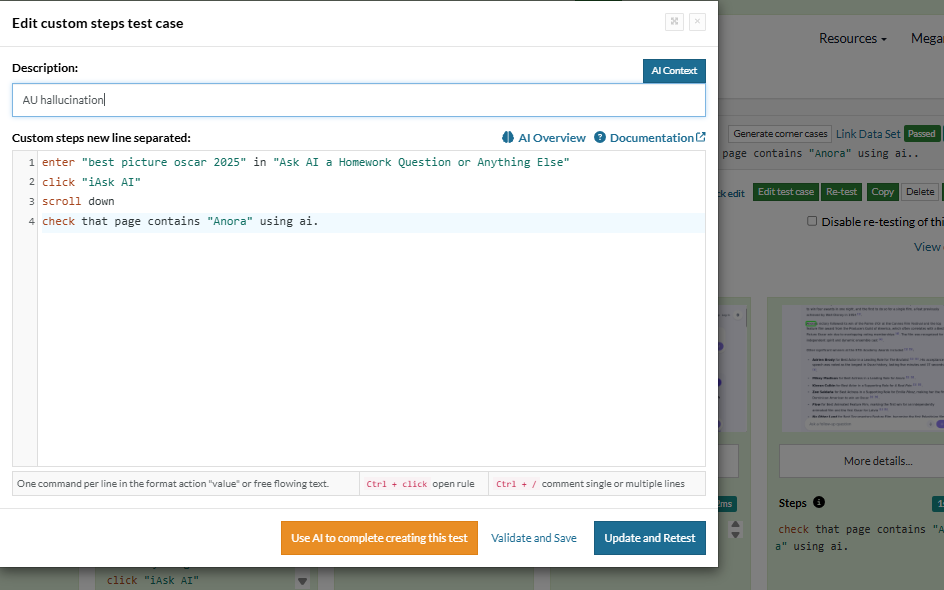
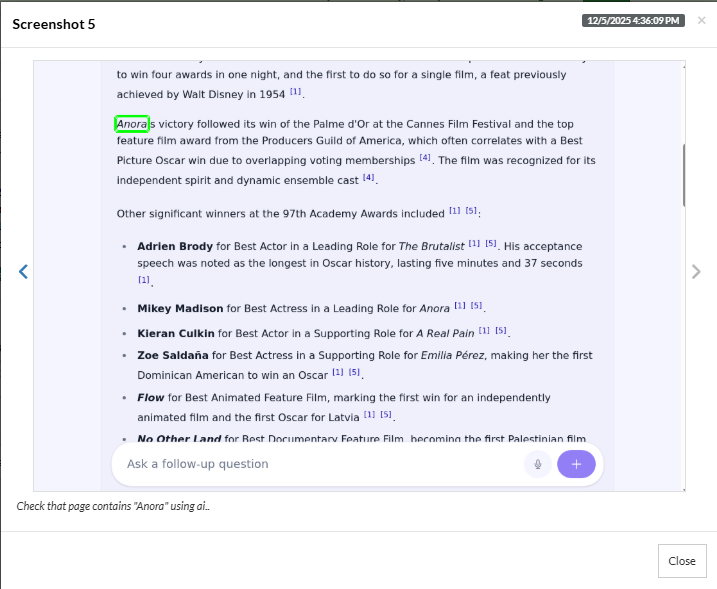
The AI agent shows the right answer, i.e., “Anora”, testRigor recognizes it using AI, and marks the test “Pass”.
Test Case 2: Let us use testRigor to see if the answer is right even if the question is changed (same context, different phrasing).
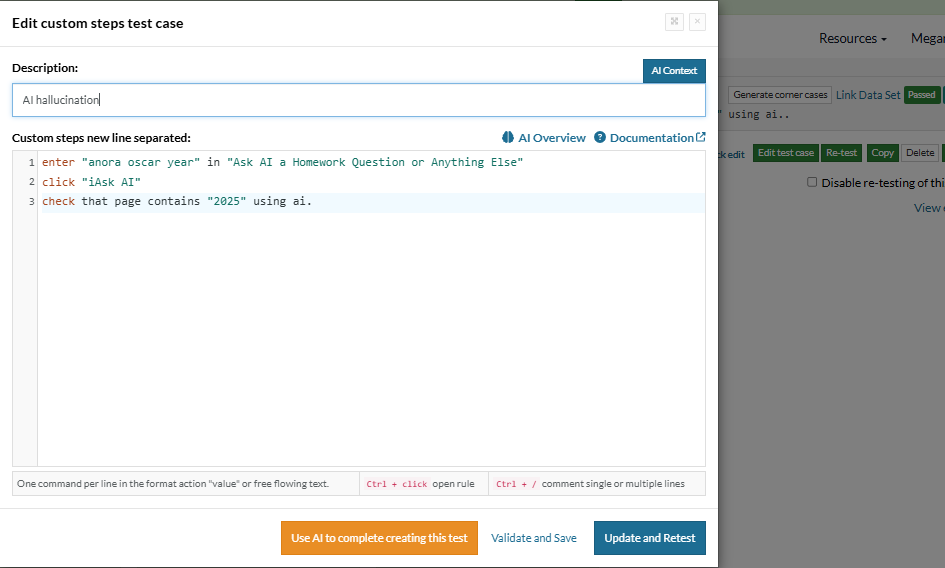
Again, the AI agent displays the year it won the Oscar correctly, and testRigor recognizes it and marks the test as “Pass”. However, if the AI agent had shown the wrong result, testRigor would have recognized that using AI. testRigor can easily identify positive/negative statements, false/true statements, user intent, complex images, graphs, and other AI features.
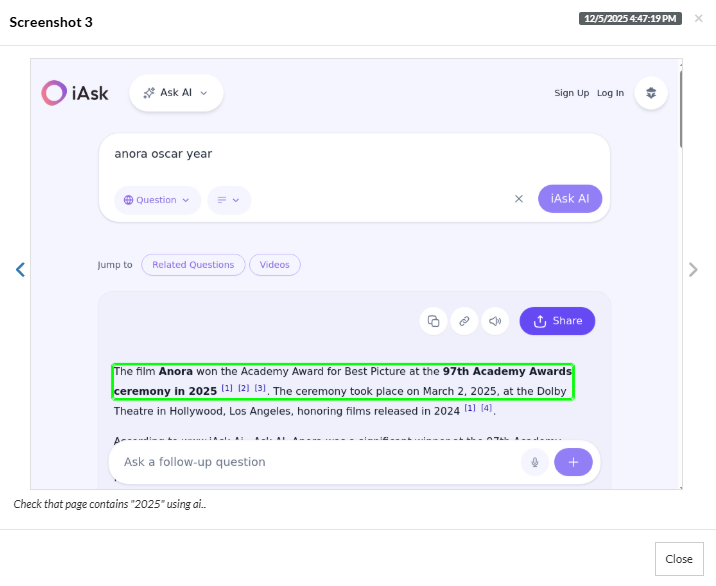
Result: It proves that different questions on the same topic yield the right answers, proving that AI was not hallucinating. testRigor’s plain English commands make it easier to test different scenarios without complicating the test case.
Troubleshooting AI Hallucinations
How can we reduce the frequency of hallucination in AI models? When hallucinations occur, developers need to think about:
- Was the prompt ambiguous or leading? Make it more precise. Read more: Prompt Engineering in QA and Software Testing.
- Did the query fall outside the knowledge scope of the model? Add guardrails to encourage refusals.
- Did the model lack grounding? Connect it to knowledge bases or tools.
- Was the multi-step reasoning used in the output? Make use of verified modules or chain-of-thought hiding.
- Does the domain present a major risk? Introduce workflows that are human-reviewed.
Even for complex enterprise deployments, hallucination reduction becomes feasible with the right architecture.
The Future of AI Confabulation and Hallucination Research
Awareness of confabulation and hallucinations will be vital for both safety and trust as generative AI becomes more and more integrated into daily life.
New studies will focus on:
- Self-verifying models that double-check their own outputs.
- Hybrid models that mix neural prediction and symbolic reasoning.
- Automated algorithms for identifying hallucinations.
- Model interpretability tools that display uncertainty.
- Training paradigms that reduce overgeneralization.
Over time, we might witness LLMs who:
- Dependably defer to outside tools.
- Confidently accept when they don’t know.
- Reduce the frequency of hallucinations below human error rates.
However, vigilance is necessary for now.
Does AI Hallucinate or Confabulate?
In the end, both terms are correct, but they point to unique facets of the same phenomenon.
- The user-facing experience: confident, inaccurate outputs that seem real are captured by AI hallucinations.
- The mechanism, which is probabilistic gap-filling based on how neural networks generate text, is caught by AI confabulation.
Teams can generate more efficient hallucination guardrails, expect reliability issues, and design better systems by understanding the difference. The proper combination of model architecture, system-level restrictions, data grounding, and human monitoring can decrease, detect, and prevent hallucinations, even though they may never fully disappear.
Our vocabulary for describing AI’s limitations evolves as AI updates. This is in addition to our methods for ensuring that generative models continue to be secure, dependable, and consistent with reality.
| Achieve More Than 90% Test Automation | |
| Step by Step Walkthroughs and Help | |
| 14 Day Free Trial, Cancel Anytime |









