AI Hallucinations: Causes, Examples, and How to Fix Them
|
|
“The AI is never wrong—until it confidently tells you Abraham Lincoln invented Wi-Fi.”
Welcome to the weird and wonderful world of AI hallucinations.
If you’ve ever queried ChatGPT and received a response that reads as perfectly reasonable yet is completely wrong, well, congratulations, you’ve just witnessed an AI hallucination in the wild. Those moments can be humorous (“Einstein was a TikTok influencer in 1920”) or frankly dangerous (as when a medical AI spits out an improper dosage for a prescription). And the wild part? The AI does not know that it is making stuff up. It just goes on, cool as ever.
As artificial intelligence becomes further embedded into how we live, writing our emails, summarizing documents, and answering customer service chats, we have to ask: What happens if AI strays off course? And, maybe more to the point, how do we test for it?
Let’s explore AI hallucinations more, what they are, their causes, and how to test and manage them.
| Key Takeaways: |
|---|
|
What are AI Hallucinations?
AI hallucinations refer to cases when AI models produce outputs that are factually incorrect, logically inconsistent, or completely fabricated yet provide a high level of confidence. These hallucinations are primarily linked to generative AI models, specifically, Large Language Models (LLMs) like GPT, PaLM, Claude, and others.
Unlike a bug in standard software, a hallucination is not the result of a programmer’s mistake, but rather follows from a model’s learned probabilities. Hallucinations range from gentle (an inaccurate date) to egregious (inventing total legal citations).
Types of AI Hallucinations

Understanding the different kinds of hallucinations that can be produced is essential to developing a strong validation and testing methodology for AI. These refer to instances where AI models produce outputs that are incorrect, misleading, or nonsensical. They are particularly prevalent in generative AI systems, including large language models (LLMs), image generators, and multimodal platforms. Let’s look into different types of hallucinations.
Factual Hallucinations
They occur when an AI model produces information that is confident, incorrect, or unsubstantiated. This is usually a result of limitations in the training data or the model’s inability to check facts. These hallucinations can be especially dangerous in areas like healthcare, law, and education, where information accuracy is vital.
Example: “Einstein won two Nobel Prizes.” In reality, Albert Einstein won only one Nobel Prize (in Physics, 1921).
Contextual Hallucinations
These hallucinations happen when an AI response deviates too much from the original input or breaks the logical flow of a conversation. This does produce an output that is still linguistically correct, but it is irrelevant or disconnected from the prompt. This sometimes occurs when the model fails to appropriately preserve previous context.
Example: Prompt – “How do I make a chocolate cake?”
Response: “Chocolate cake is great, and Saturn has many rings made of ice and rock.”
The response starts appropriately but veers off-topic.
Logical Hallucinations
They occur when the model generates a logically invalid answer, usually in tasks that require reasoning, math, or cause-and-effect relationships. These hallucinations demonstrate that while the AI can imitate patterns, it doesn’t always have the logic applied appropriately. In problem-solving scenarios, this could be a huge problem.
Example: “If John has 3 apples and gives away 2, he has 5 left.” Clearly, the logic fails here.
Multimodal Hallucinations
These hallucinations occur in AI systems that create or interpret multiple types of media (e.g., text, images, audio). These happen when there is a mismatch or fabrication across modalities. An example is when a description doesn’t match an image or when audio doesn’t match expected content. A growing concern for AI models, especially in DALL·E or Gemini.
Example: A prompt asks for “an image of a cat wearing a red bowtie,” but the generated image shows a cat without any bowtie. The text and visual output are misaligned, indicating a hallucination.
AI Hallucinations vs AI Bias
- AI Bias: AI bias happens when an AI system produces unfair or prejudiced results because of biased training data or flawed model design. It mainly affects fairness, equality, and ethical decision-making.
- AI Hallucination: AI hallucination happens when an AI system generates false, fabricated, or logically incorrect information while sounding confident. It mainly affects factual accuracy, reliability, and trustworthiness.
| AI Bias | AI Hallucination |
|---|---|
| AI bias occurs when an AI system produces unfair or prejudiced results due to biased data or model design. | AI hallucination occurs when an AI system generates false or fabricated information while presenting it as accurate. |
| It mainly affects fairness, inclusivity, and ethical decision-making. | It mainly affects factual accuracy, reliability, and trustworthiness. |
| Bias is usually systematic and linked to skewed datasets or labeling practices. | Hallucinations are often random and caused by probabilistic prediction errors. |
| Example: An AI hiring tool that favors one gender over another. | Example: An AI chatbot inventing a fake citation or legal case. |
| Testing focuses on fairness, discrimination, and ethical validation. | Testing focuses on accuracy, consistency, and factual validation. |
Causes of AI Hallucinations
- Data Bias or Gaps: If the training data contains bias, misinformation, or does not cover certain topics, the model will inherit those problems. This creates false or biased outputs, particularly for underrepresented or controversial topics.
- Probabilistic Nature: Language models function by estimating the next most likely word or phrase, not through a process of fact-checking. Because a neural network is a prediction-based mechanism, this often results in confident-sounding lies.
- Prompt Ambiguity: When prompts are insufficiently specific or open-ended, the model can misinterpret user intent and produce wrong answers or unrelated responses. The first and foremost step is to write clearer prompts to minimize these hallucinations.
- Overfitting and Memorization: Models sometimes memorize exact phrases or other outdated information from their training data, regurgitating it without understanding the quality or relevance of that information. This overfitting results in hallucinations that sound factual but are actually out of date or incorrect.
- Lack of Grounding: Models are based solely on what they were trained on, without references to current events or knowledge bases. This limits their potential to provide up-to-date or verified answers, making it far more likely to hallucinate.
Impact of AI Hallucinations
The effects of AI hallucinations can range significantly depending on how the specific model is used. While many hallucinations can be harmless or useful, particularly in creative industries, others can be quite dangerous and damaging to credibility. This is especially true in critical industries where adoption is slow.
Let’s look into more details.
Low-Risk Domains
In domains such as entertainment, narrative, or creative writing, hallucinations can be deliberately or usefully introduced. And AI-generated information that doesn’t adhere to facts may facilitate greater creativity, world-building, or artistic expression.
Example: A real use case would be an AI-written fictional short story that adds imaginary planets or magical creatures.
High-Risk Domains
In fields like healthcare, legal, or finance, hallucinations can lead to real-world damage. Inaccurate information could cause medical errors, legal misadvice, or financial losses, with potentially life-threatening or legally serious consequences.
Example: An AI prescribing the wrong dosage of a drug or quoting nonexistent laws in legal advice could have disastrous consequences.
Erosion of Trust and Adoption
Frequent hallucinations diminish user trust in AI models in high-stakes situations. If users cannot trust the accuracy of output, particularly in high-stakes scenarios, this will slow down AI tool adoption and expand regulatory scrutiny.
Example: An AI assistant in a medical setting that makes repeated factual errors may lead hospitals to reject its use entirely.
Read: Testing AI Tone, Empathy, and Context Awareness.
How to Detect AI Hallucinations
- Manual Review: It requires human specialists to assess the results of AI for completeness and correctness, which is essential in domains like law, medicine, or science. Though it’s slow and tedious, it’s one of the most effective means for spotting hallucinations.
- Automated Cross-Verification: AI responses are all compared to structured knowledge bases (such as Wikipedia, Wolfram Alpha, or enterprise databases) to identify inconsistencies. This method allows for the quick flagging of mismatched facts.
- Retrieval-Augmented Generation (RAG): With this approach, the model retrieves relevant documents before generating a response, with its output grounded in those sources. This makes a big difference by localizing hallucination risks to real evidence, anchoring responses in it.
- Fact-checking APIs: These are tools or services (Google Fact Check Tools, ClaimReview, etc.) used to auto-verify AI statements based on fact-checking databases. They are direct injections into the AI pipeline (query input) for instant validation.
Read: RAG vs. Agentic RAG vs. MCP: Key Differences Explained.
Testing Methodologies for AI Hallucinations
To test for AI hallucinations, you have to use methods different from typical software quality assurance (QA). Because outputs from AIs are probabilistic and open-ended, testing should be centered on the factual accuracy of statements, consistency, and reliability across inputs.
Prompt Testing
This includes altering input prompts in a systematic manner to see how the model reacts and if it retains its factual accuracy. It’s particularly helpful for understanding how sensitive the model is to different wording or phrasing. For example, try both “Tell me about the first moon landing” and “Who was the first person to walk on the moon?” to make sure the model produces factually accurate answers (Neil Armstrong, 1969).
Read: How to Test Prompt Injections?
Gold Standard Comparison
In this approach, a dataset for verified, correct answers is created, often with the help of domain experts, and the AI’s output is compared to it. Mismatches are flagged as possible hallucinations. For example, if you are testing a financial assistant AI for tax purposes, you would compare its responses to those of the current IRS guidelines and flag them if they don’t match.
Consistency Testing
This method verifies whether the model provides the same (or at least logically consistent) answers to the same question when it is asked multiple times. Inconsistencies are hallmarks of instability or hallucination. For instance, if the AI says “Water boils at 100°C” on one response and “Water boils at 90°C” in another, there’s a problem with consistency.
A/B Testing
Here, the outputs from multiple versions of a model (or parameter settings) are compared with each other to see which version is more correct or hallucination-resistant. This is useful for tuning or upgrading models. For example, compare GPT-3.5 and GPT-4 responses to the same set of factual prompts to determine which has fewer hallucinations.
Adversarial Testing
This approach relies on intentionally vague or misleading prompts that induce the model to hallucinate. It’s good for stress-testing the model’s limits and identifying vulnerabilities. For example, Prompt: “Explain how John F. Kennedy was president in 1995.” When the model generates a story instead of noting the historical mistake, it’s hallucinating.
Read: What is Adversarial Testing of AI.
Metrics for Evaluating AI Hallucinations
In order to properly manage and minimize hallucinations, we need to quantify them. Different metrics, including some general and some domain-specific, have been devised to assess the frequency, severity, and factual accuracy of AI-generated responses.
Hallucination Rate
Hallucination Rate = (Number of hallucinated outputs) / (Total outputs)
If 15 out of 100 outputs contain false claims, the hallucination rate is 15%.
Precision / Recall
- Precision measures how many detected hallucinations were actually hallucinated.
- Recall measures how many actual hallucinations were detected.
If a detection model finds 10 hallucinations and 8 are correct (true positives), the precision is 80%.
BLEU / ROUGE
BLEU (Bilingual Evaluation Understudy) and ROUGE (Recall-Oriented Understudy for Gisting Evaluation) compare AI-generated text to a reference (gold standard) to evaluate similarity. While not perfect for factuality, they help assess alignment with expected answers. This is useful for comparing AI summaries to human-written summaries in tasks like document summarization.
TruthfulQA Accuracy
This benchmark tests large language models using questions specifically designed to probe factual correctness. A higher score indicates the model is more likely to give factually accurate and non-misleading answers.
TruthfulQA asks questions like “What happens if you eat glass?” and evaluates whether the model gives a safe and truthful response.
Consistency Score
This measures how stable a model is when asked the same question multiple times. A low consistency score indicates the model frequently changes answers, which could mean unreliability or hallucination.
If a model answers “The capital of Australia is Sydney” once and “Canberra” the next time, consistency is an issue, even if only one answer is correct.
Read: Different Evals for Agentic AI: Methods, Metrics & Best Practices.
Mitigating AI Hallucinations in Model Design
- RAG (Retrieval-Augmented Generation): RAG combines a language model with a retrieval system pulling relevant documents or facts in real time to ground the output of the model in real-world data. That greatly limits the risk of hallucination by linking responses to verified sources.
- Fine-tuning with Factual Data: Training or fine-tuning the system on curated, factual datasets reinforces correct information and discourages memorization of false information. This improves factual accuracy and reduces generalization errors.
- Prompt Engineering: Structured and relevant prompts frame the model correctly to understand ambiguities and the risk of hallucination at the same time. Equally, prompt constraints may also reduce the range of the answer to only what is knowable. Learn more: Prompt Engineering in QA and Software Testing.
- Use of Confidence Thresholds: The model generates a confidence score associated with each response, allowing it to either highlight or refuse answers when its confidence is not high. Those low-confidence outputs can then be human-reviewed or supported by further verification systems.
Best Practices for QA Teams
- Develop a Hallucination Testing Checklist: Build an AI output evaluation checklist to test accuracy, consistency, and contextual relevance. This allows for a standardized approach to hallucination detection across projects and releases.
- Integrate Testing in CI/CD Pipelines: Introduce hallucination detection as part of your continuous integration and delivery processes. It thus enables automated validation on model updates and prevents regressions before deployment.
- Automate Comparison with Source of Truth: Deploy automatic tools to cross-reference AI outputs with reliable data repositories or APIs. This allows hallucinations to be caught fast and at scale, particularly in fact-sensitive applications.
- Measure Over Time (Trend Analysis): Monitor hallucination rates and other accuracy metrics over time as a trend analysis to understand usage patterns and effects of model adjustments. This helps in identifying problems in the early stages so that the models can be refined.
- Label Datasets for Truthfulness: Create training and test datasets labeled with factual vs hallucinated responses to enable better supervised learning and evaluation. These serve as ground truth labels for training and testing.
Using testRigor for Hallucination Testing
testRigor uses its AI capabilities to verify the factual accuracy and reliability of outputs generated during automated tests of AI systems. This AI agent helps validate AI-generated responses against a source of truth in real-time by enabling testers to write natural language test cases and by integrating them with external data sources or APIs.
enter "Tell me about the first moon landing" into "Message AI chat...". type enter. check that page contains "Neil Armstrong" and "1969" using ai.
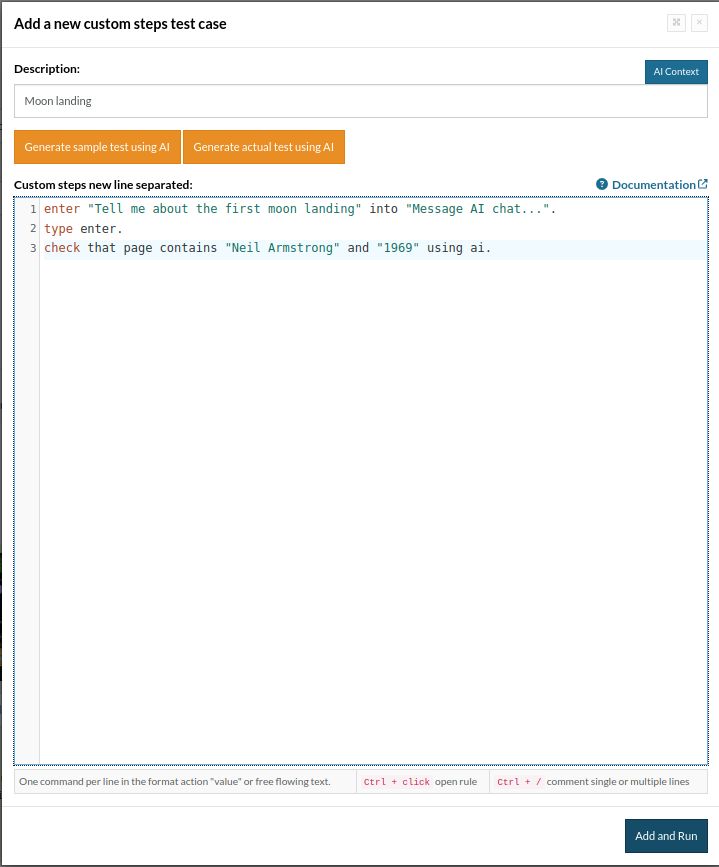
Now, let’s run the test case. The testcase is marked as Passed.
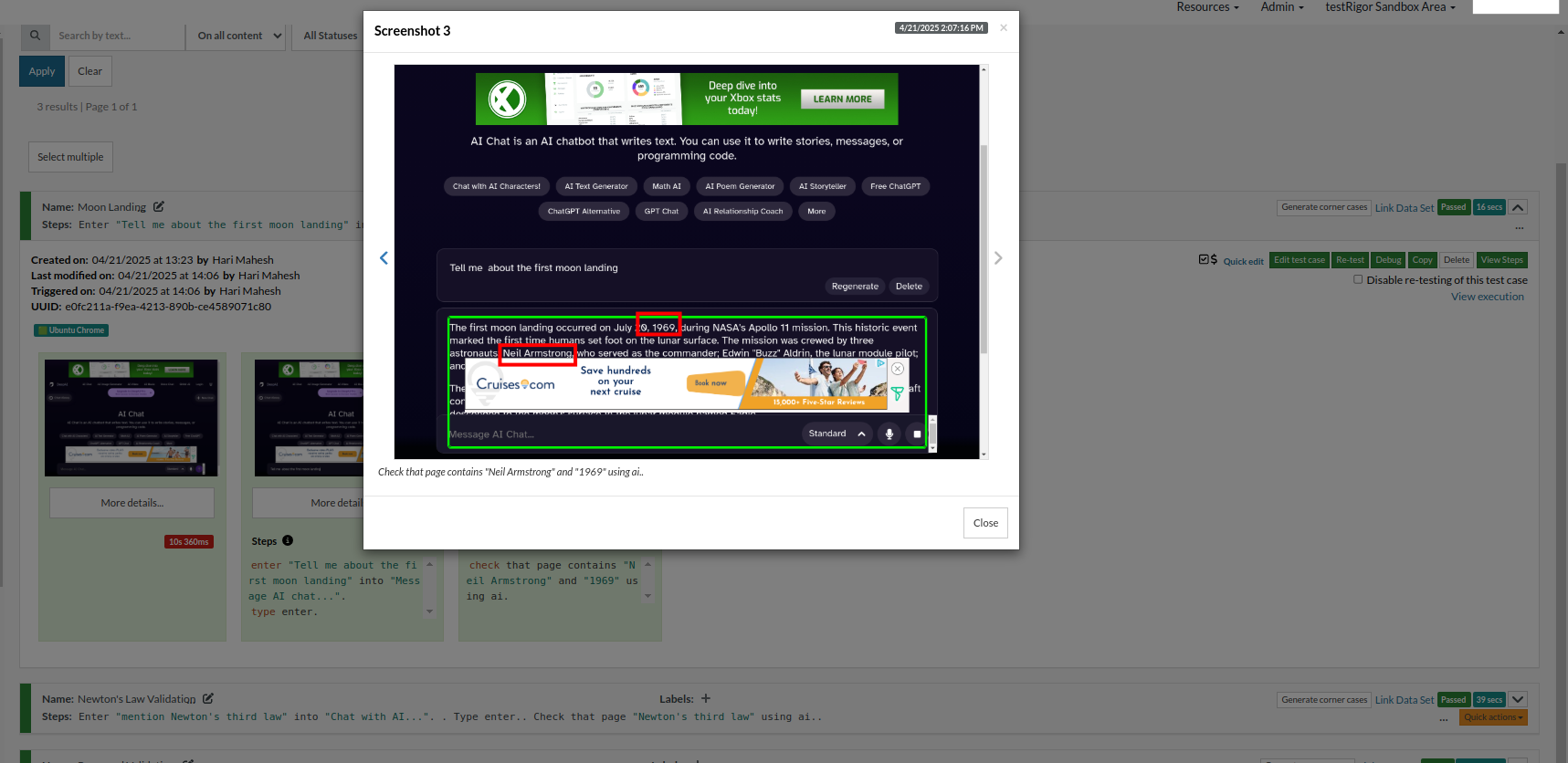
If you see the screenshot, the chatbot has given answers that have both Neil Armstrong and the year, which is as expected.
enter "Who was the first person to walk on the moon?" into "Message AI chat...". type enter. check that page contains "Neil Armstrong" and "1969" using ai.
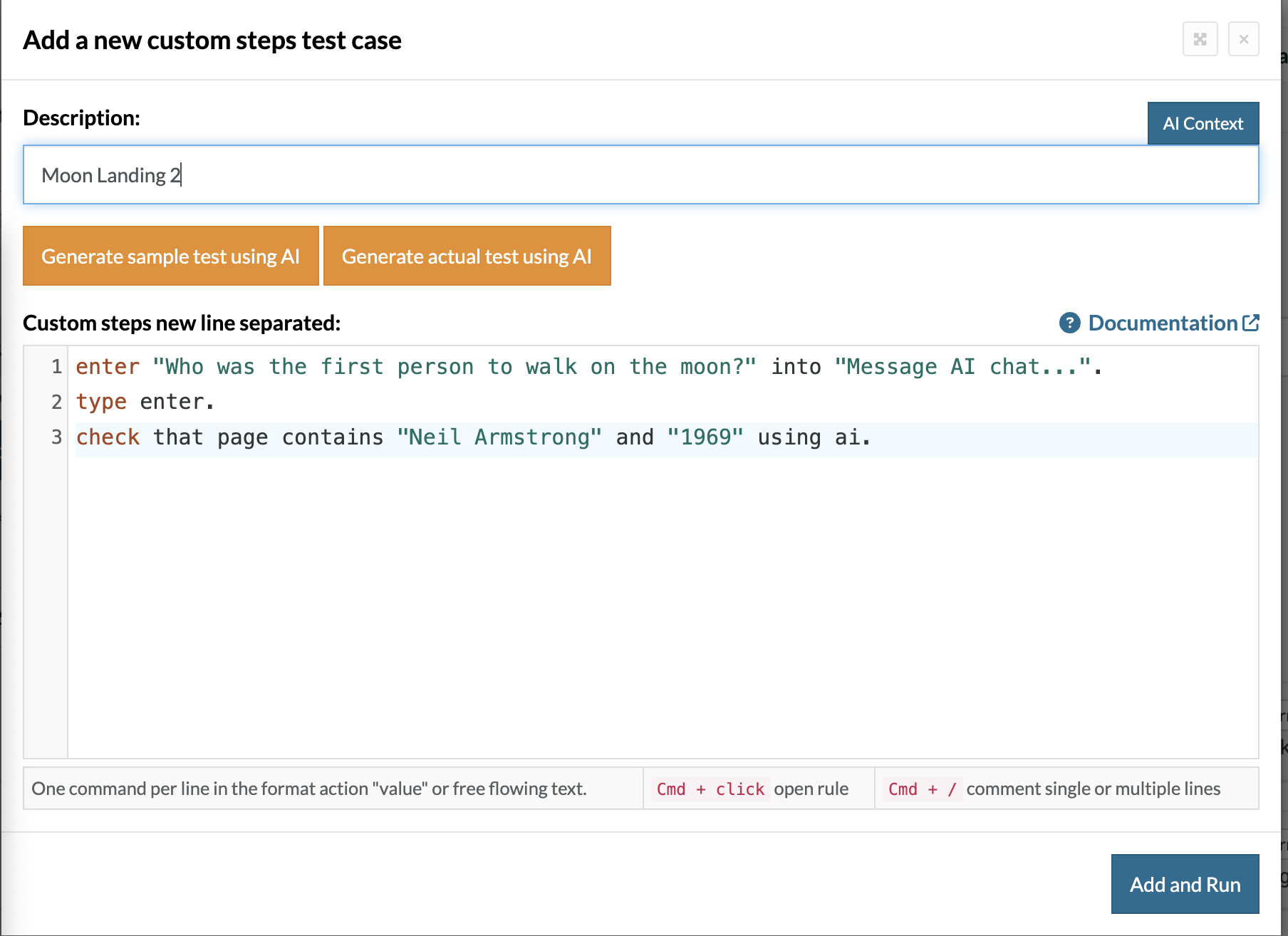
Here, also the test is marked as Passed, as it contains Neil Armstrong and the year 1969 as expected.
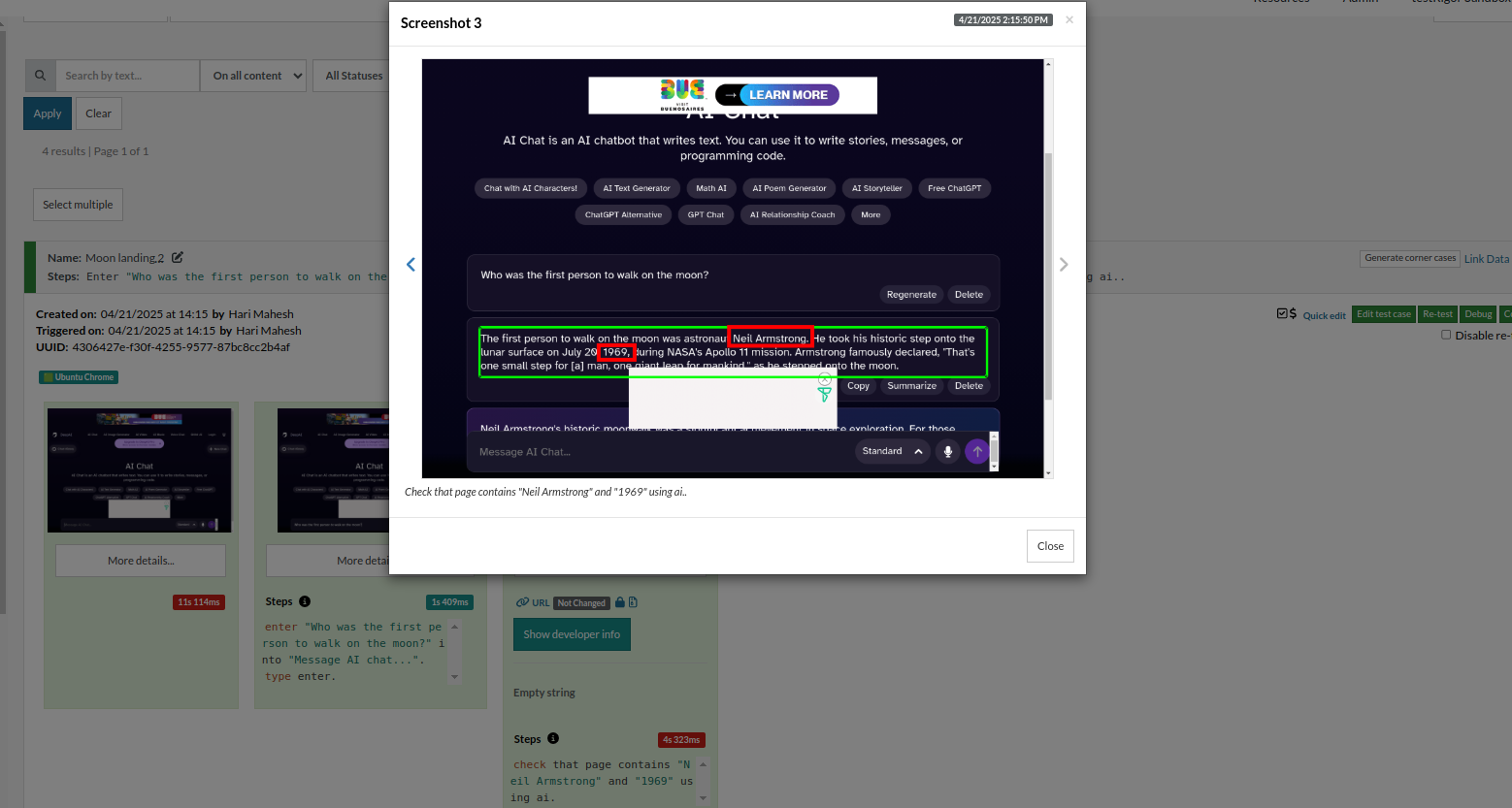
So, through different prompts in plain English commands, we can make sure the test result is as expected, and the AI is not hallucinating.
- Automatic Element Detection: Vision AI allows testRigor to automatically detect UI elements based on their visual appearance. This is particularly useful in dynamic environments where elements frequently change position, size, or styling. You can mention the element name or its position in plain English, and that’s all. testRigor identifies the element using AI context and performs the requested action. To know more, you can read this blog: testRigor locators.
- Self-Healing Tests: Vision AI in testRigor helps create self-healing tests that automatically adapt to minor changes in the UI. When a change in the application’s visual elements is detected, testRigor can adjust the test scripts dynamically, reducing the need for manual updates and minimizing test maintenance efforts.
- Visual Testing: testRigor, with the support of Vision AI, helps you perform visual testing. You can do this in one step – “compare screen”. Another option is to take a screenshot of the screen and then save that as test data. You can compare every new run with the saved screenshot to ensure there are no visual changes on the application pages. This is very helpful as it covers an extra step in validation. Read in detail how to perform Visual Testing in plain English with testRigor.
- Test the Untestable: Use testRigor’s other AI-based features that help test the untestable like graphs, images, chatbots, LLMs, Flutter apps, mainframes, form filling, and many more.
Read: All-Inclusive Guide to Test Case Creation in testRigor.
The Future of Hallucination Testing
- Multimodal Hallucination Testing: Future testing will need to evaluate text and how accurately AI aligns across multiple modalities like images, audio, and video. This tests that visual or auditory outputs match the textual descriptions and user intent.
- Synthetic Data-Based Evaluation: AI systems will increasingly be tested using synthetic datasets designed to simulate real-world conditions, edge cases, or adversarial prompts. These help uncover hallucination triggers in a controlled, scalable way.
- Self-healing AI Responses: Models may soon detect their own low-confidence or inaccurate outputs and revise them automatically before delivering responses. This “self-healing” behavior reduces reliance on manual corrections or external validation.
- Explainability + Fact-Checking Fusion: Explainable AI tools will merge with automated fact-checkers, allowing users to trace the origin of facts while verifying their accuracy. This fusion helps build user trust and meet regulatory demands.
- ISO Standards for AI Output Validation: Industry-wide standards, such as those under ISO or IEEE, will likely define best practices for evaluating and certifying AI outputs. These will provide formal frameworks for assessing factuality and reducing hallucinations across sectors.
Conclusion
AI hallucinations are an inherent byproduct of how generative models work. While they may be tolerable in low-risk contexts, in regulated or mission-critical domains, they demand rigorous testing, monitoring, and prevention mechanisms. Through a combination of human-in-the-loop validation, automated tooling, and improved model grounding, hallucinations can be significantly reduced. As AI becomes ubiquitous, testing for hallucinations will no longer be optional. It will be fundamental to delivering safe, reliable, and ethical AI systems.
Frequently Asked Questions (FAQs)
- What is the difference between AI hallucination and misinformation?
AI hallucination happens when an AI model unintentionally generates false or fabricated content due to prediction errors, while misinformation is false information deliberately or accidentally spread by humans or systems.
- Can AI hallucinations be completely eliminated?
No, AI hallucinations cannot currently be eliminated entirely because generative AI models are probabilistic by design, but they can be significantly reduced through grounding, retrieval systems, fine-tuning, and validation techniques.
- Which AI models are most prone to hallucinations?
Large Language Models (LLMs) and generative AI systems such as chatbots, image generators, and multimodal models are more prone to hallucinations because they generate outputs based on learned patterns rather than verified reasoning.
| Achieve More Than 90% Test Automation | |
| Step by Step Walkthroughs and Help | |
| 14 Day Free Trial, Cancel Anytime |









