What is AI Evaluation?
|
|
“In business, the opportunities for AI are significant, but only if they address real needs.” – Bill Gates.
When talking about AI, one is often awestruck by what it can do. However, as the above quote clearly states, even the best tools are useless if they don’t solve real problems. To see if AI is solving the problem, you must evaluate it, often using different yardsticks or metrics. Unlike traditional software, however, AI keeps adapting and evolving, meaning you need to have a system for AI evaluation, more popularly known as an AI eval system.
Let’s learn more about AI evaluation, how it’s done, and the metrics involved in it.
| Key Takeaways: |
|---|
|
What Makes Evaluation of AI Unique?
Unlike standard software that follows strict, predefined rules, AI models learn from data and often produce results that are more about probabilities than certainties. This means your AI might give slightly different answers even with the same input, based on its learning. This “probabilistic” nature is a key difference.
Another crucial aspect is data dependency. AI models are only as good as the data they learn from. If the data is flawed, incomplete, or biased, the AI will reflect those issues. If the data used to train an AI isn’t diverse or representative, the AI can develop unfair biases or perform poorly in real-world situations.
Furthermore, AI models aren’t static. They can evolve and change their behavior over time, especially if they’re continuously learning from new data. This means testing an AI isn’t a one-and-done task. It requires ongoing checks to ensure it’s still performing as expected. For advanced AI, particularly those that generate content like text or images, we also need to evaluate subjective qualities such as creativity, coherence, and relevance – things that are hard to measure with a simple pass/fail. Read: Generative AI vs. Deterministic Testing: Why Predictability Matters.
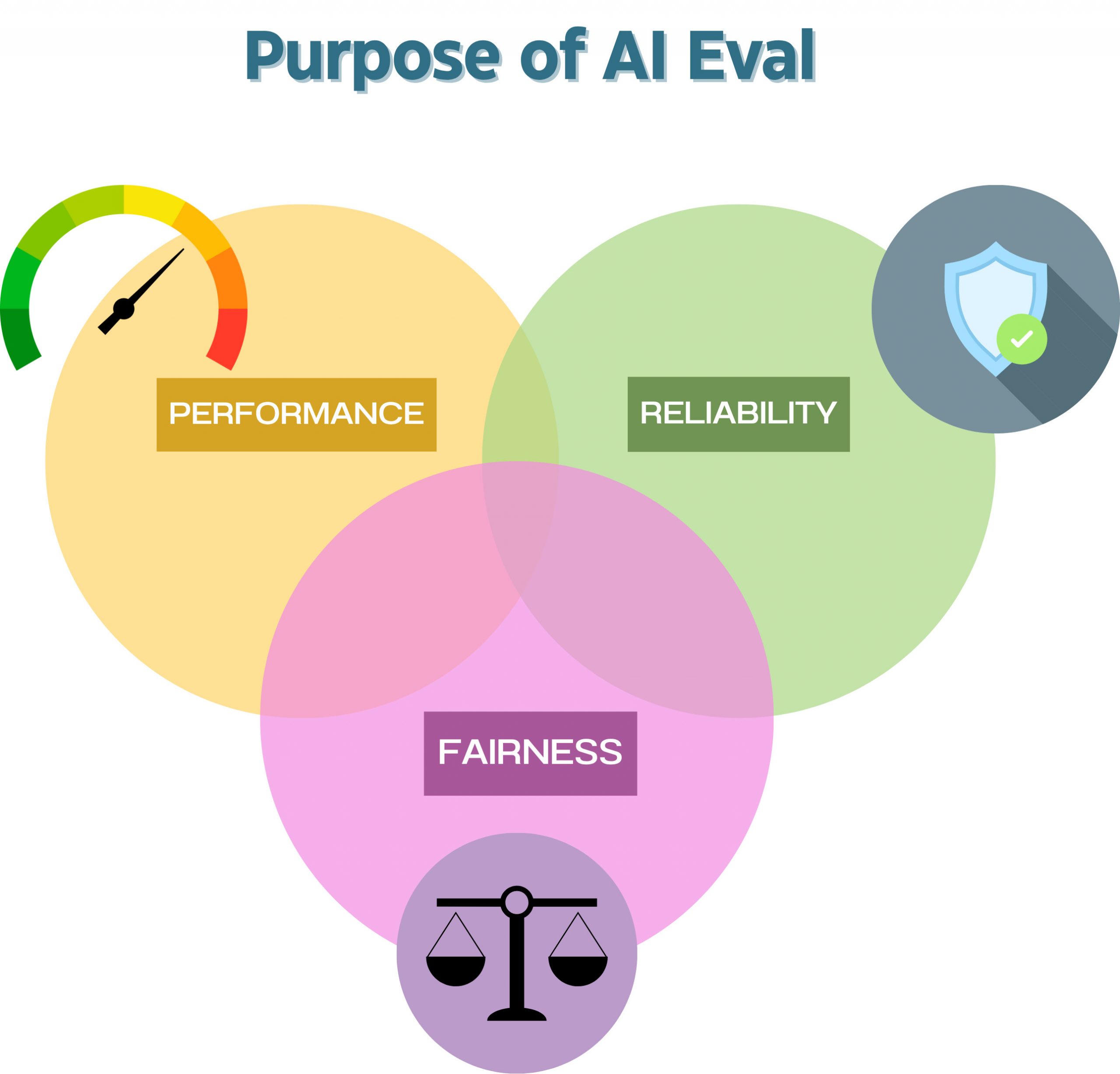
Objectives of Evaluation in AI
It boils down to a few key goals:
- Performance & Accuracy: Does the AI do what it’s supposed to do, and does it do it correctly?
- Reliability & Robustness: How well does the AI handle unexpected or unusual inputs? Does it consistently perform well, or does it easily break down when faced with something a bit different from what it’s seen before?
- Fairness & Bias Detection: We need to ensure the AI isn’t making unfair or discriminatory decisions based on factors like gender, race, or other sensitive attributes.
- Explainability & Interpretability: Can we understand why the AI made a particular decision? In critical applications like healthcare or finance, knowing the reasoning behind an AI’s output is just as important as the output itself.
- Ethical Compliance: Beyond fairness, does the AI adhere to broader ethical guidelines? Is it designed and operating in a way that aligns with societal values and avoids harmful outcomes?
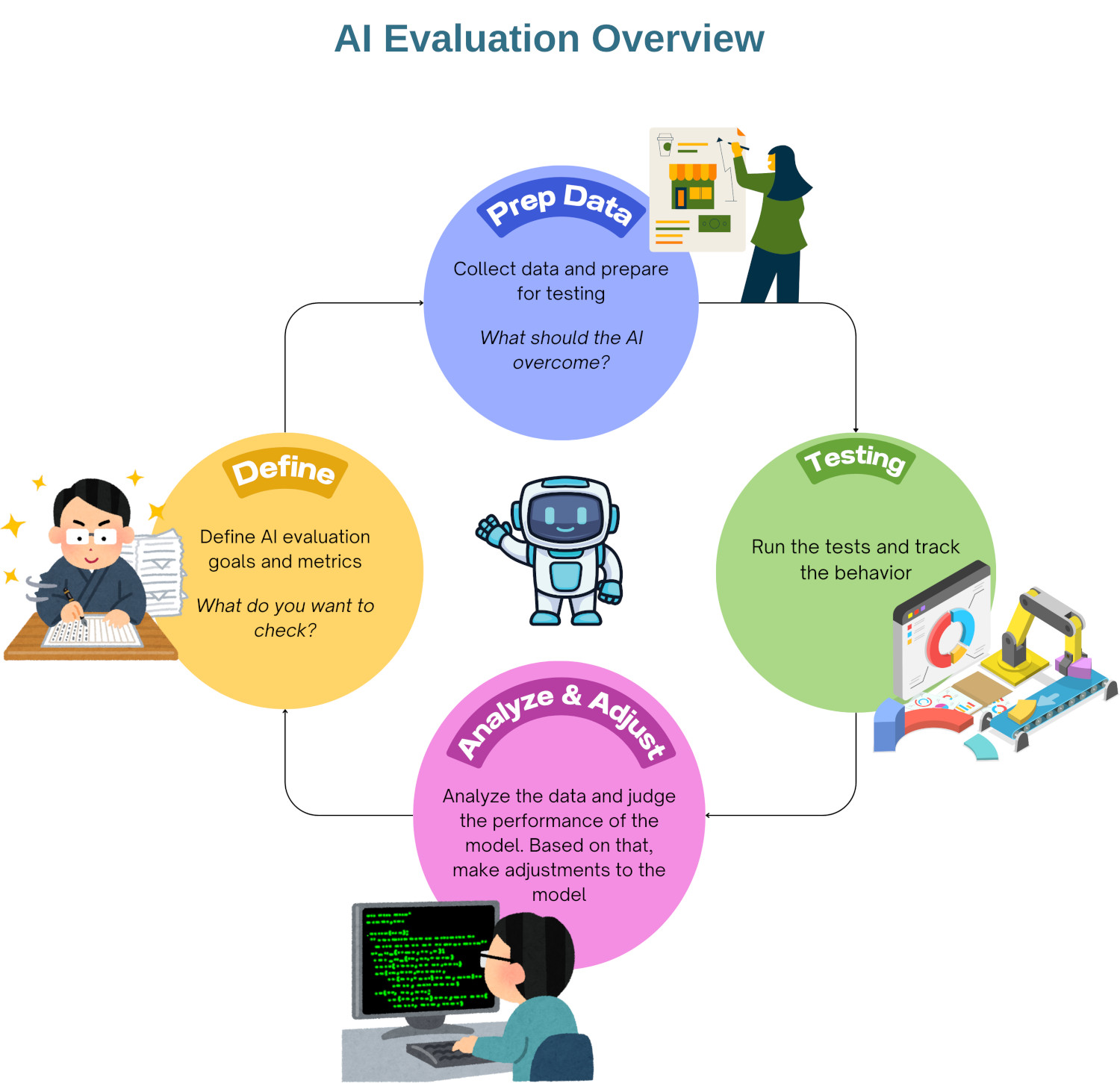
AI Evaluation in Practice
Evaluating AI isn’t a single step; it’s a multi-faceted process that touches different stages and aspects of an AI system’s lifecycle.
Data-Centric Evaluation
At the heart of any AI is its data. Just like a chef needs good ingredients, an AI needs good data to learn effectively.
- Data Quality & Preprocessing: This is about making sure the “ingredients” are top-notch. It involves cleaning the data, handling missing pieces, and preparing it in a format the AI can understand. If your data is messy or inaccurate, the AI’s learning will be flawed, leading to poor performance – it’s the classic “garbage in, garbage out” scenario.
- Training, Validation, and Test Sets: To ensure an AI truly learns and doesn’t just memorize, we divide our data into three main parts.
- The “training set” is what the AI learns from.
- The “validation set” helps us fine-tune the AI during its learning process, preventing it from getting too good at just the training data (a problem called “overfitting”).
- Finally, the “test set” is entirely new where unseen data is used for the final assessment of how well the AI performs in the real world.
- Data Drift Monitoring: The real world changes, and so does the data that an AI encounters. “Data drift” happens when the characteristics of the real-world data start to differ significantly from the data the AI was originally trained on. Monitoring for data drift means continuously checking if the incoming data still matches what the AI expects, and if not, it’s a signal that the model might need retraining.
Read: AI Model Bias: How to Detect and Mitigate.
Model-Centric Evaluation
Once the data foundation is laid, the next step is to rigorously test the AI model itself.
- Offline Evaluation: This happens before the AI model is released into the wild. We use our carefully prepared test sets (data the model hasn’t seen during training) to assess its performance.
- Online Evaluation (A/B Testing, Shadow Mode): It’s time to test, but with a safety net.
- A/B Testing: This involves showing different versions of an AI model to different groups of users to see which one performs better in a live environment. It’s a direct comparison of real-world impact.
- Shadow Mode: Here, the new AI model runs “in the background” alongside the existing one. It processes live data and makes predictions, but its outputs aren’t actually used by users. This allows us to observe its real-world performance without any risk to the live system.
- Continuous Evaluation: AI systems are rarely “finished.” As data changes and user needs evolve, AI models need ongoing assessment. Continuous evaluation means regularly checking the AI’s performance in production, detecting any degradation, and identifying opportunities for improvement. It’s an iterative loop of monitoring, evaluating, and refining.
Human-in-the-Loop Evaluation
While automated tools are powerful, human insight remains invaluable, especially when dealing with the nuanced and subjective aspects of AI.
- Expert Review & Annotation: For certain AI outputs, particularly from generative AI (like creative writing or image generation), human experts are essential. They can assess qualities like creativity, fluency, and overall quality that are difficult for machines to quantify. This often involves annotating data or reviewing AI outputs for specific characteristics.
- User Feedback Integration: The ultimate test of any software, including AI, is how real users experience it. Incorporating user feedback – through surveys, bug reports, or direct interaction analysis – provides invaluable insights into the AI’s real-world utility, usability, and any unexpected issues.
- Crowdsourcing/Human-AI Teaming: For large-scale evaluation tasks, crowdsourcing platforms can be used to gather human judgments on AI outputs. In some scenarios, humans and AI can even work together, with the AI handling routine tasks and flagging complex cases for human review, creating a powerful “human-AI team” for evaluation.
Essential Metrics for AI Model Evaluation
AI eval involves using metrics to validate the AI model’s behavior. However, these metrics will vary depending on the type of AI model you’re working with. Here are some common examples.
Classification & Regression Models
These are common types of AI. Classification models sort things into categories (like “spam” or “not spam”), while regression models predict a numerical value (like a house price).
- Accuracy: This is the simplest one: what percentage of the time did the AI get it right? While it’s a good starting point, if your AI is trying to find a rare problem (like a specific disease), and it just says “no disease” every time, it might have high accuracy but be useless.
- Precision & Recall: These metrics help us understand where the AI might be going wrong.
- Precision tells us, “Out of all the times the AI said ‘yes’ (e.g., ‘this is spam’), how many of those were actually correct?” It’s important when false alarms are costly (like wrongly flagging an important email as spam).
- Recall asks, “Out of all the actual ‘yes’ cases (e.g., all the real spam emails), how many did the AI successfully find?” This is crucial when you absolutely cannot miss something important.
- F1-Score: Sometimes, you need a balance between Precision and Recall. The F1-Score combines them into a single number, giving you a balanced view of performance.
- Confusion Matrix: This is a table that visually breaks down all the AI’s predictions: how many it got right, how many false alarms it made, and how many real issues it missed. It’s a great way to see the full picture.
- ROC Curve and AUC: These are tools for understanding how well a classification AI can tell the difference between categories. The “Area Under the Curve” (AUC) gives you a single number to compare different AI models.
- RMSE (Root Mean Squared Error) and MAE (Mean Absolute Error): For regression tasks (predicting numbers), these tell you how far off the AI’s predictions typically are from the actual values. Lower numbers are better.
Natural Language Processing (NLP) and Generative AI
When AI works with language or creates new content, we need different ways to measure its quality:
- BLEU (Bilingual Evaluation Understudy): This metric is often used for things like machine translation. It compares the AI’s generated text to a human-written reference to see how similar they are.
- ROUGE (Recall-Oriented Understudy for Gisting Evaluation): Similar to BLEU, ROUGE is good for evaluating summaries or generated text by looking at how much overlap there is with reference texts.
- Perplexity: Imagine trying to guess the next word in a sentence. Perplexity measures how “surprised” the AI is by the actual next word. A lower perplexity means the AI is better at predicting and understanding language.
- Human-centric metrics: For generative AI, numbers aren’t enough. We often rely on human judgment to assess:
- Coherence: Does the generated text make sense and flow logically?
- Relevance: Is the content on topic and useful?
- Fluency: Does it sound natural, like a human wrote it?
- Creativity & Originality: Is the generated content novel and interesting, or just a rehash?
- Toxicity & Bias: Does the AI produce harmful, offensive, or biased content? This is crucial for responsible AI.
Computer Vision Models
When AI “sees” and interprets images or videos, we use metrics like:
- IoU (Intersection over Union): For tasks like object detection (e.g., finding cars in an image), IoU measures how much the AI’s predicted box around an object overlaps with the actual box. A higher overlap means a better detection.
- Precision, Recall, F1-Score: These are adapted from classification models to evaluate how well the AI identifies objects or categories within images.
- Mean Average Precision (mAP): This is a more advanced metric for object detection that averages precision across different levels of confidence, giving a comprehensive view of how well the AI finds and correctly identifies objects.
Fairness Metrics
These metrics help us detect and measure bias:
- Disparate Impact: This compares whether different groups (e.g., based on gender or ethnicity) receive favorable outcomes from the AI at similar rates. If one group is consistently favored, there’s a disparate impact.
- Equal Opportunity Difference: This checks if the AI has the same “true positive rate” (correctly identifying a positive outcome) for different groups. For example, is it equally good at diagnosing a disease for all demographics?
- Average Odds Difference: This goes a step further, looking at both false positive and false negative rates across different groups to ensure fairness in all types of errors.
AI Evaluation Metrics vs. Traditional Software Metrics
| Aspect | AI Evaluation Metrics | Traditional Software Metrics |
|---|---|---|
| Purpose | Measures how well an AI system performs tasks like prediction, classification, or decision-making. | Measures the efficiency, reliability, and functionality of software systems. |
| Examples | Accuracy, Precision, Recall, F1-Score, AUC, Confusion Matrix | Response time, Lines of Code, Functionality, Error Rate |
| Focus | Focuses on predictions, learning, and data patterns. | Focuses on system behavior, performance, and functionality. |
| Data Dependence | Highly dependent on large datasets for training and testing. | Less dependent on data; focuses on system operations and performance. |
| Optimization Goal | Aims to minimize error, increase prediction accuracy, or improve model learning. | Aims to optimize software performance, reduce bugs, or improve user experience. |
| Evaluation Complexity | Complex; often requires cross-validation, hyperparameter tuning, and advanced statistical methods. | Simpler; mostly involves straightforward performance benchmarks and testing. |
Evaluation of Artificial Intelligence: Best Practices
When it comes to setting up an effective AI evaluation system, keep the following in mind:
- Be clear in defining the evaluation objectives
- Use diverse and representative data for your models
- Don’t shy away from combining multiple evaluation metrics
- Use automation, but also maintain human oversight
- Keep an eye on AI performance in real-time
- Your system should provide transparency and explainability for the results
- Include a governance framework that uses regular audits, compliance checks, and accountability mechanisms
- Keep adapting your evaluation system as your AI evolves
Conclusion
If you want to build competent and high-quality AI applications, you must evaluate them thoroughly. Due to the high dependence on data and the unpredictable nature of these systems, include both manual and automated techniques throughout your AI application building process. This way, you can make sure that your application is trustworthy, fair, and safe.
Additional Resources
- Machine Learning Models Testing Strategies
- Machine Learning to Predict Test Failures
- What is Adversarial Testing of AI
- What is Metamorphic Testing of AI?
- What is Explainable AI (XAI)?
- How to use AI to test AI
- What are AI Hallucinations? How to Test?
- AI Context Explained: Why Context Matters in Artificial Intelligence
- What is AIOps?
- What is LLMOps?
- Top 10 OWASP for LLMs: How to Test?
| Achieve More Than 90% Test Automation | |
| Step by Step Walkthroughs and Help | |
| 14 Day Free Trial, Cancel Anytime |









