Zero-Shot vs. One-Shot vs. Few-Shot Learning: How to Test?
|
|
The AI systems you are building today aren’t just about processing data; they also need to understand context. Models like GPT, CLIP, DALL·E, and PaLM show the potential to extrapolate beyond their training data, that is, to do things that they were not directly shown. This can be accomplished through Zero-Shot, One-Shot, and Few-Shot Learning with less dependence on big labelled data and a move towards context-driven intelligence.

However, this leads to a complex problem: How to test these systems? Classical QA relies on the reproducibility of exact inputs and expectations; hereby presented models rely on adaptation, inference, and semantics. They must be tested under a new paradigm, the knowledge-reasoning-and-situational-accuracy paradigm.
| Key Takeaways: |
|---|
|
From Data Abundance to Data Efficiency
Traditional supervised learning algorithms need plenty of labeled data, and the more examples it has, the better their performance for maximum accuracy. Yet, this is a less effective and impractical technique in reality, where data is sparse, costly or time-varying. The drive for data-efficient learning has led to three distinct paradigms:
- Zero-Shot Learning (ZSL): The task of recognizing and predicting the unseen classes or the scenario that the model is not trained on, using both knowledge transfer and semantics understanding.
- One-Shot Learning (OSL): It refers to the acquisition of a new concept/class based on a single labeled example, i.e., efficiency in pattern recognition.
- Few-Shot Learning (FSL): It refers to the learning with few labeled images and generalizing well on unseen classes.
These approaches are all based on transfer learning, meta-learning, and embedding representations to mimic human-like reasoning, extracting invisible relations over known ones. We must not just perform technical testing, but also cognitive tests – making sure they perform the reasoning tasks they were designed for.
What is Zero-Shot Learning?
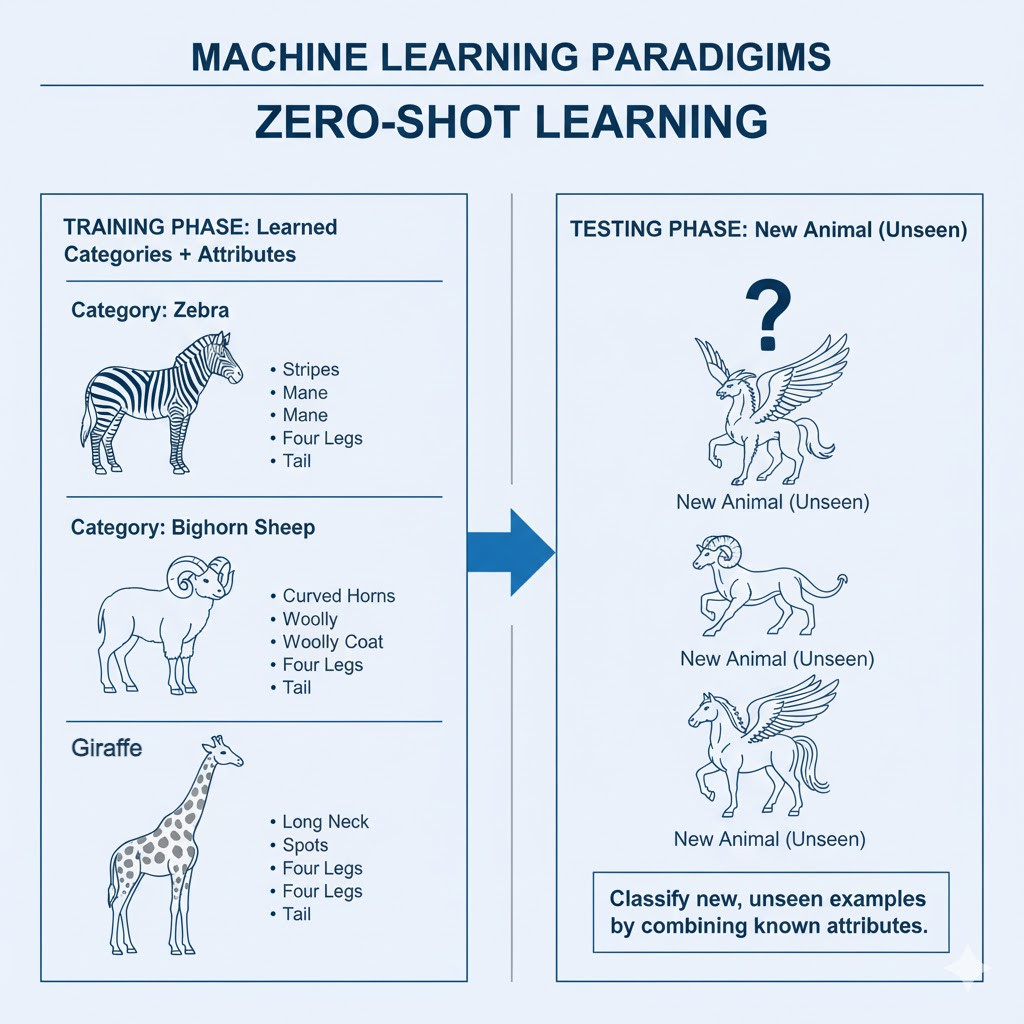
Zero-Shot Learning(ZSL) enables a model to identify or do things that it has not encountered in training. It does not memorize data-label pairs, but semantic relationships between known and unknown classes. To illustrate, a visual model that has been trained on the concepts of dogs and cats may be able to recognize a wolf as a wolf because it knows that it shares similar characteristics, such as fur texture, shape, and size. Equally, a language model has the ability to generalize linguistic patterns learned in one domain to summarize text in a new domain.
ZSL models usually rely on:
- Semantic Embeddings: Vector space representations of words, objects, or tasks.
- Associations of Attributes: Rational relationships such as a zebra has stripes or a violin is a string instrument.
- Mapping Functions: Acquired transformations between visual, textual, or conceptual representations.
Testing Zero-Shot Systems: Core Principles
Testing a Zero-Shot system requires assessing generalization and semantic alignment rather than accuracy alone.
-
Unseen-Class Evaluation: True zero-shot capability requires test data to have entirely unknown categories, i.e., those not seen during training. For example:
- The training lessons can be provided with the images of a lion, tiger, dog, and horse.
- Then, as test cases, we can provide zebras, giraffes, and cows.
Such an assumption would be invalidated by assessing overlap with previous training distributions. - Semantic Grounding: Every invisible category is linked to semantic features (e.g., zebra-striped, mammal, four-legged). Testers do not just test the accuracy of the model’s prediction but also its semantic similarity. When a model predicts a donkey on a query of zebra, QA must score partial correctness – semantically similar but not identical.
- Embedding Distance Validation: Quantitatively, QA calculates distances in the embedding space:
- Cosine similarity of predicted and ground-truth embeddings.
- Cluster coherence of invisible classes.
Shorter distances or smaller clusters are successful generalizations.
- Compositional Generalization: The compositional reasoning (combining familiar concepts into invisible ones) is commonly tested in ZSL models (e.g., red apple to green apple). QA constructs hybrid test samples in order to test compositional transferability.
- Human Evaluation for Semantic Fidelity: Humans verify if the predictions make any sense. When a model identifies an unknown object as an antelope, as opposed to a deer, testers assign a score to semantic proximity instead of assigning a binary error.
Tools like testRigor can validate Zero-Shot reasoning by using natural-language test cases that assess semantic alignment rather than strict label matching. Read more about Natural Language Processing for Software Testing.
Testing Scenarios
| Test Focus | Description | Expected Outcome |
|---|---|---|
| Attribute-based Reasoning | Testing if the model uses feature relations | Accurate reasoning across unseen attribute combinations |
| Text-to-Image Cross-generalization | Generating or classifying images from unseen text prompts | Logical, visually coherent outputs |
| Cross-domain Adaptation | Testing model trained on animals, evaluated on vehicles | Semantic transfer without performance collapse |
Testing ZSL thus becomes a multi-dimensional assessment of reasoning coherence and semantic adaptability.
What is One-Shot Learning?

At the other end of data efficiency is One-Shot Learning, in which a system learns to recognize or understand a new concept or task from only one example and generalizes that example to all future examples. This is analogous to the human ability to generalize across new objects or concepts given a single observation, which utilizes prior knowledge emphasized by very good feature extraction. This ability is needed in such areas as:
- Facial Recognition: Matching an image of an individual with one original encounter using visual characteristics. Read more about Images Testing Using AI – How To Guide.
- Medical Imaging: A very few medical samples will be available for training and accurate diagnosis of rare diseases from a single/multiple perspectives.
- Voice Recognition: Recognizing a speaker’s individual voice characteristics from a brief snippet of audio. Read more about How to do audio testing using testRigor?
One-Shot systems often use:
- Siamese Networks: Neural networks that contrast pairs of inputs to compute the similarity between them and infer if they come from the same class or not.
- Matching or Prototypical Networks: A model that generates class prototypes in embedding space, and classifies new examples according to the distance from these prototypes.
- Memory-Augmented Models: A class of neural networks including an external memory that can be read from and written to, geometrically similar to feedforward, that can dynamically store and retrieve information to base future decisions on.
How to Test One-Shot Learning Systems
Testing OSL involves measuring adaptation accuracy and representation robustness rather than classification rate alone.
- Support-Query Evaluation: In OSL testing, a single labeled support example (the “anchor”) defines a class. The model’s task is to correctly classify query samples based on their similarity to the support. Test design involves:
- Take a support example of each class randomly.
- Assess several query examples.
- Test on a large number of classes to obtain statistical validity.
- Similarity Threshold Testing: QA evaluates the behavior of embeddings to minor variations. A stable model should remain consistent in its class predictions even when realistic noise or minor changes are introduced.
- Temporal Retention Testing: The One-Shot systems should not forget the first instance. QA conducts delayed inference testing, which means testing the model to determine how it retains the single sample over time or task.
- Novelty vs. Familiarity Balance: When a system fits a single example, it is not generalizing. To balance recognition and generalization, testers construct contrastive sets of evaluation with similar but different samples.
- Human Validation: Human analysts make qualitative judgments about the model’s behavior, evaluating whether it captures the true intent or essence of an example rather than just its surface features. This helps to make sure that the model’s understanding aligns with the deeper meaning behind the data.
testRigor enables adaptive testing for One-Shot systems by allowing context-driven validation that adjusts automatically as models learn from single examples. Read more about How to use AI effectively in QA.
Measuring OSL Performance
| Evaluation Aspect | Description | Metric |
|---|---|---|
| Adaptation Speed | Accuracy gain after a single example | Learning efficiency curve |
| Embedding Cohesion | Distance consistency among similar classes | Cosine similarity variance |
| Noise Robustness | Stability under perturbations | Standard deviation across trials |
| Retention | Memory persistence across sessions | Accuracy decay rate |
What is Few-Shot Learning?

Few-Shot Learning is typically trained on many examples, but only a few (say, 2 to 100 for each class) are labeled. It balances flexibility and generalization, forming a cornerstone of modern meta-learning and prompt-based LLM behavior. This approach helps the models to rapidly adjust to new tasks with limited labeled data, which is critical in low-resource settings. It also helps modern AI systems generalize more effectively through contextual understanding and historical knowledge. Few-Shot Learning is essential in such areas as:
- Generative AI: Based on LLMs or diffusion models that are conditioned on a narrow context window to produce coherent and contextually relevant outputs. Read more about Generative AI in Software Testing.
- Healthcare: When patient data is limited, such as in rare cases, diagnostic models can still be trained to accurately predict results with minimal information.
- Autonomous Systems: Enable the machines to learn and adapt to new or changing environments with little or no initial adjustment. Read more about What is Autonomous Testing?
Few-shot models are trained on episodes – miniature tasks that simulate few-shot conditions during training. Each episode includes:
- Support set (small number of examples per class).
- A query set (test samples of such classes).
This is not to memorize but to learn to be able to adapt quickly to the tasks.
How to Test Few-Shot Systems
- Episodic Testing Structure: In FSL testing, episodes have the same form as used in training to ensure fairness and consistency. The model is evaluated across multiple testing episodes to measure how well it adapts to new examples. Its final performance score is calculated by averaging the generalization results from all episodes.
- Meta-Learning Validation: Many few-shot systems use some form of meta-learning for training models that are easily adapted to new tasks. Through QA validation, we are able to validate that these systems can adequately generalize to unseen tasks (cross-task generalization), learn each task independently without influencing others (task independence), and improve performance efficiently as more examples are introduced (adaptation curve).
- Robustness to Imbalanced Data: Few-shot cases generally showcase imbalanced class distributions; hence, fairness under imbalance QA makes sure that no class is a favored over others. This prevents the model from being biased towards majority classes and ensures equal representation of minority classes, hence making the model more reliable and generalizable.
- Prompt Sensitivity Testing (in LLMs): The effectiveness of prompts in the context of few-shot LLMs can vary widely based on their order, wording, and style. This is tested by reordering examples, adjusting the style of language, and measuring semantic drift to check for stability. Consistent performance across these variations indicates a robust and reliable model. Read: Prompt Engineering in QA and Software Testing.
- Contextual Drift Evaluation: Few-Shot models can deteriorate when there are changes in domain context (e.g. academic to casual text). QA testing simulates these changing contexts to test domain transferability.
With testRigor, QA teams can automate prompt variation and consistency checks across Few-Shot scenarios using plain-English test definitions.
Evaluating Few-Shot Model Performance
Testing should measure adaptation efficiency, contextual awareness, and learning trajectory.
| Dimension | Test Objective | Example |
|---|---|---|
| Cross-Domain Adaptability | Evaluate performance across domains | News → Legal text |
| Scalability | Measure improvement with increasing shots | 2-shot → 10-shot |
| Stability | Assess output consistency | Repeated episodes |
| Generalization Accuracy | Evaluate on unseen tasks | Novel category prediction |
Instead of static accuracy, testers use learning curves and contextual stability metrics to track evolution.
Zero-Shot vs. One-Shot vs. Few-Shot Learning
| Aspect | Zero-Shot Learning (ZSL) | One-Shot Learning (OSL) | Few-Shot Learning (FSL) |
|---|---|---|---|
| Definition | Model predicts unseen classes with no prior examples, relying on semantics and knowledge transfer. | Model learns from a single example to recognize or generalize new concepts. | Model learns from a few labeled samples (2-100) to adapt quickly to new tasks. |
| Learning Principle | Uses semantic embeddings and attribute associations for inference. | Uses similarity-based learning via Siamese or prototypical networks. | Uses meta-learning and episodic training to simulate real-world adaptability. |
| Primary Testing Goal | Assess generalization and semantic alignment to unseen categories. | Evaluate adaptation accuracy, embedding consistency, and memory retention. | Validate contextual adaptability, task scalability, and cross-domain robustness. |
| Key Evaluation Methods | Unseen-class evaluation, cosine similarity, and semantic coherence testing. | Support query validation, noise robustness checks, and temporal retention analysis. | Episodic validation, prompt sensitivity testing, and contextual drift analysis. |
| Common Use Cases | Image recognition of unseen objects, cross-domain NLP tasks, and reasoning-based AI. | Facial recognition, rare disease diagnosis, and voice identification. | Few-shot prompting in LLMs, low-resource translation, and adaptive autonomous systems. |
| Testing Focus | Semantic validation, human-in-the-loop evaluation, and reasoning accuracy. | Adaptive validation for single-instance learning and retention tracking. | Automated prompt variation and multi-domain consistency validation. |
Beyond Accuracy: The Multi-Dimensional Evaluation Matrix
Regarding Zero-Shot, One-Shot or Few-Shot Learning models, the evaluation is much more complicated than plain accuracy. Such systems need multidimensional assessment measures to evaluate their correctness in prediction by ensuring semantic appropriateness, consistency, interpretability and fairness. A complete QA approach guarantees that the models are technically and ethically “amount of data generalizable”.
testRigor supports multi-dimensional AI QA by executing semantic, consistency, and fairness validations without needing to modify underlying code or datasets.
Semantic Coherence
Semantic coherence checks whether the model’s predictions make semantic sense in context. For instance, misclassifying a bobcat as a lynx is semantically correct since these animals are similar. QA teams define semantic distance thresholds in the embedding space to determine how closely a model’s predictions align with real-world conceptual relationships.
Consistency Across Trials
In practice, few-shot models usually generate probabilistic outputs that can be different in multiple runs on the same dataset. For consistency evaluation, QA testing tests cross-seed variance and confidence calibration to detect whether the model is somehow aware of its uncertainty. Consistent and confident results across datasets imply reliability and generalization in real-world uses.
Explainability and Interpretability
Interpretability guarantees that the model’s logic is clear and understandable. QA validation tools, such as vision heatmap attention in image-based models and prompt attribution in NLP, can help us understand whether the predictions are grounded in meaningful patterns or spurious noise. This layer of inspection makes it possible to trust model decisions and increases debuggability.
Fairness and Bias Validation
The detection of bias is important since data-efficient models can magnify the biases that are in pretraining datasets. QA teams do inter-demographic analyses (e.g., by gender, ethnicity), cross-linguistic comparisons, and auditing for bias detection. These fairness evaluations provide both technical accuracy and ethical integrity for the system.
Building a Cognitive Testing Framework
In order to build reliable and accountable systems for the new technological realities of AI, testing needs to grow beyond a question of performance into questions of cognition and ethics. Such a cognitive testing framework is multi-layered for evaluating how models learn, adapt, reason, and act under uncertainty. This framework clusters the four dimensions of technical validity, semantic richness, cognitive adequacy, and ethical acceptability within a coherent quality approach.
- Layer 1 Structural Validation: This layer checks the consistency of data pipelines, embeddings, and model architecture. It tests whether the shapes and forms of embedding tensors are similar, and that no data leaks from seen to unseen sets.
- Layer 2 Semantic Evaluation: Semantic processing evaluates how well the model understands concepts, and not just memorization of data. It employs embedding distance metrics, category clustering, and ontology mapping for the meaningfulness and contextuality of knowledge representation.
- Layer 3 Cognitive Performance Testing: This layer assesses the model’s human-like adaptability and learning ability. It assesses how quickly a model can incorporate new information incrementally, tracking adaptation over iterations, and comparing its learning rate to target levels in human subjects.
- Layer 4 Ethical and Trust Evaluation: For the last layer, AI systems need to be transparent and fair as well as confidence-aware. It is about validating interpretability, verifying explainable reasoning, and calibrating uncertainty in the first place to ensure models are not only correct but beneficial.
Integrating Human-in-the-Loop Testing
Given the subjective nature of involved reasoning and contextual knowledge, ZSL, OSL, and FSL systems cannot be verified entirely automatically in many situations. Human-in-the-Loop (HITL) testing brings an essential layer of cognitive oversight into play, testing whether or not models are deep, fair, and come close to the real world.
HITL testing focuses on:
- Semantically ambiguous judgments.
- Evaluation of creative or reasoning-based outputs.
- Detection of social or ethical biases.
Human testers are cognitive auditors, checking model logic by contextual testing. The results of these audits can even re-educate or refine the evaluation system itself, forming a self-educating QA ecosystem. In Human-in-the-Loop workflows, testRigor complements human judgment by automating cognitive test scenarios and surfacing deviations for expert review.
Conclusion
Testing zero-shot, one-shot, and few-shot learning systems requires moving from deterministic accuracy to reasoning-based validation, semantic fidelity, and adaptability. Classical QA benchmarks must be adopted as cognitive testbeds that deliver cognition-based metrics to assess how models comprehend, reason, and generalize beyond their data.
Human-in-the-loop evaluation with multidimensional metrics can assess today’s systems, allowing testers to guarantee technical soundness and ethical trustworthiness. With solutions like testRigor, QA teams can automate semantic, context, and fairness checks, joining human-led reasoning with machine intelligence to achieve truly assured AI systems.
| Achieve More Than 90% Test Automation | |
| Step by Step Walkthroughs and Help | |
| 14 Day Free Trial, Cancel Anytime |









