What Is Big Data? Practical Examples and Benefits
|
|
Data has become a new oil in this age of information. These datasets take various forms, shapes, and sizes. Some are massive, complex, and fast-growing, and traditional data processing systems fail to handle them. This is what we call Big Data. It is not just about size but more about complexity, velocity, and the insights it provides when used correctly.
| Key Takeaways: |
|---|
|
This article will cover the following topics:
|
This article on big data explores the definition and working of big data, its advantages and provides real-world examples.
What is Big Data?
Big data refers to huge and complex datasets that traditional data processing tools find difficult to process.
These datasets require advanced analytical methods to extract hidden patterns, trends, and relationships. By analyzing big data, valuable insights are extracted that are used to improve decision-making, enhance business operations, and develop new products and services.
Big data is not just about the massive size of data, but also about its complexity and the speed at which it is generated and processed.
Characteristics of Big Data
Key big data characteristics are summarized as follows:
- Big data is a dataset that is extremely large and complex.
- These datasets grow rapidly over time and have an enormous scope.
- Structured, unstructured, and semi-structured are three possible types of big data.
- A few properties of big data are volume, velocity, variety, veracity, and value. Together, these are called the five Vs of big data.
- Big data helps improve data understanding, decision-making, customer service, and operational efficiency.
- Big data analytics is used in social media platforms, aircraft engines, and financial markets.
The 5 Vs of Big Data
Although big data definitions vary slightly, they are always described in terms of the five Vs first defined by Gartner in 2001.
The five Vs of big data are explained here.
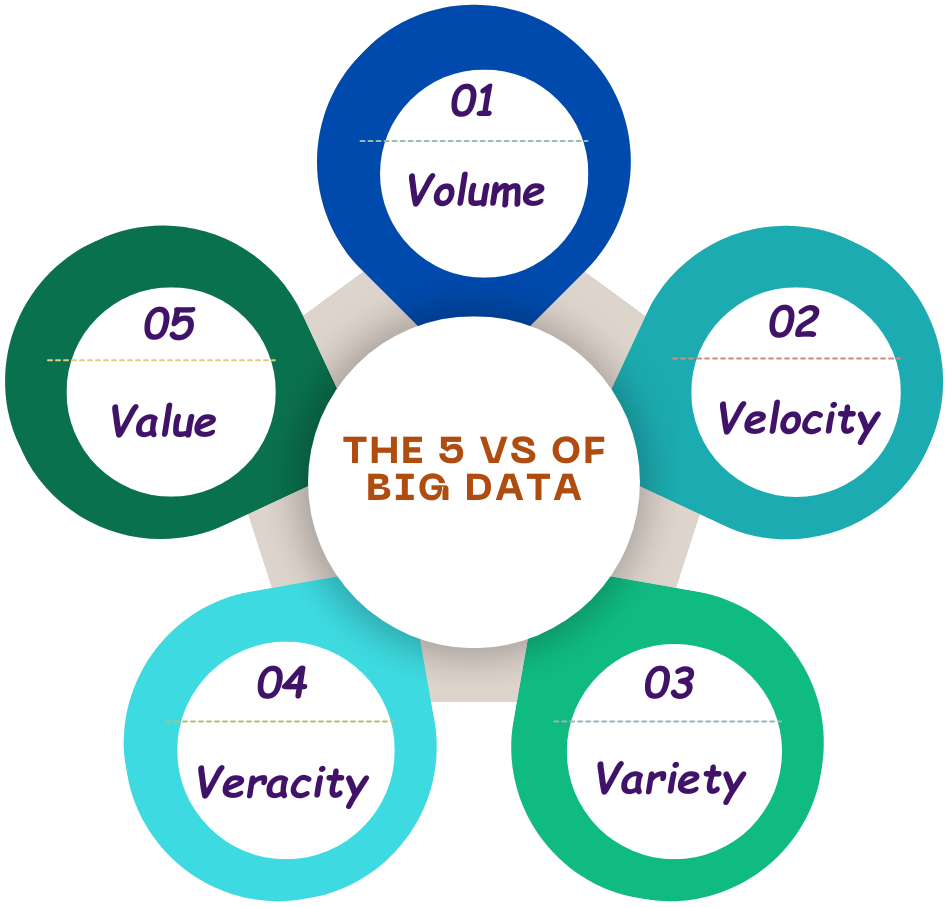
- Volume: This is the most common characteristic associated with big data. Volume describes the enormous amount of data that is available for collection from a variety of sources and devices on a continuous basis. Data can come from various sources, including customer contacts, sales transactions, invoices, bills, equipment sensors and performance readouts, market research, web traffic, documents, phone calls, emails, smart devices, GPS tracking systems, etc. The sheer scale of this data generated every second ranges from terabytes to zettabytes.
- Velocity: The speed of generating, collecting, and analyzing data in real-time represents the velocity of big data. Since the data today is often generated in real time or almost real time, it must also be processed, accessed, and analyzed at the same rate to have a meaningful impact. It is estimated that currently, 1.7 megabytes of data is generated per second by every person in the developed world.
- Variety: The collected data is in different formats, spreadsheets, database entries, text documents, voice and video recordings, images as well as structured, non-structured, or semi-structured. This variety of data results in the meaning of data that is constantly changing leading to inconsistency over time. They also include changes in context and interpretation, in addition to data collection methods. However, big data embraces all these data formats, as well as the variety of collection methods, contexts, and shifts in data.
- Veracity: This represents the quality and accuracy of data, which, in turn, determines its trustworthiness. Large datasets can be messy, noisy, and confusing, while smaller datasets may be incomplete. The higher the veracity of the dataset, the more trustworthy it is. Big data must be voluminous, varied, and accurate to be useful. Maintaining the veracity of big data is a challenge, as the quality of collected data can vary greatly depending on the source and the way it is stored and secured.
- Value: The business value of the data collected is crucial. It represents the potential insights, patterns, and benefits hidden within the data. Big data must contain the right and accurate data and should be analyzed effectively to yield insights that can be used for various purposes.
How does Big Data Work?
There are various techniques to manage very large datasets. One thing they have in common is that they provide ways to analyze enormous quantities of different types of data in order to extract hidden patterns. Once the patterns are extracted and analyzed, they can provide the basis for sound business decisions.
The main task for business managers is to learn how to put big data to work within their organization within the given timeframe and resources. The following steps are followed to develop a successful big data program within a business:
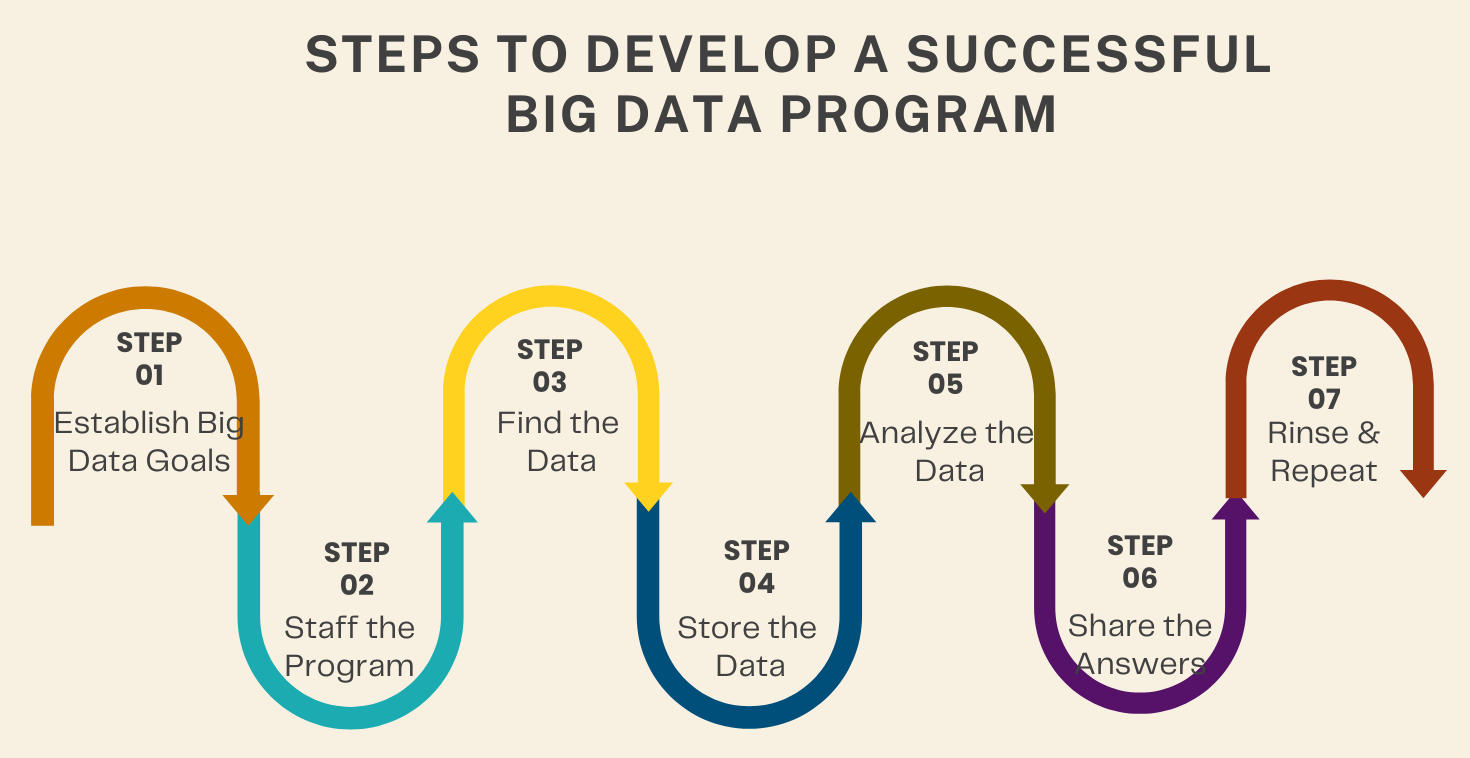
- Establish Big Data Goals: This means organizing the key questions that matter most to the business’s success, how the answers to these questions will add value, and how the analysis of big data will provide the answers.
- Staff the Program: Big data programs need a variety of expertise in technology and mathematics. They should be staffed with leaders who are proficient in statistics and know how to interpret them. They should also know how to recognize noise in the data or the incorrect application of a modeling technique that can cause untrustworthy results.
- Find the Data: Identify the type of data that will provide the most relevant answers to the key questions from step 1 and how it will be captured or acquired. Many valuable external datasets are available for purchase or provided free by nonprofits and governments. Find out if these are valuable and relevant to the key questions.
- Store the Data: Once data is finalized, it has to be gathered, stored, and retrieved so that its quality, consistency, and reliability is maintained. It should also be secured in a way that is consistent with government regulations and privacy standards.
- Analyze the Data: This step lets the statistics experts apply big data analytical models until they find insights that answer the key questions in step 1.
- Share the Answers: Automatically generate the results and share the most useful ones with all relevant stakeholders.
- Rinse and Repeat: Repeat steps 3 through 6 to refine your analysis and improve the insights.
Types of Big Data
Big data can be categorized into three major types:
- Structured Data: This type of big data is stored in fixed formats, such as spreadsheets and relational databases, organized in rows and columns. It is either numerical or standard text. Each data entry has an address and the column and row in which it appears. Structured data is relatively simple to track, map, and analyze, even when it is on a very large scale.
- Unstructured Data: When data is without a predefined model, such as emails, social media posts, and audio/video files, and is not standardized, it is termed unstructured data. This data is usually non-numeric and cannot be organized into rows and columns. It includes mobile texts, emails, Word documents, videos, and phone calls. Tracking and analyzing unstructured data is challenging and requires specialized tools like data lakes.
- Semi-structured Data: This type combines structured and unstructured data, such as XML or JSON documents. Web pages, Word documents, or emails that are highly formatted and organized by subject or topic are considered semi-structured data. Semi-structured data is not well-suited for relational databases. However, since it has some structure, it can be stored, mapped, or analyzed more efficiently than unstructured data.
Technologies Powering Big Data
Specialized technologies are required to store, process, and analyze big data. Here are the key technologies used:
- Hadoop Ecosystem: This open-source framework enables the distributed storage and processing of large datasets across clusters of computers. The Hadoop Distributed File System (HDFS), which is part of this framework, manages a large amount of data. Hadoop is scalable and ideal for organizations such as a phone company that must process massive amounts of data on a budget.
- Apache Spark is known for its speed and simplicity. It is a fast, in-memory data processing engine ideal for real-time analytics and excels in data mining, predictive analytics, and data science tasks. Organizations that require rapid data processing, such as live-stream analytics, use Apache Spark.
- NoSQL Databases: Non-relational databases like MongoDB and Cassandra are designed to handle unstructured data, and are a flexible choice for big data applications. NoSQL databases, such as document, key-value, and graph databases, scale horizontally. They are flexible and can store data that doesn’t fit neatly into tables. Read: How to do database testing using testRigor?
- Data Lakes: These are central repositories (like AWS Lake Formation, Azure Data Lake) used to store all data types.
- Cloud Platforms: Scalable infrastructure (AWS, Google Cloud, Azure) that enables cost-effective data storage and computation.
Real-World Examples of Big Data
Here are the real-world examples of Big Data:
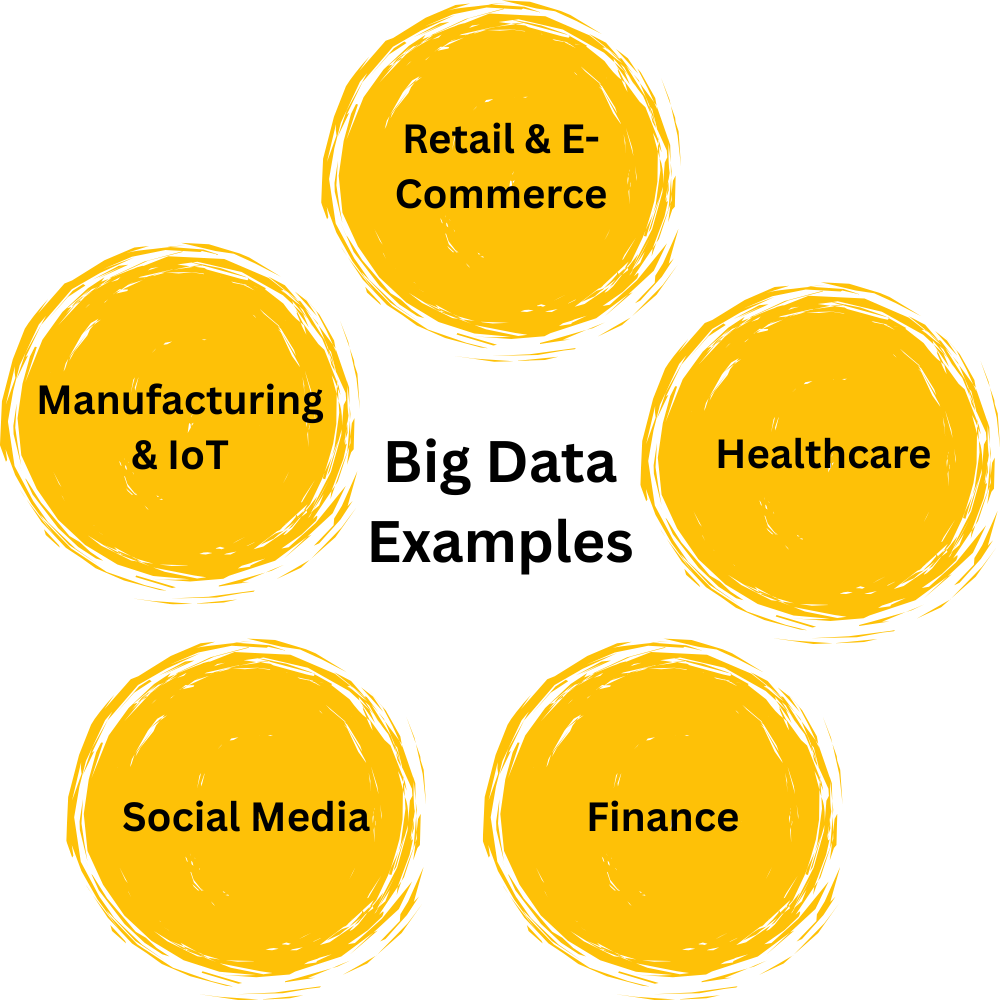
1. Retail & E-Commerce
Big data is used in retail and e-commerce to track customer behavior and purchase history. It also makes personal product recommendations using machine learning algorithms and optimizes inventory using predictive analytics. For example, Amazon displays personalized product suggestions using customer clickstream and purchasing data. This significantly increases conversion rates.
Retailers also use big data analytics to anticipate customer demand and launch new products. Read: E-Commerce Testing: Ensuring Seamless Shopping Experiences with AI.
2. Healthcare
Big Data enables the healthcare industry to improve patient diagnostics and outcomes through predictive modeling. It also helps with real-time monitoring using wearable devices. Hospitals use predictive analytics to reduce readmission rates, while medical platforms like 23andMe use genomic big data to identify and analyze health risks.
Numerous hospital data sources, such as electronic health records, patient wearable devices, and staffing data, can be combined internally with external data, including insurance records and disease studies, to optimize provider and patient experiences. Read: Healthcare Software Testing.
3. Finance
Banks and financial institutions rely on big data for fraud detection using real-time transaction monitoring. They also perform algorithmic trading based on market data patterns and credit scoring using alternative data points. For instance, PayPal uses big data and machine learning to detect suspicious activities in transactions.
Big data also helps identify data patterns that indicate fraud and aggregate large volumes of data to make regulatory reporting much faster. Read: Automated Testing in the Financial Sector: Challenges and Solutions.
4. Social Media
Social platforms use big data to analyze user behavior for ad targeting, tracking trends, hashtags, and viral content. It also uses big data to moderate content through natural language processing (NLP).
For example, Facebook’s New Feed algorithms process billions of signals daily using big data to personalize content for each user.
5. Manufacturing & IoT
Sensors are used in smart manufacturing to collect data from machines to predict equipment failures (predictive maintenance), optimize supply chains, and monitor environmental conditions in real time. IoT-based factories create data at massive scales, enabling more resilient, efficient operations.
Big data is also used to analyze potential issues before problems happen so that they can deploy maintenance more efficiently and cost-effectively. Read: IoT Automation Testing Guide: Examples and Tools.
Advantages of Big Data
The benefits of big data are as follows:
- Improved Decision-Making: Big data analytics provides insights that help organizations to make informed and data-driven decisions. For example, retailers can decide which products to discount or stock based on sales and browsing history.
- Operational Efficiency: Big data helps organizations to identify bottlenecks, optimize operations, reduce downtime, and improve supply chain transparency across various industries.
- Personalization and Customer Experience: Big data enables personalized experiences by analyzing customer preferences and behaviors from Netflix’s viewing recommendations to Spotify’s playlists. This leads to increased customer satisfaction and loyalty.
- Competitive Advantage: Big data can identify market trends, consumer needs, and product development opportunities faster than their competitors, giving them the required competitive advantage.
- Cost Reduction: Big data technologies like Hadoop and Apache Spark can store large volumes of data cost-effectively and process it faster than traditional processing systems. This leads to reduced infrastructure costs, waste, and improved fraud detection.
- Fraud Detection and Risk Management: By identifying patterns and anomalies in the data, big data analytics can detect fraud and high-risk behavior, thus enabling early intervention and mitigation.
- New Product and Service Development: Analyzing big data can identify unmet customer needs and emerging trends, leading to the development of new products and services.
- Scientific Discovery: Big data has revolutionized scientific research by enabling researchers to analyze enormous amounts of data to speed up medical, genomics, and climate science discoveries.
Challenges in Implementing Big Data
Despite its advantages, big data adoption poses several challenges:
- Data Privacy and Security: Large-scale data collection is responsible for complying with regulations like GDPR and HIPAA, as big data contains valuable business and customer information. This makes big data a high-value target for attackers. Because of its complexity and variety, it is a challenge to implement comprehensive strategies and policies to protect the datasets. Read: AI Compliance for Software.
- Data Quality and Management: Big data provides valuable insights and is useful as long as it is accurate and clean. Inconsistent, duplicate, or incomplete data leads to incorrect insights. Data quality directly affects the decision-making process, data analytics, and planning strategies.
- Integration Complexity: The integration of big data systems with legacy systems, cloud infrastructure, and databases is a time-consuming and complex process. Most organizations work with disparate data sources and making it accessible to business users is a challenge.
- Skill Gap: One of the most critical challenges in big data is the shortage of skilled data scientists and engineers. Lack of big data skills and expertise with advanced data tools results in a challenge in realizing value from big data environments.
- Speed of Data Growth: Big data is consistently rapidly changing and growing. A solid infrastructure should be in place to handle processing, storage, network, and security needs.
Future Trends in Big Data
Here are a few emerging trends in big data:
- AI and Machine Learning Integration: AI algorithms specially trained on large datasets will offer real-time insights.
- Edge Computing: As IoT devices generate massive volumes of data, processing it closer to the source (Edge computing) will reduce latency and bandwidth usage. Read: Edge AI vs. Cloud AI.
- Real-Time Analytics: Industries are moving to real-time analytics to respond to changing market conditions immediately.
- Data-as-a-Service (DaaS): A subscription model that enables smaller organizations to access enterprise-grade analytics is gaining popularity.
- Quantum Computing: Though in its infancy, quantum computing is poised to solve complex data problems beyond the scope of traditional computing. Read: What is Quantum AI?
Conclusion
Big data is a powerful driver of innovation, efficiency, and competitive advantage. From predicting patient outcomes in healthcare to optimising delivery routes in logistics, big data applications are limitless. As technologies innovate and mature, more data becomes available, and organizations successfully use big data to unlock new value and transform their operations.
While there are challenges around data privacy, quality, and infrastructure, the continued integration of AI, real-time analytics, and cloud computing points to big, indispensable data.
| Achieve More Than 90% Test Automation | |
| Step by Step Walkthroughs and Help | |
| 14 Day Free Trial, Cancel Anytime |









