What is Multimodal AI?
|
|
At present, technology doesn’t just read out text input or listen to voices. It can also grasp facial expressions and other details from its surroundings. Many generative AI tools, such as ChatGPT, use large language models (LLMs) to process text inputs and generate text outputs. These are all Unimodal AI models, which support only text input as the data source.
AI models that support more than one type of input source are Multimodal AI models. The input sources can be images, sounds, and words. Multimodal AI systems combine these types of inputs and generate an output. The output may also contain multiple types of outputs.These advanced models are the most promising trend in the current AI revolution. With their capacity to train on other data types along with text, these models learn new patterns and correlations between textual details and other data types.
Multimodal AI is widely used in retail stores as smart shopping assistants or customer service agents. It is also popular in healthcare systems as a healthcare assistant who can understand voice commands. In the subsequent sections, let’s explore multimodal AI further.
Key Takeaways:
- Multimodal Data Integration: Multimodal AI integrates different data types—text, audio, images, and more—into a single intelligent system.
- Beyond Unimodal Capabilities: It surpasses unimodal AI by enabling machines to interpret and generate multiple input/output formats simultaneously.
- Core AI Components: Multimodal AI includes deep learning, NLP, computer vision, and audio processing for comprehensive understanding.
- System Architecture Explained: A multimodal system typically involves input, fusion, and output modules working in tandem across data types.
- Leading AI Models: Popular models like GPT-4 Vision, Gemini, and DALL-E 3 exemplify real-world multimodal AI capabilities.
- Essential AI Tools: Advanced tools such as Google Gemini, Vertex AI, and Hugging Face Transformers support multimodal learning and applications.
- Diverse Industry Use Cases: They span customer support, quality control, advertising, robotics, AR/VR, and more, showcasing broad industry adoption.
- testRigor in Testing: testRigor demonstrates how multimodal AI can automate software testing using plain English and varied input formats.
What is Multimodal AI
Multimodal AI has specialized AI frameworks, which are the very foundation of it. These frameworks mainly consist of neural networks and deep learning models. They are used mainly to process and integrate multimodal data.
A typical multimodal AI system looks as follows:
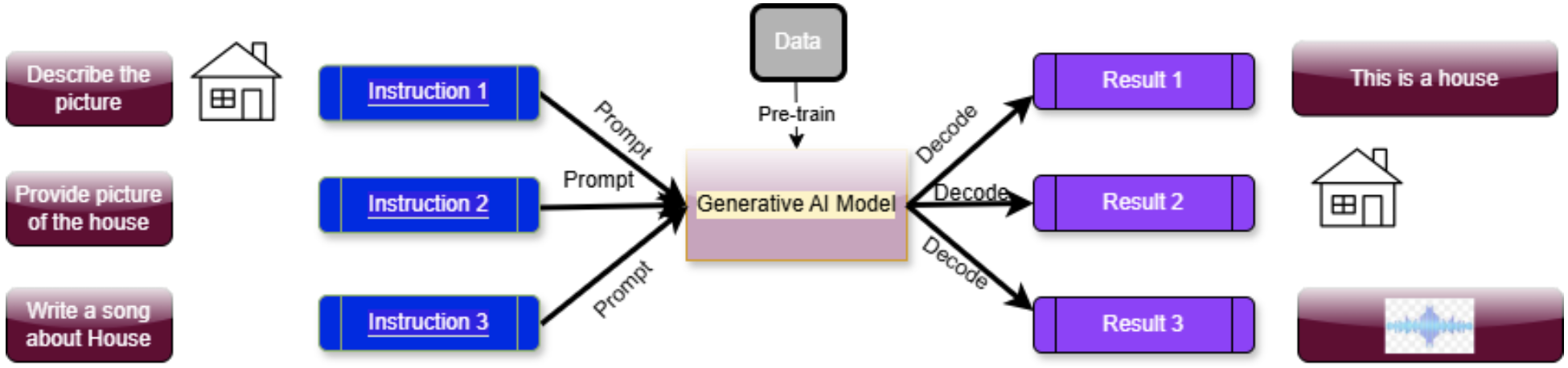
As seen in the above figure, more than one type of data is fed to the AI model for processing, and the output generated is also of more than one type. Unlike traditional AI systems, multimodal AI can perform complex facial recognition and voice interpretation tasks by analyzing multiple types of data. Also, unlike conventional AI systems that typically focus on a single data type, multimodal AI integrates and analyzes several different forms of data to generate more comprehensive, well-rounded, and accurate insights and responses. Combining various data sources allows multimodal AI to perform complex tasks using multiple points of context, such as voice interpretation with facial recognition, image analysis, and list scanning.
As seen in the above diagram, multimodal AI consists of the following modules:
- Input Module: The input module consists of various unimodal neural networks. Each of the unimodal distributions is responsible for a different type of data. In the above diagram, input data has three representations: picture, text, and audio.
- Fusion Module: Once the input module has collected all the data, the fusion model processes the information collected for each data type.
- Output Module: The output module is the final component responsible for delivering the results. Once again, in the above diagram, three types of representations are generated.
Thus, a multimodal AI system handles different inputs using multiple single-mode networks. It then integrates these inputs and generates the results depending on the input data. You can express multimodality in various ways:
- text-to-image
- text-to-audio
- audio-to-image
- all these combined (and text-to-text)
However, the operating principles used are similar regardless of particular modalities. Hence, one modality type can be generalized for others. With this knowledge of multimodal AI basics, let’s discuss the key components of multimodal AI.
Key Components of Multimodal AI
Multimodal AI contains accumulated knowledge of multiple subfields of AI. It deals with specific key components, as shown in the following figure.
Each of the above components is explained below.
Deep Learning
Deep Learning is a branch of AI that uses an algorithm known as an Artificial Neural Network (ANN). These models are particularly transformers and address complex tasks. They are trained on large datasets and identify features and relationships among the data, usually in text, audio, or even images. Deep Learning models work together in multimodal AI systems to collect data from different modalities.
Natural Language Processing (NLP)
NLP is another side of AI that effectively bridges the gap between human communication and computer understanding. With the aid of NLP, computers can interpret, analyze, and generate human language, allowing humans and machines to interact efficiently.
In NLP, the primary communication channel with the machine is text, which aids in the high performance of multimodal generative AI. NLP performs tasks like identifying keywords, analyzing sentence structure, and extracting information from text in the data. It supports both spoken and written communication. As NLP allows AI systems to comprehend and interpret human language and other data types such as images and audio, it plays a vital role in multimodal AI.
Computer Vision
Computer Vision, also known as Image Analysis, is a set of techniques by which computers can see and understand images. Using computer vision techniques, multimodal AI can develop models to process images and videos. Computer Vision usually processes visual data. Read: Vision AI and how testRigor uses it.
Audio Processing
The most advanced generative AI models, including multimodal AI, use audio data. Audio processing can perform a range of tasks, from interpreting voice messages to music creation and simultaneous translation.
Multimodal AI Examples
Examples of multimodal AI models currently in use are:
| Model Name | Description |
|---|---|
| GPT-4 Vision |
|
| Gemini |
|
| Inworld AI |
|
| Multimodal Transformer |
|
| Runway Gen-2 |
|
| Claude 3.5 Sonnet |
|
| Dall-E 3 |
|
| ImageBind |
|
Multimodal AI Tools
Several advanced tools are enhancing multimodal AI. These tools are:
| Tool | Description |
|---|---|
| Google Gemini |
|
| Vertex AI |
|
| OpenAI’s CLIP |
|
| Hugging Face’s Transformers |
|
Use Cases for Multimodal AI
As discussed, multimodal AI systems use models that collectively act on various data types, such as text, images, video, and audio. This data is then converted to output, in the form of text, images, video, and/or audio. As for testing, the multimodal system finds applications in various fields. Here are some of the use cases for a multimodal AI system that may be helpful.
Customer Experience and Support
Multimodal AI can analyze customer feedback, be it text, voice tone, or facial expressions, thus making communication between customer agents and customers more feasible. It can also employ chatbots for instantaneous support. Read: Chatbot Testing Using AI – How To Guide.
Quality Control
Multimodal AI can analyze visual data from photos or live cameras through sensors and audio data. It can also detect equipment failures early on, reducing the possibility of accidents. Equipment failures are detected by multimodal AI, which is used to reduce downtime and save costs.
Marketing and Advertising
In marketing and advertising, multimodal AI can help combine different data formats tailored to specific audiences. It can also create personalized ads that sync with customer opinions, effectively raising the bar for the industry.
Language Processing
Using a multimodal AI system, the system can identify signs of stress in the user’s voice or combine it with its facial expression showing anger to adjust responses as per customer needs. Also, combining the text responses with the sound of speech can help deal with pronunciation and foreign speech.
Robotics
As robots interact with real-world environments, including humans and pets, and other objects such as cars, buildings, and so on, multimodal AI plays a vital role in Robotics. This practically deals with all the significant data types since it uses data from cameras, microphones, GPS, and other sensors. Read: Maps or GIS Testing – How To Guide.
Augmented Reality (AR) and Virtual Reality (VR)
AR and VR are the two trending AI techniques today. Multimodal AI enables more intuitive, immersive, and interactive experiences, thus enhancing AR and VR. In AR, visual, spatial, and sensor data are combined, enabling natural interactions through voice, gestures, and touch. A multimodal system also improves object recognition in AR. Multimodal AI integrates voice, visual, and haptic feedback and creates a dynamic environment in VR that further enhances lifelike avatars. Read: Top 7 Visual Testing Tools for 2025.
So far, we have discussed multimodal AI in detail and understood its positive points. Let us now try to understand some of the challenges multimodal AI faces.
testRigor and AI
If we are talking about test automation, testRigor is an AI agent that has the capabilities to process different forms of input data. You can provide descriptions/requirements in plain English, and the test case is generated by the testRigor tool based on this description using generative AI. This tool’s extensive use of AI makes it much sought-after by organizations looking for automation. Read: AI In Software Testing.
You can test audio, video, graphs, images, chatbots, LLMs, Flutter apps, mainframes, and create tests using AI context. This is possible due to testRigor’s AI engine. Read more on this over here – AI Features Testing. It is able to process all these varied data types and generate tests and test results.
Also, since testRigor is an advanced AI agent, you can Use AI to test AI.
Challenges in Multimodal AI
Affordability is paramount when it comes to generative AI models, especially multimodal AI models. These models require computing resources, and the number is significant. Hence, the model becomes expensive. Secondly, data quality and interpretation of data in a multimodal AI model pose a challenge for developers. Apart from this, some of the difficulties in multimodal AI are listed as:
- Data Volume: The data involved in multimodal AI is vast and varied. This variety and amount challenge data quality, storage, and redundancy. Additionally, such huge data volumes are costly to process and store.
- Data Alignment: Meaningful data sources from multiple data types must be properly aligned. Aligning this data according to the same space and time is difficult.
- Limited Data Sets: Some data sets are not readily available and are also expensive to find. Also, some data, such as public data, is limited and difficult to source. This limited data poses a challenge for multimodal AI models.
- Missing Data: Multimodal AI uses data from different sources. However, if data is missing somewhere, it might result in AI malfunctions or misinterpretations. AI’s response to missing data, such as audio or unrecognized voices, is unknown.
- Decision-making Complexity: Decision-making in multimodal AI models is quite complex, as it is difficult for humans to interpret the trained data. Humans may fail to determine how new and unknown data may affect AI and decision-making. All these concerns make it difficult for multimodal AI to be unpredictable and unreliable.
- Data Availability: Training AI models on less conventional data types, such as temperature, hand movements, and so on, is difficult because such data is difficult to obtain.
Conclusion
Multimodal AI marks a transformative leap in the evolution of artificial intelligence by enabling machines to perceive, interpret, and respond to the world in a more human-like and context-aware manner. By seamlessly integrating data from various sources such as text, audio, images, and even sensory inputs, multimodal systems break the limitations of unimodal models and provide a richer, more holistic understanding of their environments.
Though there are certain challenges in operating this model, multimodal AI is growing popular daily.
| Achieve More Than 90% Test Automation | |
| Step by Step Walkthroughs and Help | |
| 14 Day Free Trial, Cancel Anytime |









