LLM Architecture: How Large Language Models Work
|
|
Ever pondered how ChatGPT, Bard, or Claude can troubleshoot code or resolve a legal query in a matter of mere seconds? Large language models (LLMs), which are huge neural networks that have subtly emerged as the driving force behind modern AI, power these systems in the background.
The issue is that even though the majority of us work with LLMs on a daily basis, either directly or through integration into apps. Very few truly understand how they are built or why they function so well. Although terms like “attention heads,” “transformer blocks,” and “positional encoding” are frequently used, what do they actually mean?
| Key Takeaways: |
|---|
|
Let us explore all of these in the blog below. Imagine this as your go-to guide for negotiating the fascinating (and occasionally daunting) domain of large language models.
What are Large Language Models?

Large language models are basically a type of neural network that has been trained on enormous volumes of textual data. They are able to forecast the most likely next token (word or subword) in a sequence by learning statistical patterns of language. When this simple process is replicated on a large scale, emergent skills like summarization, reasoning, and coding support are produced.
The scale of parameters is referred to as “large”, modern LLMs frequently have billions or even trillions of weights. They are able to capture complex connections between grammar, semantics, and even general knowledge due to this scale.
An explanation of large language models:
- Input: Tokens are created from the text (for example, “The cat” ->[“The”, “cat”]).
- Embedding: Dense vectors are built from tokens.
- Transformer Layers: Feed-forward networks enhance token representations, while multi-head self-attention documents contextual relationships.
- Output: The model samples or selects the most probable option based on the probabilities generated for the subsequent token.
How do Large Language Models Work?
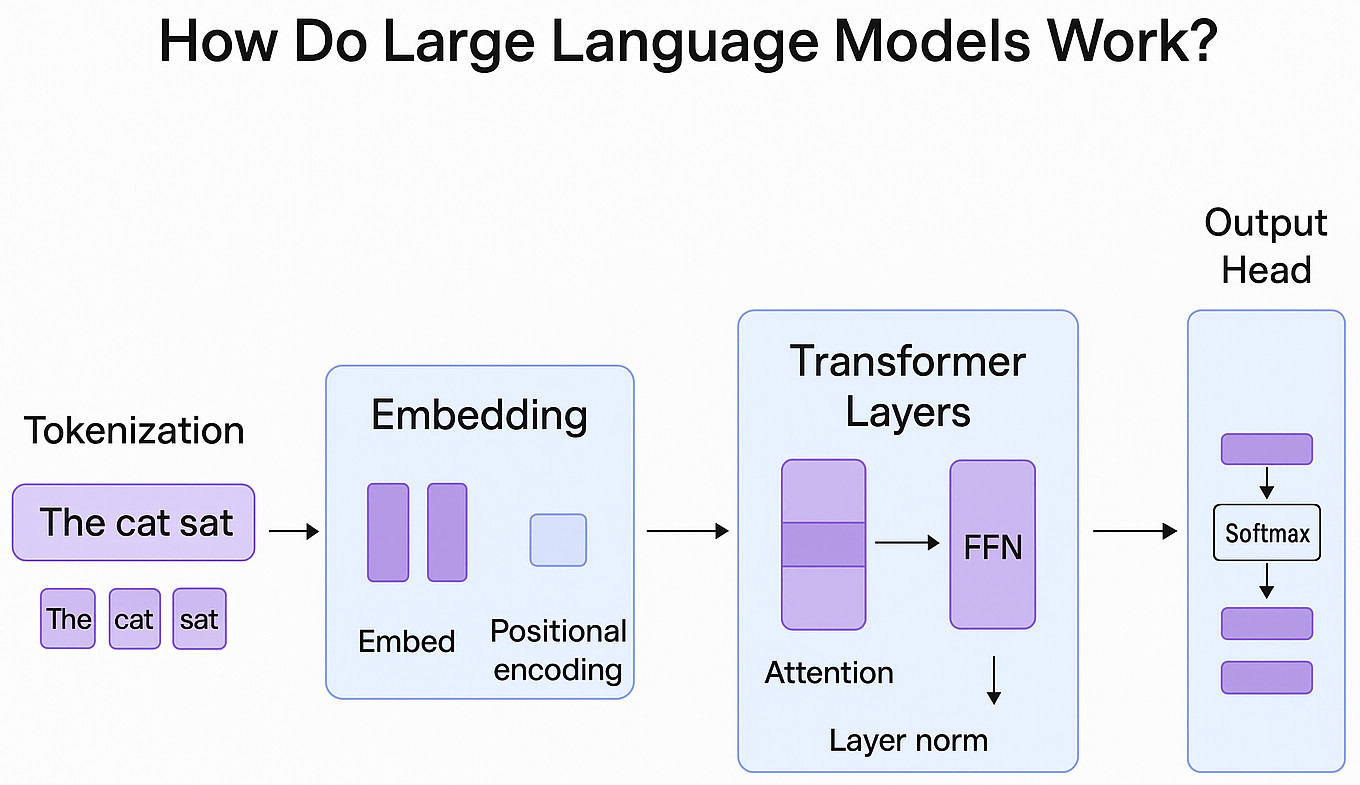
The transformer architecture, which was first introduced in 2017, powers LLMs. The self-attention mechanism, the transformer’s ground-breaking concept, helps the model to simultaneously evaluate the relationships between each token in a sequence. This differs from existing sequential models that had trouble with long-range dependencies, such as LSTMs or RNNs.
Key Components Include:
- Tokenization: It is the method of dividing text into manageable subword units.
- Positional Encoding: To aid the model understand sequence structure, positional signals are added because attention has no sense of order.
- Attention Heads: Multiple attention heads simultaneously record various context-related elements.
- Residual Connections and Layer Normalization: Maintain learning in deep stacks of transformer blocks.
- Output Layer: Generates probability distributions across the vocabulary.
In practice, deep contextual understanding is made possible by the hundreds of transformer layers that may be stacked together in an LLM.
The Anatomy of LLM Architecture
The LLM architecture is modular in nature, with each component adding to the system’s overall intelligence.
- Embedding Layer: Discrete token IDs are transformed into continuous vectors by the embedding layer. Embeddings often share parameters with the output layer (weight tying) and can be pretrained or fine-tuned.
- Stacked Transformer Blocks: A dozen to several hundred transformer blocks may be utilized by modern LLMs. The richness of the hierarchical abstractions (from abstract reasoning to word-level grammar) increases with stack depth.
- Attention Scaling: To reduce computational costs while maintaining context handling, some LLMs use variations like Mixture-of-Experts (MoE) layers, sparse attention, or local attention windows.
- Normalization Techniques: Architectures differ in whether they use post-norm (normalizations following sublayers) or pre-norm (normalization before sublayers). Pre-norm is common in GPT-style models and is more stable for deep networks.
- Training Goals: Architecture is governed by training objectives.
- Decoder-only (GPT) for generation
- Encoder-only (BERT) for understanding
- Encoder-decoder for sequence-to-sequence tasks (T5, BART).
An LLM architecture is best described as a diagram that appears to be a flow from tokens to embeddings, then to transformer layers, logits, and finally to Softmax output. The details, however, are critical because positional encoding techniques, scaling strategies, and activation decisions regularly differentiate a state-of-the-art model from a mediocre one.
LLM Comparison: Different Models
While the transformer backbone is shared by all LLMs, there are some important variations:
- GPT Family (OpenAI): Text-generation-optimized, autoregressive.
- BERT Family (Google): Masked language modeling, optimized for understanding.
- T5/UL2 (Google): This encoder-decoder is built for a range of text-to-text applications.
- LLaMA/Mistral (Meta, open-source): Efficient, lightweight models for deployment and study/
- Claude (Anthropic) and Gemini (Google DeepMind): Proprietary models that prioritize alignment and multimodality.
Every model strives to strike a balance between scale, efficiency, and training data. Regardless of whether speed, accuracy, interpretability, or cost are the top priorities, this LLM comparison is vital when choosing a model for enterprise use.
Multimodal LLM Architecture
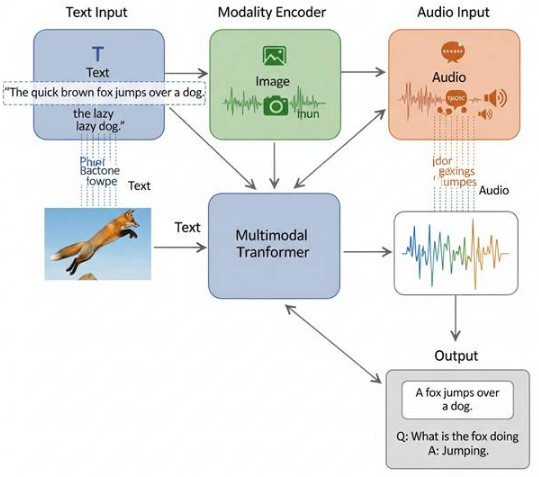
AI assistants of the future are just capable of speaking, they can “see,” “hear,” and “understand” in a number of ways.
The transformer backbone is extended by the multimodal LLM architecture to include non-text inputs:
- Images: These can be encoded using Vision Transformers (ViTs), convolutional neural networks (CNNs), or CLIP-style encoders, which map images into a joint embedding space with text.
- Audio: Processed via wav2vec-like models or spectrogram-based encoders that present sound as text-like sequences.
- Video: To manage frames and motion, both spatial and temporal encoders are required. ViTs and temporal transformers are often combined.
Data is projected into a shared latent space by these modality-specific encoders. The multimodal embeddings are fed into the central transformer backbone after they have been aligned. This allows the model to respond to queries such as:
- “Explain this image of a cat sitting on a laptop.”
- “Generate code based on this screenshot of the user interface.”
- “Summarize the key points of this meeting that were recorded.”
Multimodal LLMs have massive practical applications, including fueling AI copilots for design, visual question responding, medical imaging diagnostics, and even robotic agents that integrate perception and reasoning.
Practical Applications of LLMs
Industries are already being modified by LLMs:
- Customer Service: Context-aware automated responses.
- Content Creation: Creating technical documentation, blogs, and marketing copies.
- Coding Assistants: Writing tests, fixing bugs, and suggesting completions.
- Healthcare: Summarizing medical records or offering evidence for a diagnosis.
- Legal and Finance: Contract drafting and regulatory document analysis.
The same basic ability of flexibility, context-aware language generation, underlies the wide range of LLM applications.
From Research to Practice: LLM Implementation
There are different ways for practitioners to deploy LLMs:
LLM Implementation of LLM
With libraries like Hugging Face Transformers, PyTorch, and TensorFlow providing pretrained models and training tools, Python is the most prominent ecosystem. Tokenizing input, loading a model with transformers, and performing inference could be the steps of a typical Python LLM implementation.
Implementing LLM from the Ground Up
Many developers and researchers try to implement LLM from scratch for learning purposes, coding simplified transformers (like nanoGPT). Deep intuition related to optimization, attention, and embeddings is developed as a consequence.
Retrieval-Augmented Generation (RAG)
It is a useful technique for strongly establishing LLMs in external knowledge. The model retrieves documents from a vector database and conditions its generation on them instead of depending only on parameters. RAG keeps deployments light while boosting factual accuracy. Read: Retrieval Augmented Generation (RAG) vs. AI Agents.
Implementation of LLM Agents
LLM agents integrate models with reasoning loops, tool use, and memory in addition to text completion. In order to call APIs, modify outputs, and carry out actions in accordance with goals, an LLM agent implementation often integrates planning frameworks (LangChain, Haystack). Read: Why Do LLMs Need ETL Testing?
Deployment Challenges and Optimization
It takes more than just running a model on a laptop to implement an LLM. Scalability, dependability, latency, and cost must all be balanced in real-world deployments.
Latency Bottlenecks
Latency increases with response length because autoregressive models deliver text one token at a time. Even a few seconds of latency can negatively affect the user experience for enterprise-grade chatbots. Prefill + cache strategies and speculative decoding, which utilize smaller models to guess multiple tokens at once, are two solutions.
Memory Requirements
For inference, a model with 65 billion parameters may need hundreds of gigabytes of VRAM. The footprint is reduced by processes such as offloading weights to CPU/SSD and quantization (e.g., FP16, INT8, or INT4 precision).
Scaling across Hardware
Model parallelism, or segregating models across multiple GPUs, and data parallelism, or efficiently distributing data, are necessary for training. While frameworks such as Megatron-LM and DeepSpeed provide sharding strategies, pipeline parallelism breaks layers across devices.
Cost Optimization
It costs a lot of money to execute large models in production. Lightweight deployments that maintain performance for specific use cases are made possible by strategies such as pruning, knowledge distillation, and LoRA adapters.
Testing and Safety
LLMs are non-deterministic. Automated testing frameworks are required to make sure they operate consistently across updates (this is where tools like testRigor can play a pivotal role). Deployment pipelines should include guardrails such as prompt filtering, moderation layers, and assessment against safety standards.
LLM deployment issues are necessarily not just technical; governance, monitoring, and lifecycle management are also involved.
Responsible AI and Testing in LLM Deployments
With great power comes great responsibility. LLMs may deliver unsafe, biased, or inaccurate results. Because of this, testing and validation are necessary before enterprise deployment. Unlike traditional software, LLMs are probabilistic. They may experience hallucinations, and their behavior can vary from run to run. Testing must thus concentrate on:
- Functional Testing: Making sure outputs meet the expected format.
- Performance Testing: Measuring latency while under load.
- Robustness Testing: Examining against adversarial prompts.
- Regression Testing: Measuring consistency across model updates.
AI-Powered Testing Automation With testRigor
testRigor and other AI-powered testing automation tools are necessary in this situation. Organizations implementing LLMs must ensure that deployments are reliable, secure, and in line with business needs. Read: Top 10 Generative AI-Based Software Testing Tools.
How testRigor Helps in LLM Testing:
- Automated Functional Testing: Validates that applications with LLM integration function as expected across user flows.
- Regression Coverage: Ensures that important features won’t be impacted by model or infrastructure updates.
- Gen AI-powered Testing: testRigor is the ideal fit for LLM-driven environments because it builds tests using natural language instructions, in comparison to rigid script-based frameworks. Read: Generative AI in Software Testing.
- Scalability: Manages the complexity of multi-layered systems, of which LLMs are just one element.
You can boost your confidence by combining testRigor into your deployment pipeline. This ensures that your model generates logical outputs and that your entire system works as designed in real-world scenarios, right from APIs to user interfaces. Read: AI Assistants vs AI Agents: How to Test?
The Future of LLMs
A number of new frontiers are emerging as the LLM architecture evolves fast:
- Long-context Models: The cost of 100k+ token windows is high because conventional transformers scale quadratically with sequence length. Models are now capable of handling lengthy conversations or books due to innovative techniques like memory-scaled architecture, linear attention, and sparse transformers.
- Mixture-of-Experts (MoE): MoE models accomplish massive scale (trillions of parameters) without correspondingly increasing compute per inference by directing tokens through specialized experts rather than activating all parameters for each input.
- Multimodality as Default: Text, photos, video, audio, and structured data will mostly all be natively integrated into future LLMs. This will allow agents to easily explain videos, edit designs, and analyze financial charts. Read: What is Multimodal AI?
- On-device Inference: The race is to compress models small enough for smartphones and edge devices. Users may soon be able to execute competent assistants without depending on the cloud due to the developments in distillation and quantization.
- Agents and Autonomy: Reasoning loops, tool APIs, and memory systems are being added to LLMs more often in order to develop LLM agents that are able to do tasks on their own. Consider handling travel planning, expense reporting, and support ticket triage without requiring human intervention. Read: Top 10 OWASP for LLMs: How to Test?
- Evaluation and Safety: The potential of misuse increases with capabilities. Anticipate the emergence of more detailed benchmarks that examine reasoning, ethics, robustness, and factual foundation (beyond MMLU and BIG-Bench). Continuous monitoring will be as critical as training itself.
To put it in simpler terms, the future of LLMs suggests increased autonomy, effectively, multimodality, and a wider-context, but also more strict standards for deployment safety and transparency. The best-positioned organizations to responsibly embrace these innovations will be those that integrate innovation with test automation.
Conclusion
Large language models are simply transformers that predict the next token. Tokenization, attention layers, embeddings, and deployment strategies are all key components of the intricate engineering that goes into the LLM architecture. The same idea holds true whether you are deploying a RAG LLM implementation, examining multimodal LLM architecture, or experimenting with a Python LLM implementation: dependability and performance must be balanced.
Strong testing pipelines will also be needed for organizations that responsibly adopt AI. One distinct way to ensure that LLM-powered systems meet business needs while reducing the risks associated with deploying untested AI is via intelligent testing with tools such as testRigor.
LLMs have a strong and bright future, and organizations can safely and successfully reach their full potential if they have the right architecture, implementation plans, and testing frameworks in place.
| Achieve More Than 90% Test Automation | |
| Step by Step Walkthroughs and Help | |
| 14 Day Free Trial, Cancel Anytime |









