Strategies and Best Practices for Dealing with a QA Crisis
|
|
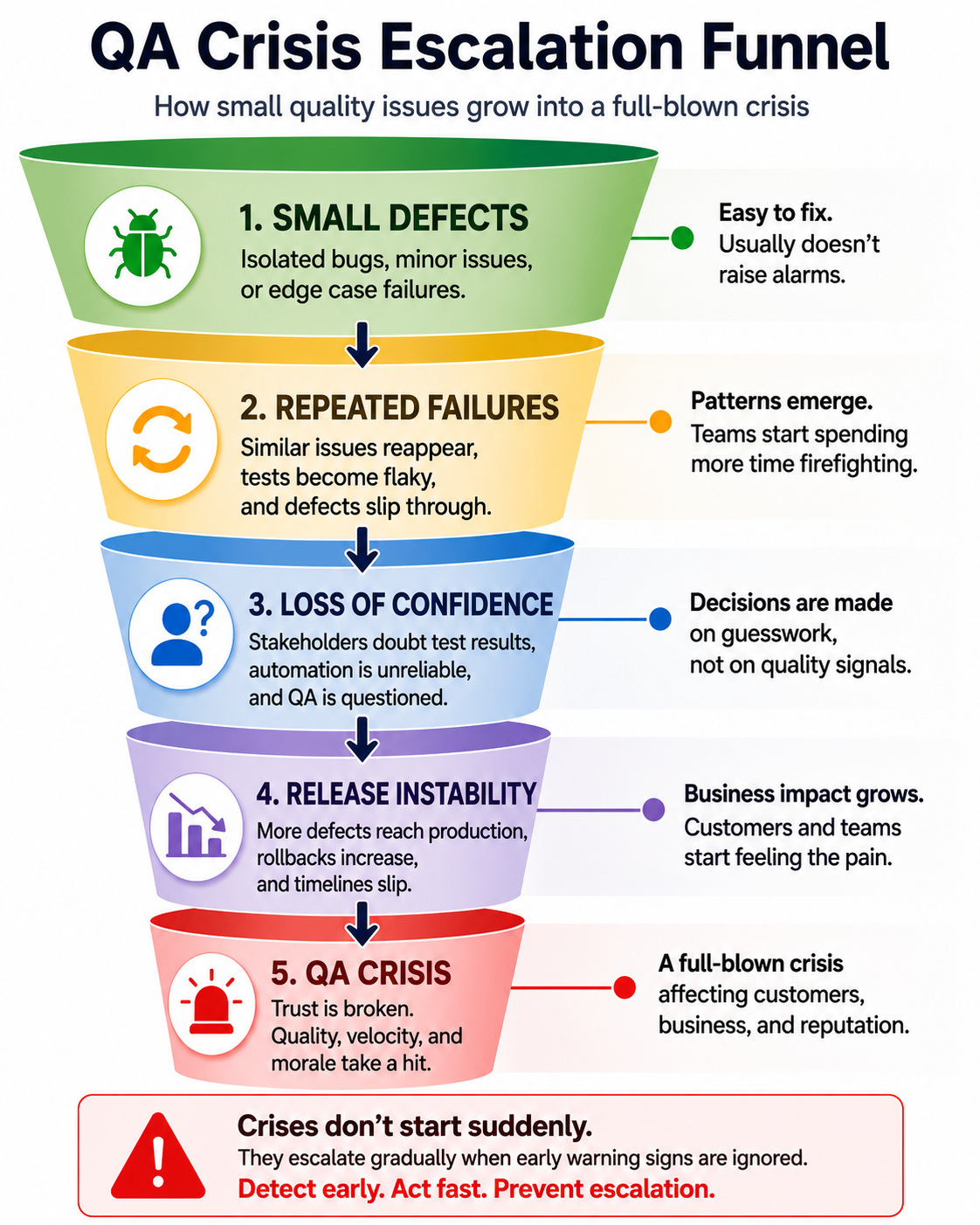
A moment that many QA leaders recognize. A release that feels different than the rest. An issue pops up shortly after the deployment. It is followed by another issue. All of a sudden, the team, which was progressing confidently through the sprint goals, stumbles and starts spending excessive time on emergency calls and defect discussions.
Only one bug never leads to this scenario; there are many.
People start losing confidence in the process.
Developers are wary of the test results. Product teams double-check and hesitate before approving any releases. Automation suddenly appears to be inefficient and untrustworthy, as more than half of the failures need to be investigated before anyone understands whether they highlight real problems. Manual testers start rechecking scenarios they thought they had already tested.
At that moment, the organization is no longer dealing with isolated anomalies. It is dealing with a QA crisis.
For QA leads and managers, this leads to an entirely different challenge. The goal is not limited to simply solving issues. It is to restore predictability, rebuild trust in QA processes, and help teams to progress out of the reactive mode.
| Key Takeaways: |
|---|
|
What is a QA Crisis?
Not every defect or bug is a QA crisis. It is the moment where an issue or failure is massive enough to impact customer trust, business revenue, or the reputation of the team responsible for quality.
While such scenarios may look out of the blue from the outside, that is rarely the case. Such conditions are almost always a result of slow buildup over time.
QA crises are often categorized into three broad categories. Each of these has its own consequences, pressure, and trends. They are:
Production Crisis
These are most visible and demand immediate resolution.
A deployment takes place, dashboards fire up, and customers experience failures. The entire organization switches to firefighting mode. Production failures escalate immediately because the impact is immediate and catastrophic.
Production crises often lead to critical bugs impacting end users, rollback of failed releases, observing cascading failures in distributed systems, performance drift under load, and data integrity loss or issues.
These incidents often overhaul the manner in which organizations consider quality.
Security and Compliance Crisis
The system does not crash at every crisis. Some expose the organization to risk in a silent manner, e.g., an unpatched library, a misconfigured API gateway, unregulated access control, or an unintentional but risky privacy loophole due to a management decision.
Security and compliance failures are often way more hazardous due to their long-lasting impact, which goes far beyond engineering. Security breaches become costlier the longer they go undetected.
Exploitable vulnerabilities in production, unauthorized access, data breaches, compliance failures, privacy violations, or audit issues needing immediate resolution are all examples of how security and compliance crises manifest.
Security crises differ from production crashes because they persist. Even after a regulatory resolution, the regulatory and reputational damage takes years to rectify.
Organizational Crisis
Certain crises were initiated long before the defect sneaked into production. These scale silently inside teams, culture, or processes. Organizational crises don’t show up as an alert like production crises. Rather, they are observed as exhaustion, friction, increased mistrust, or missed deadlines.
These crises are due to quality issues overwhelming people and not just systems. Delayed launch dates due to late-detected defects, high volume of defects, loss of key QA people at critical moments, loss of stakeholder trust, or QA authority being overridden by pressure are all common examples of organizational crises.
Once trust is lost or quality shortcuts become a habit, the team is primed to face bigger failures later. Such crises are lethal because they reshape culture.
Read: QA’s Role in the Full SDLC – Beyond Just STLC.
Why Teams Often Make the Situation Worse
When pressure starts building, organizations frequently react in unpredictable ways.
One of the most common responses is escalating testing volume. Leadership wrongly assumes that additional testing automatically creates additional confidence.
Theoretically, that sounds reasonable.
In reality, teams sometimes create hundreds of additional automated checks without asking whether those validations provide useful information.
Within a few weeks, regression suites become larger and slower. Execution times increase. Failures increase. Engineers spend more time investigating tests than validating product behavior.
test('User can complete payment process', async () => {
await login();
await addItemsToCart();
await proceedToCheckout();
await enterPaymentDetails();
await submitPayment();
expect(successMessage()).toBeVisible();
});
At first glance, this looks perfectly acceptable.
Now imagine this test failing intermittently because the payment gateway occasionally responds slowly.
After repeated failures, teams often start rerunning pipelines rather than analyzing them. Finally, people stop trusting the test entirely. The issue is no longer automation. The issue is confidence.
Once trust in QA metrics begins to decline, teams start making decisions based on assumptions instead of evidence.
Read: Quality as Code: Defining Quality in Infrastructure & Automation for Modern QE.
Strategies for Managing an Active QA Crisis
Let us have a look at the strategies we can follow to manage a QA crisis.
Shift the Conversation from Defects to Business Risk
When a QA crisis starts, most conversations immediately revolve around defect counts. Teams start asking how many bugs remain open or how many failures appeared during regression testing.
The problem is that defect volume by itself rarely helps teams make better decisions.
A product may contain dozens of open issues, but not all of them create the same level of risk. A reporting issue and a payment failure don’t deserve equal attention simply because both are categorized as defects.
Instead of asking: “How many bugs do we have?”
QA leaders should begin asking: “Which failures create the highest business impact?”
For example, an e-commerce platform may have issues related to profile updates, UI inconsistencies, and analytics reporting while also experiencing failures in checkout processing. While multiple problems exist, the checkout flow deserves immediate attention as it directly impacts revenue and customer trust.
Risk-based testing helps teams focus energy where it matters most.
Introduce Structure Before Increasing Speed
A common reaction during a QA crisis is increasing effort across all areas simultaneously. Teams begin juggling emergency fixes, feature development, regression activities, and production incidents simultaneously.
Sooner or later, constant context switching starts decreasing productivity. Pushing harder does not always create better outcomes.
Short-term stabilization periods often help teams regain control. This may include temporarily slowing feature delivery and focusing on critical fixes, release confidence, and high-risk workflows.
The goal is not to reduce progress. The goal is to reduce chaos.
Create Clear and Actionable Communication
Many quality issues become larger because different teams work with different assumptions.
Developers may believe a problem is settled because local testing passed. QA teams may still see inconsistent results during regression testing. Product stakeholders may assume release timelines remain the same because no major concerns were raised explicitly.
Communication becomes especially important during these moments.
Instead of saying: “Testing is still ongoing.”
Provide specific information: “Authentication and payment scenarios finished validation successfully. Mobile checkout still has unresolved failures needing additional investigation.”
Clear communication eliminates ambiguity and helps stakeholders make informed release decisions.
Read: How to Effectively Communicate Quality to Stakeholders?
QA Crisis Severity Framework
As previously explained, not all defects need the same level of response. One of the biggest mistakes teams make is treating every defect as urgent. When everything becomes a priority, teams quickly lose focus, and decision-making slows down.
A practical severity framework helps QA leaders decide when to escalate, when to stabilize, and when normal workflows remain sufficient.
| Severity | QA Impact | Typical Indicators | Leadership Response |
|---|---|---|---|
| Level 1: Critical Crisis | Core business workflows or production stability are severely affected | Login failures across most users, payment processing failures, widespread production outages, data corruption, and security incidents | Immediate response. Notify the incident channel or war room, involve engineering leadership, QA leads, DevOps, and stakeholders. Continuous monitoring is required until stabilization |
| Level 2: High-Risk Crisis | Major functionality degradation with significant user impact | Failed integrations, repeated checkout errors in certain regions, automation failures masking production issues, and large regression failures before release | Activate the rapid triage process, prioritize high-risk workflows, communicate updates frequently, and calculate release delays |
| Level 3: Moderate Quality Risk | Functionality issues exist, but business operations continue | Feature instability affecting subsets of users, increasing defect leakage, recurring test failures with available workarounds | Investigate root causes, prioritize fixes within sprint cycles, and monitor quality trends closely |
| Level 4: Low-Level Quality Concern | Limited operational impact with low customer disruption | UI inconsistencies, minor usability defects, documentation gaps, isolated test failures | Resolve through standard development and QA workflows without escalation |
The purpose of this framework is not simply to categorize defects. It helps teams line up response efforts with business impact. A cosmetic issue should not use the same resources as a payment failure, and a localized feature problem should not immediately trigger crisis procedures.
For QA managers, severity classification becomes valuable because it makes sure of consistency in decision-making during high-pressure situations. Instead of reacting emotionally to defects, teams can respond based on impact, risk, and urgency.
Best Practices for Building a Sustainable QA Process
Let us review the best practices to follow while building a sustainable QA process against a QA crisis.
Bring QA into Discussions Earlier
Most quality issues do not begin during testing. They begin much earlier, during requirement discussions and planning sessions. Teams often treat QA as a downstream activity that starts after development is complete. By that stage, gaps in understanding have already become implementation issues.
Consider a login requirement that initially sounds simple:
Developer: “Users should be able to log in using email and password.”
At first glance, the requirement appears complete.
- What happens after repeated failed login attempts?
- Should users remain authenticated after closing the browser?
- How should the system behave if external authentication services fail?
Such questions often expose hidden assumptions before they become production issues.
Treat Automation as a Product
Automation suites naturally grow over time. Teams add new tests every sprint and gradually increase coverage across the application.
Initially, this feels like progress.
However, over time, many organizations encounter a different problem. Regression execution becomes slower. Maintenance work increases. Flaky failures appear more often. Teams begin spending more time debugging automation than investigating actual product behavior.
Take, for example, the code snippet from above. The script itself may look perfectly healthy, but if an external payment service occasionally introduces delays, intermittent failures can slowly reduce confidence in the suite.
Healthy automation needs ongoing ownership. Periodic cleanup, refactoring, and elimination of obsolete tests are just as necessary as adding new scenarios.
Focus on Metrics That Explain Product Health
Many QA dashboards contain large amounts of data without offering meaningful insight.
Metrics such as total executed tests or overall automation counts often look impressive during status reviews, but they rarely explain whether quality is actually improving.
- How many defects reached production?
- How long do critical issues remain unresolved?
- Are automation failures increasing over time?
- How quickly can teams recover from incidents?
Useful metrics should help teams understand risk and identify patterns before problems escalate.
Effective QA processes are not built by increasing activity alone. They are built by creating visibility, confidence, and consistency throughout the development lifecycle.
Final Thoughts
QA crises would have been experienced by most organizations at some point. Products become more complicated, teams scale, and release cycles are accelerated. Issues are inevitable.
What distinguishes an effective QA strategy from a reactive one is not the ability to avoid every issue. It’s the capability to develop systems that recover fast.
Calm periods don’t contribute much to building robust quality processes. They are often guided by difficult releases, awkward conversations, and moments where teams catch their weaknesses in established approaches.
For QA managers and leads, a crisis can mushroom into more than an operational snag. Managed right, a crisis can become the point where quality practices evolve from basic testing activities into a sustainable engineering discipline.
Frequently Asked Questions (FAQs)
How can QA leaders catch an early-stage QA crisis?
Early-stage QA crises often appear through patterns rather than major incidents. Repeated defect leakage into production, increasing automation instability, delayed release decisions, growing technical debt, and declining confidence in testing outcomes are common warning signs. The earlier these trends are caught, the easier it becomes to avoid escalation.
What is the difference between a QA issue and a QA crisis?
A QA issue is usually isolated and manageable within existing processes. A QA crisis takes place when quality problems start impacting customer trust, revenue, release confidence, or team productivity. The difference is often determined by impact rather than defect count.
Why does adding more test cases sometimes worsen a QA crisis?
Additional tests do not automatically create better quality visibility. Large test suites can introduce longer execution times, flaky results, and increased maintenance effort.
| Achieve More Than 90% Test Automation | |
| Step by Step Walkthroughs and Help | |
| 14 Day Free Trial, Cancel Anytime |









