AI and Closed Loop Testing
|
|
Most applications these days contain AI modules that enhance their functionalities, improving user experience. To make sure that these enhanced applications deliver what they promise, they are constantly tested and monitored.
The traditional way of testing, while effective for regular programs, often struggles when it comes to AI. These intelligent systems learn and evolve, and their behavior can be much less predictable than that of a standard piece of software. This dynamic nature means our usual testing methods might not be enough to catch all the potential problems.
Closed-loop testing is a way to ensure that AI applications are being tested in a suitable way. Let’s learn more about how closed-loop testing can help make testing of AI applications more successful.
| Key Takeaways: |
|---|
|

What is Closed-Loop Testing?
By definition, closed-loop testing works by feeding the system under test its own output in a loop as feedback. This makes testing a feedback-based process rather than a one-and-done testing activity done in isolation. The process is generally automated, with pre-defined rules and algorithms helping make decisions.
Why use Closed-Loop Testing for AI?
Closed-loop testing works well for applications that use AI as it is their ability to adapt and give relevant outputs which needs testing. AI systems are known to give outcomes that are not always the same, but similar.
How Does an AI Product Lifecycle Differ from a Regular Product Lifecycle?
When we talk about building and launching typical software, we usually follow a pretty clear path. This is often called the Software Development Lifecycle (SDLC). It generally moves through these stages:
- First, figuring out what the software needs to do (requirements)
- Then, planning how it will be built (design)
- Writing the actual code (development)
- Checking for problems (testing)
- Making it available to users (deployment)
- And finally, keeping it running smoothly (maintenance)
It’s a structured, often step-by-step process.
On the contrary, “AI is only as good as the data” holds true, and hence, a majority of your time will go into training the AI model with good-quality data. The journey of an AI product goes something like this:
- Gathering and Preparing the Data: This isn’t just about quantity; it’s also about the quality of the data and making sure it doesn’t contain hidden biases that could lead to unfair or incorrect AI behavior. This data then needs to be cleaned, organized, and prepared so the AI can understand it.
- Teaching and Validating the Model: This is where the AI “learns”. Developers feed the prepared data into the AI model, which then tries to find patterns and make sense of it. This teaching phase is highly iterative – it’s rarely perfect on the first try. Teams constantly tweak settings and try different approaches until the model learns effectively.
- Deploying the Model: Once the AI model is trained and validated, it’s integrated into an application. This could be anything from a chatbot on a website to a system that recommends movies.
- Monitoring the Model: This is a critical difference from traditional software. After deployment, an AI product isn’t just “done”. It needs constant monitoring to see how it performs with real users and real-world data.
- Retraining and Redeployment: Based on the monitoring and feedback, AI models often need to be updated. If new types of data emerge or if the AI’s performance starts to slip, it might need to be retrained with fresh information.
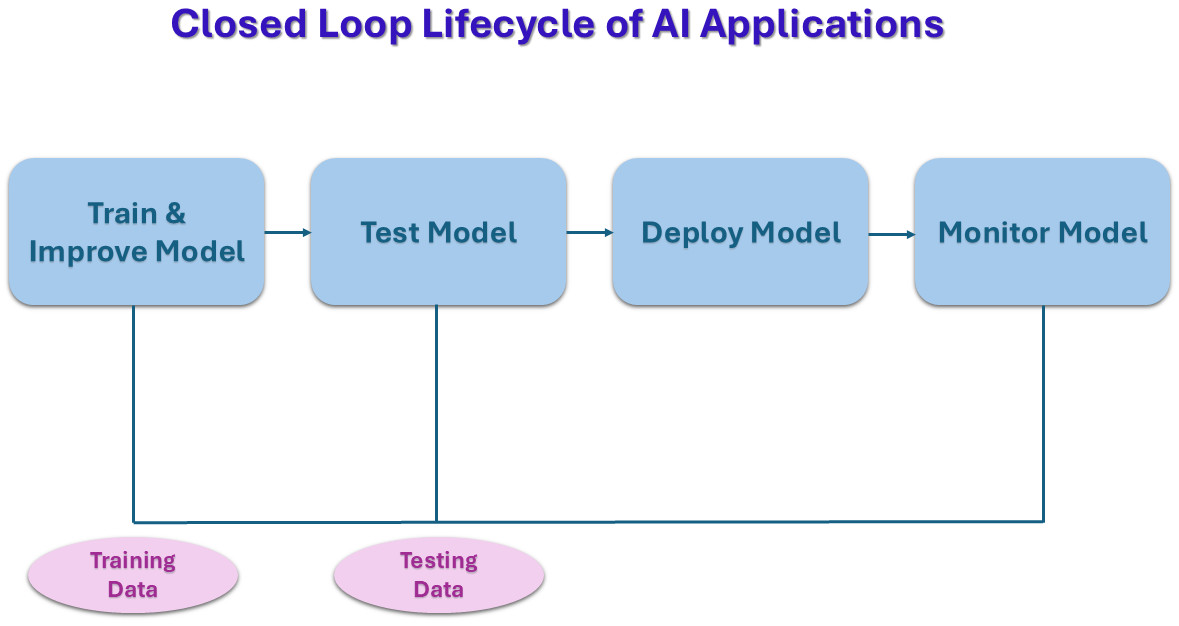
How are AI Applications Tested in a Closed Loop?
Thus, traditional testing techniques that rely on getting the same output for the same set of inputs will not work for AI applications. Or at least, they won’t consistently give us reliable results. Here’s what happens when AI applications are tested in closed loops:
Step 1: Monitoring the AI
This isn’t just about making sure it’s running without crashing; it’s about watching how well it’s doing its job. For an AI, this means tracking things like:
- Accuracy: Is it making the right predictions or decisions most of the time?
- Fairness: Is it treating everyone equally, or showing unintended biases?
- Speed: Is it responding quickly enough?
- User interactions: How are people using it? Are they happy with its suggestions or outputs?
Step 2: Gathering Feedback
A variety of data is collected to gain feedback on the AI. General techniques might include:
- New Data: This includes all the new inputs the AI processes, like new customer queries, updated market trends, or fresh images.
- User Feedback: This can be direct feedback (like a “thumbs up” or “thumbs down” button), or indirect (like how users interact with the AI’s suggestions – do they click on them, or ignore them?).
- Performance Logs: Records of how the AI performed on specific tasks.
Step 3: Evaluation
Once the new data and feedback are collected, the closed-loop system analyzes them to understand the AI’s current performance.
- Spotting Changes: The system compares the AI’s current performance against its expected performance or against how it performed previously. For example,
- Are there any drops in accuracy?
- Is it starting to show biases it didn’t before?
- Is the type of data it’s receiving changing significantly?
- Identifying Problems: If a problem is detected (e.g., the AI is no longer as good at recommending products, or it’s misidentifying certain objects), the system tries to understand why. Concerns like,
- Is it because the world has changed?
- Is the new data different from what was learned initially?
Step 4: Remediation or Retraining
Based on the findings, one might choose to adjust the AI’s behavior by:
- Triggering Retraining: If the AI’s performance dips below a certain level, or if the incoming data has changed too much, the system can automatically decide that the AI needs to “go back to school”. It might select the most relevant new data, or a mix of old and new data, to help the AI learn better.
- Other Actions: Sometimes, it might not be a full retraining. It could be a smaller adjustment, or simply an alert to a human team if the problem is complex.
This cycle of observation, evaluation, and updation continues in an attempt to keep AI outputs on track.
Automated Closed-Loop Testing using AI
Automating closed-loop testing is a possibility if one leverages AI at different stages. AI agents can smartly improvise based on the received feedback to trigger test automation.
Here are some key characteristics of automated closed-loop testing when AI is involved:
AI Agents Observe Live Applications
AI agents constantly watch the performance of the AI application and the data flowing into it. If your AI’s predictions start becoming slightly less accurate, or if the kind of questions it’s receiving suddenly changes, another AI system (the “testing AI”) can pick up on these subtle shifts. It’s looking for:
- Performance “Wobbles”: The testing AI can detect these small but important changes in how well your main AI is doing its job.
- Is the AI’s accuracy slowly dropping?
- Is it taking longer to respond than usual?
- Data “Drift”: Is the real-world data your AI is seeing different from what it was originally trained on? For example, if your AI was trained on photos of cats and dogs but now sees more pictures of birds, the testing AI can spot this “drift” in the data.
Figuring Out What’s Wrong
Another AI system or agent can act as a detective. It can quickly sift through vast amounts of information – like performance logs, data inputs, and even user feedback – to identify patterns and connections that a human might miss. The following is possible:
- Triggered Test Generation: The findings of the above step can help the AI to generate new test cases. Obviously, you’ll need some AI model training, filtering, and oversight to ensure that test generation is for appropriate cases only. Test cases will likely be created to:
- Filling the Gaps: If your AI hasn’t been tested thoroughly on certain types of data or unusual situations, the testing AI can suggest new test cases to cover those “blind spots”.
- Learning from Production: By analyzing real-world interactions, the testing AI can generate tests that mimic actual user behavior.
- Revamping Existing Tests Based on New Behavior: Apart from creating new tests, AI might also need to improve or maintain existing test cases. For example, if your AI is suddenly used by a different group of people (e.g., your language translation AI is now popular in a region with unique slang), or if existing users start using it in new ways.
Improved Test Coverage
This cycle of detecting changes and adding or improving test cases gives more thorough test coverage.
Changes to the System-Under-Test
This closed-loop testing promotes changes to the internal components of your AI application, which is being tested. Components that get affected, and possibly updated, are:
- Features: When new capabilities or functions are added to the AI.
- Models: When the core “brain” of the AI is retrained with new data or updated with a new learning approach. Read: Machine Learning Models Testing Strategies.
- Prompts: For AIs that generate text or images, the specific instructions or starting phrases given to them might be tweaked. Read: Prompt Engineering in QA and Software Testing.
- RAG data (Retrieval-Augmented Generation data): This refers to external knowledge bases or documents that some AIs use to generate more accurate or informed responses. This external data can also change, requiring the AI to adapt. Read: Retrieval Augmented Generation (RAG) vs. AI Agents.
It is possible to create such automations by integrating different tools that specialize in aiding MLOps in tandem with test automation tools that use AI agents. For example,
- Cloud Platforms: Major cloud providers like Google Cloud (with Vertex AI and its MLOps suite), AWS (with SageMaker), and Microsoft Azure (with Azure Machine Learning) offer services and frameworks specifically designed to build these automated, closed-loop MLOps pipelines.
- Specialized AI Testing Tools: There are dedicated software testing products that leverage AI for various parts of the closed loop. A good example of such a tool is testRigor, which uses generative AI to simplify test creation, execution, and maintenance. Its generative AI engine can create functional test cases from descriptive prompts and also adjust test cases if some UI elements appear broken.
Of course, you’ll have to set up a proper ecosystem for this to work.
Differences in Metrics for Measuring AI Applications
Traditional applications are usually built on clear, fixed rules. They do exactly what they’re programmed to do, every single time. AI applications, however, are designed to learn, adapt, and make predictions or decisions based on patterns in data. This learning ability, while powerful, introduces a whole new set of challenges and, therefore, a need for different ways to measure their success.
Let’s look at why the metrics are different.
Traditional Application Metrics
For a regular software application, we mostly care if it’s available, fast, and doesn’t crash. Here are some common metrics used for traditional applications.
- Latency (Speed): This is simply how long you have to wait for the application to respond after you give it a command. It’s a straightforward measure of efficiency.
- Error Rates (Mistake Frequency): This measures how often the application makes a mistake or fails to complete a task as expected. It’s usually expressed as a percentage of failed actions out of total actions.
- Uptime (Availability): This is the percentage of time the application is up and running, and ready for users to interact with it.
AI Application Metrics
For AI applications, we need to measure not just if they’re running, but how smartly and effectively they’re performing their intelligent tasks. Here are some examples of AI metrics.
- Accuracy (How Often It’s Right): Similar to error rates, but more nuanced for AI. Accuracy measures how often the AI makes a correct prediction or decision. A 90% accurate AI might be fantastic for some tasks, but unacceptable for others (like medical diagnosis).
- Relevance (Is It Useful?): This metric is crucial for AIs that provide recommendations, search results, or generate content. It assesses how useful, appropriate, or on-topic the AI’s output is to the user’s need or query.
- Model Drift (Is It Still Smart?): This is a unique AI metric. AI models learn from data, but the real world changes. “Model drift” happens when the real-world data or user behavior starts to differ significantly from the data the AI was originally trained on. When this happens, the AI’s performance can slowly get worse over time, even if nothing else in the system has changed.
- AUC (Area Under the Curve) (How Good is Its “Sorting” Ability?): AUC measures how good the AI is at making that distinction across all possible scenarios.
Conclusion
With AI becoming more integrated with softwares, it is a necessity to consider a change in approaches to test them. This means considering the nuanced nature of AI and adopting testing techniques (like closed-loop testing), appropriate metrics, and competent tools for good QA.
Additional Resources
- AI In Software Testing
- What is Adversarial Testing of AI
- What is Metamorphic Testing of AI?
- Generative AI vs. Deterministic Testing: Why Predictability Matters
- What is Explainable AI (XAI)?
- How to use AI to test AI
- What are AI Hallucinations? How to Test?
- AI Context Explained: Why Context Matters in Artificial Intelligence
| Achieve More Than 90% Test Automation | |
| Step by Step Walkthroughs and Help | |
| 14 Day Free Trial, Cancel Anytime |









