Why Selenium Sucks for End-To-End Testing in 2026
|
|
Let’s first get to the basics.
What is an end-to-end test? We can define it as a test that can potentially span multiple UIs and perform testing from an end user’s perspective of a complete workflow from start to end.
Well, Selenium is not a good fit for cross-system testing or for emulating a user’s real-world experience.
This Isn’t Just Our Opinion – Selenium’s Limitations Are Widely Acknowledged
Selenium’s problems don’t just affect one group, setup, or situation. In testing and dev circles alike, you keep seeing the same headaches – unreliable checks, steep upkeep bills, sluggish runs, and automation that crumbles when the interface tweaks slightly.
Some teams spend a lot on Selenium and still admit it falls short in key areas. Big names in testing point out ongoing problems, like struggling with changing page parts, no native reports, needing lots of outside tools, or the hassle of keeping tests reliable when they grow.
Engineers plus QA people talking about actual Selenium use often notice the same thing: when apps change, test scripts need endless tweaks to keep passing. Eventually, fixing tests takes way more energy than the actual test writing.
How does Selenium Work?
Selenium was created in 2004. Way before the Single Page Apps were in favor, and when pages looked like this:
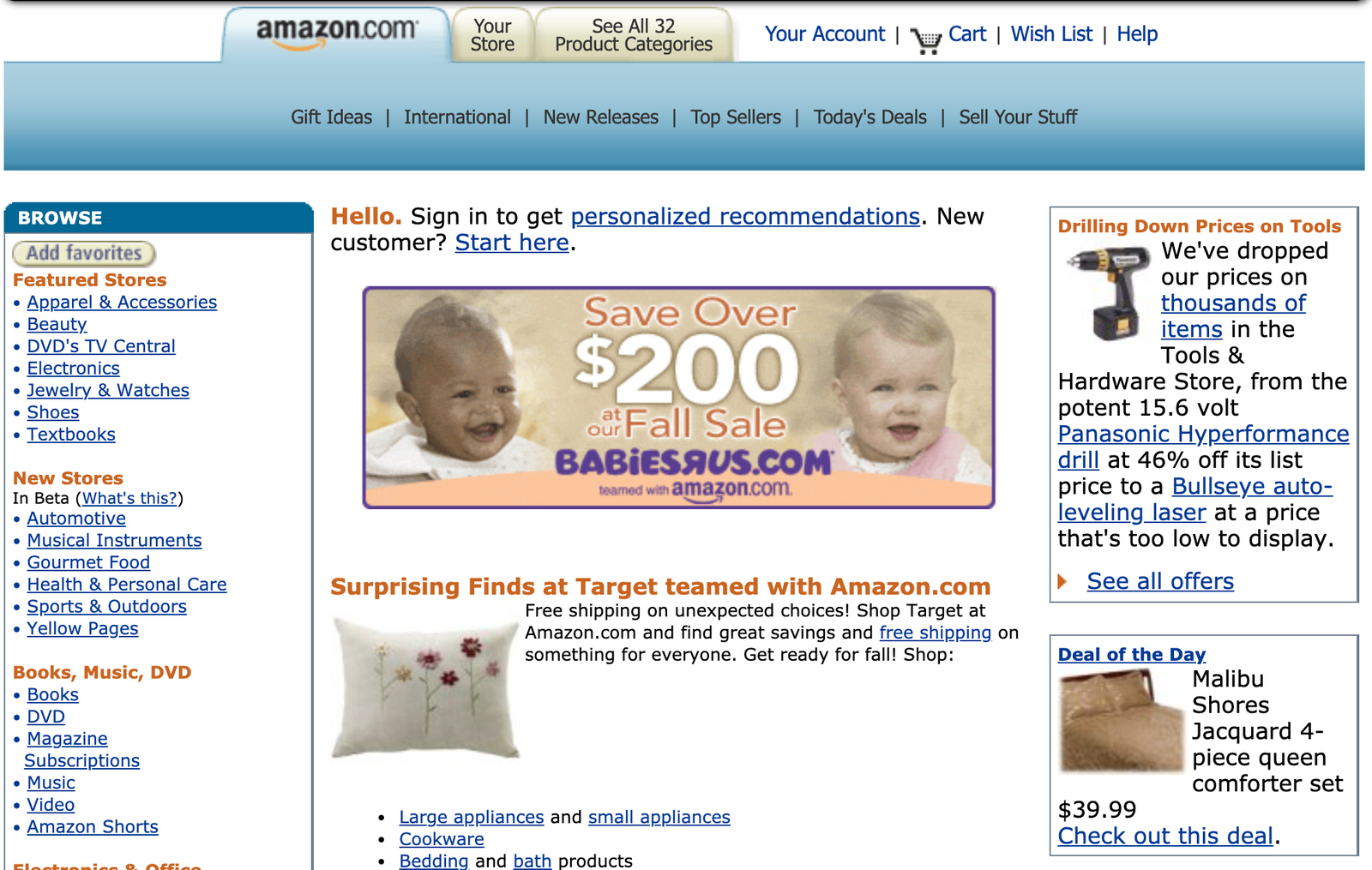
And HTML at that time looked like this:
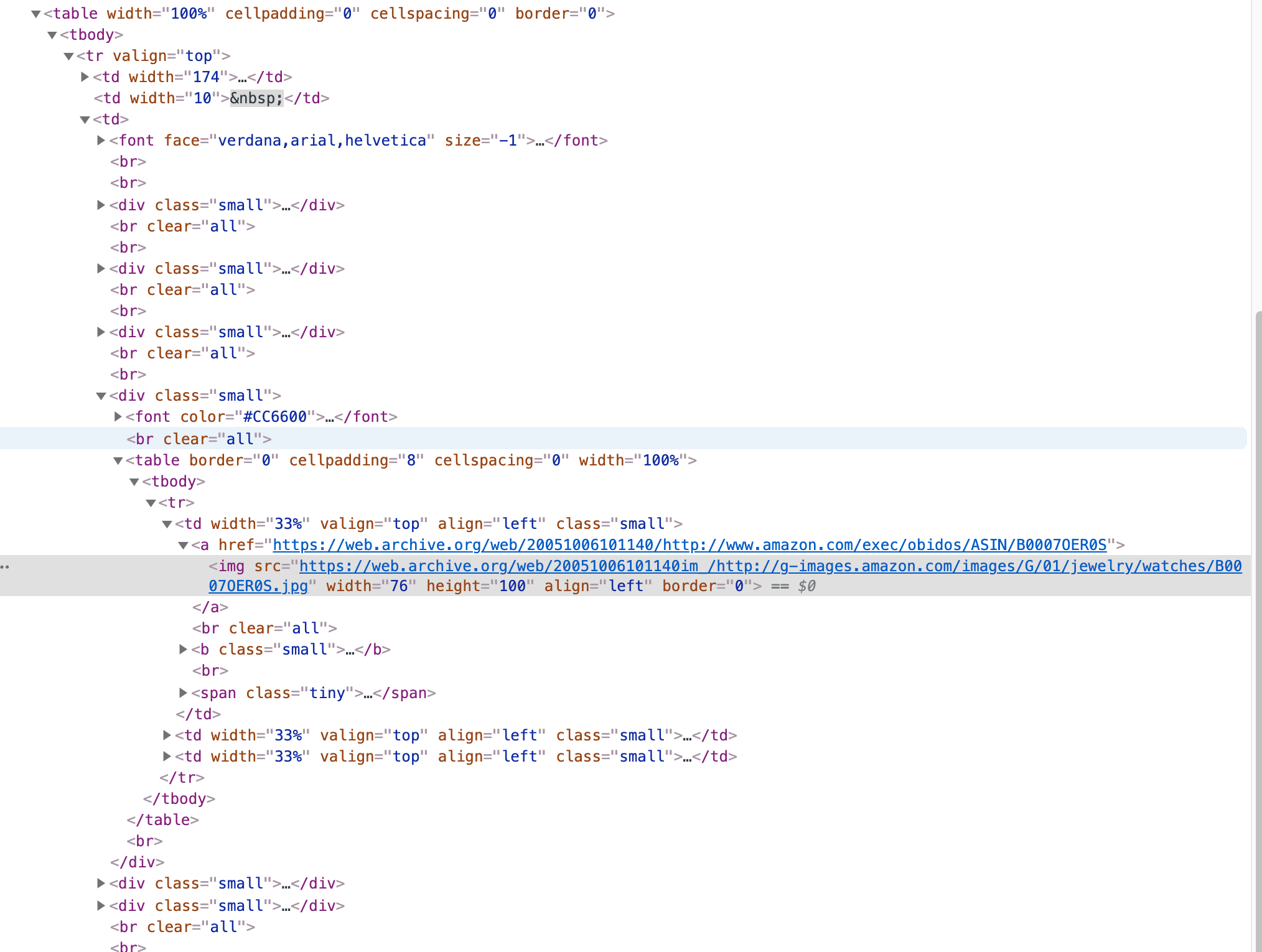
Now let’s compare this with the modern version of a similar part of Amazon’s page:
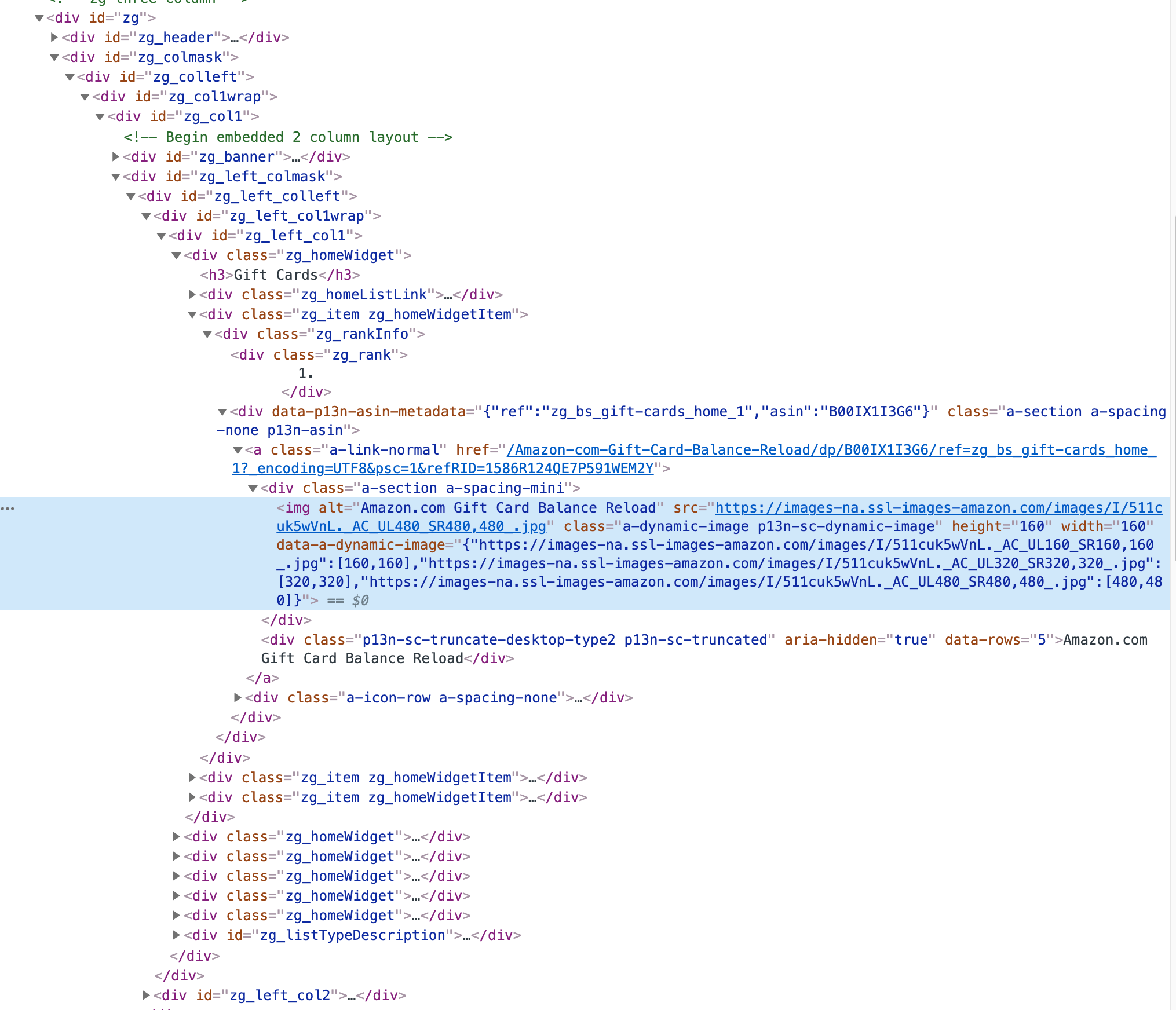
Did you notice how the code complexity grew exponentially? Where it used to be just one simple table, there are now 10+ levels of nested div elements!
The question is: Why?
Why does Selenium Encourage the Use of XPath?
Let’s look back to the roots of XPaths. HTML was created in 1993 as HyperText Markup Language to reflect a document’s structure. XPath first appeared a few years later, in 1998, to reflect the path of a structured document (similar to a URL for the web). Selenium’s design embraced the paradigm, and relying on XPaths made total sense at the time.
Unfortunately for Selenium, though, a lot has changed since then. HTML is being used differently now – mainly to position elements on the screen, often with a large combination of nested divs.
Selenium Webdriver encourages its users to stick to XPath locators by design. This approach worked well a decade ago when pages had a relatively simple structure, but it doesn’t quite work anymore. Nowadays, pages have insanely complex, barely human-readable structures; even more so, these structures are constantly changing. HTML was NOT designed to render fancy UI as we do now.
It is impossible to rely on technical information like XPaths to reference elements that are stable enough in an actively developed application. Additionally, things like ids and data-test-ids are not really working for list and table elements. I’m not even talking about the lack of ids in React.
Let’s look at the XPath from the example above for an Amazon a-tag: /html/body/div[4]/div[2]/div/div[1]/div/div[2]/div/div[1]/div/div[1]/div[2]/div/div[2]/a
//*[@id="zg_left_col1"]/div[1]/div[2]/div/div[2]/a
//div[@id='8mNf9lO2-mC1H7sJJMcE_g']//a[@class='a-link-normal']
This is unreadable and would create a maintenance nightmare, technical debt!
Debugging Issues in Selenium
Another issue with Selenium is the pain of debugging a test script. Imagine yourself investigating why a particular test failed – and finding out that it happened due to being unable to find an XPath. Your next step will likely be to copy this XPath to the browser, only to confirm that such an element on the page does not exist. Now, you have to play the guessing game to determine what this element is about. What if the person who wrote the test is no longer with the company anymore? How do you solve this XPath mystery now?
The same applies not just to XPaths but also to CSS Selectors, data-testids, ids, etc. As soon as the reference to an element is not from an end-user point of view, it is susceptible to breaking while still working for users simultaneously.
Basically, the current way of working with the page has the following issues:
- Difficult Element Identification: It is nearly impossible to understand what element is being referenced unless your Selenium code is heavily documented, and that documentation is not out of sync with the code.
- Error and Exception Handling: Only developers can understand test failures since the error descriptions are cryptic.
- Unstable Code: The structure had not been designed to properly handle modern apps with forms and tables. It lacks a stable and reliable way to refer to elements.
What is the end result? Instead of creating new tests, you have to spend an increasingly more significant amount of time on maintaining existing ones. Our experience shows it to be a widespread issue among teams that have been developing tests for 1 or 2 years, and the number of tests reaches a certain amount. They often have to spend up to 50% of their day on test maintenance rather than doing something more productive.
Now, combine that with cross-systems testing, where you don’t control the HTML of the system under test. No amount of BDD/Shift-left will help you reduce the maintenance required to constantly catch up with someone else’s changes in 3rd party apps (think Salesforce).
Slow Execution Speed
Selenium operates through a browser driver (such as ChromeDriver, GeckoDriver, or EdgeDriver), which interacts with the browser through HTTP requests. This introduces multiple layers of latency, as each command must be sent to the driver, then processed by the browser, and finally returned to the test framework.
Additionally, Selenium’s reliance on the Document Object Model (DOM) means tests often spend time searching for elements, waiting for page loads, and dealing with dynamic content.
Modern software teams rely on Continuous Integration and Continuous Deployment (CI/CD) pipelines. Slow tests delay the feedback loop, making it harder for teams to release software quickly. When running thousands of test cases, the cumulative execution time of Selenium tests can stretch into hours, making them impractical for modern development workflows.
Flakiness and Instability
Flaky tests reduce confidence in test results. When failures occur randomly, developers waste time re-running tests or manually verifying whether a failure is genuine. Over time, flaky tests lead to “test fatigue,” where teams start ignoring failures, ultimately reducing the effectiveness of automation. Common causes for flakiness include:
- Dynamic Content – Many modern web applications use AJAX and JavaScript-heavy frameworks (React, Vue, Angular) that dynamically load content. Selenium struggles to detect and interact with elements that appear asynchronously.
- Timing Issues – Selenium relies heavily on explicit and implicit waits, but these mechanisms often fail when network conditions change or system load varies.
- DOM Changes – Web applications evolve frequently, and even minor UI changes can cause Selenium tests to break due to hardcoded selectors.
- Browser Variability – Different browsers render pages differently, causing Selenium tests to behave inconsistently.
Why Selenium Tests Become Flaky in Modern Applications
Flakiness pops up a lot in Selenium end-to-end tests, especially now that web apps are getting trickier. Complexity adds fuel to this issue, making glitches show up more often.
Nowadays, apps often use tools such as React, Angular, or Vue – these depend a lot on async display methods, live HTML adjustments, and shifts in data handled by the browser. Parts can pop up, vanish, or even refresh several times through one action from the person clicking around.
Selenium grabs the page exactly when it checks, no earlier. When the app lags behind, just barely, and things break without warning.
So, Selenium tests usually show:
- Checks work on your machine – yet break when running in CI
- Faults vanish once tests are run again
- Spotty problems that don’t show up often – hard to track down or fix
Selenium vs Modern End-to-End Testing Approaches
| Aspect | Selenium | Modern E2E Approach |
| Test strategy | DOM-based | User-intent based |
| Flakiness | Common | Significantly reduced |
| Maintenance | High | Low |
| CI/CD performance | Slows pipelines | Faster feedback |
| Debugging | Technical & brittle | Readable & intuitive |
| Scalability | Costly | Designed for scale |
How Should End-to-end Testing Work?
Think about it. What are end-to-end tests supposed to do? They are supposed to help you validate that your functionality works from the end-user perspective, according to the real-world user flow.
Therefore, you should refer to elements from the end-users’ perspective, i.e., how they see things and not how the developer sees the application. The only things that matter to any actual user are finding the right input to enter or locating the correct button. Therefore, there should be an easy, stable way to work with forms and tables that emulate a user interacting with a browser or a device.
Example: Forms
Let’s talk about forms. Here’s another example from amazon.com:
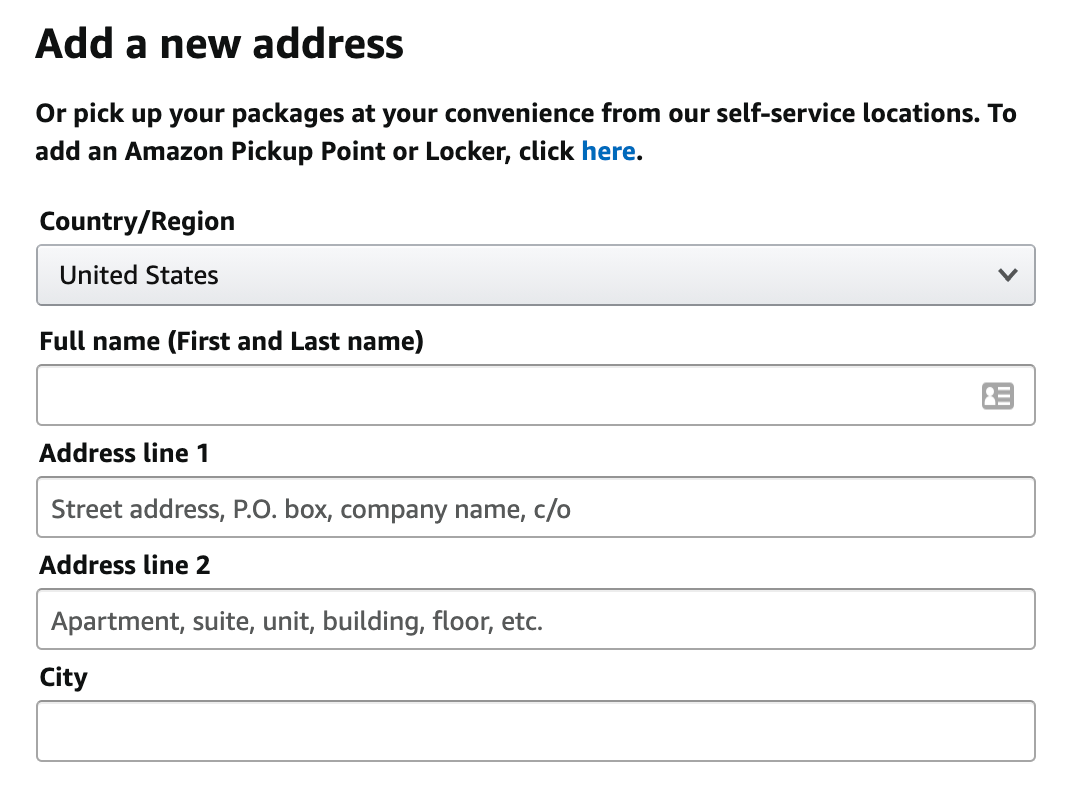
Here is the HTML:

Did you notice how an element’s ‘id’ and ‘name’ are clear and descriptive? Simply great! Problem solved then, but is it really so?
The moment you change your UI framework to React, all your fancy ids are gone. When you migrate to some back-end-hooked rigid framework (or a new version), your name would probably have to change as well (think ASP.NET). Interestingly, this is EXACTLY when you want your end-to-end tests to work. Because you just migrated to a new framework, you need to run the end-to-end tests to see if everything is working.
Therefore, a proper end-to-end testing tool should never hook up onto the internals of your application, but rather, how it looks from the end-user’s perspective. Look at the “City” input on the screenshot above, this structure might change. However, I’d argue that this form will always have either a placeholder saying “City” or whatever an end-user perceives as a “label” for it.
Again, based on our experience (don’t trust us, check for yourself), not everyone would have such a proper HTML structure as Amazon with a ‘label for’ structure in place. So, unfortunately, you can’t rely on that either.
Therefore, there should be a way to describe or identify this input from an end user’s perspective, relying on what is considered a “label” or a placeholder and not based on the code structure.
So, it should look something like this: enter "San Francisco" into "City"
Right?
Example: Tables
Now, next, let’s talk about tables.
Here is one of the most widely used examples from Salesforce:
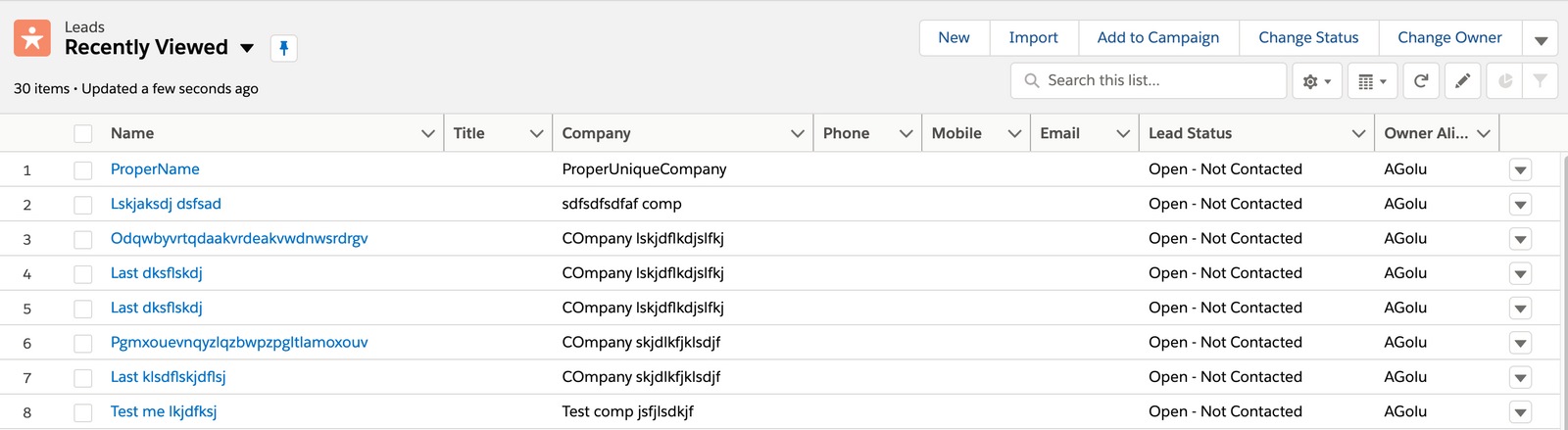
What matters from the end-user’s point of view is that the row containing the ProperUniqueCompany has a certain status. Another example is that the down icon in the last column on that row can be clicked.
validate that table at row containing "ProperUniqueCompany" and column "Lead Status" contains "Open - Not Contacted"
click on the table at the row containing "ProperUniqueCompany" and the last column
This should work regardless of how the table is rendered – whether it’s HTML <table> (like in Salesforce example) or using <div> rendering (like in Amazon example). See here for a better way to work with tables.
Hopefully, you’re now on the same page with us that using XPath in 2026 has many disadvantages. Here are the 11 reasons why not to use Selenium.
Users certainly don’t care about the ids, names, or data-test-ids of those elements. Moreover, they often lead to situations where those ids/names/etc., change, causing the test to fail. Even though, from an end-user’s perspective, everything is good. These changes in XPaths would undoubtedly result in the degradation of test stability.
testRigor for End-to-end Testing
Think about it: wouldn’t it be wonderful if you only needed to maintain your test when the application actually changes, as opposed to when the HTML code would change?
Fortunately, there is a way now!
The examples in this article are actually executable code from testRigor. It is an AI agent that works on generative AI to let you generate, record, or write test cases in plain English.
Through testRigor, UI changes are easily incorporated into the test scripts without human intervention. For example, if an ‘Add to Cart’ button is changed from <button> tag to <a> tag, testRigor will learn how the button is rendered and understand the button’s role within the application context.
You can write test scripts for scenarios such as 2FA, QR code, file, database, geolocation, email, phone call, SMS, video, audio, accessibility testing, and many more, easily using plain English. Here is the top testRigor’s feature list.
Read here how you can decrease 99.5% of your test maintenance time.
You have the following advantages with testRigor:
- No Programming Required:It is a codeless tool where tests are written/generated using plain English commands. This enables the whole team to write tests (even the manual testers) and increases the speed of writing tests dramatically. The record-and-playback feature can accelerate test creation even further. Consequently, the recorded tests will have the same plain English format, making any person to update and maintain them whenever required. Read: All-Inclusive Guide to Test Case Creation in testRigor.
- Stable Locators: There is no hassle mentioning CSS or any technical parameters for locating elements on the screen. All you need to do is mention relative positions or how you see an element on screen. You can click on a button below the title by simply writing
click “button” below “Title”. - AI-based Self-healing: Using Vision AI and auto-healing for rules and single commands, testRigor will be able to look on the screen for an alternative way of doing what was intended as opposed to failing. This will allow you to very quickly adapt to breaking changes in your application. Read more about AI-based self-healing.
- Cross-browser and Cross-platform Support: The tool allows you to perform cross-browser and cross-platform tests; parallel execution feature allows you to get the test results in minutes.
- Supported Integrations: This can be easily integrated with most CI/CD tools, test management tools, and issue-tracking tools.
- A Single Tool for All Testing Needs: You can write test cases across platforms: web, mobile (hybrid, native), API, desktop apps, and browsers using the same tool in plain English statements.
- Test AI Features: This is an era of LLMs, and using testRigor, you can even test LLMs such as chatbots, user sentiment (positive/negative), true or false statements, etc. Read: AI Features Testing and Security Testing LLMs.
enter "SAMSUNG Galaxy S24 Ultra Cell Phone" into "search" type enter click "SAMSUNG Galaxy S24 Ultra Cell Phone" click "256GB" click "Titanium Yellow" click "Add to cart" click "No Thanks" if page contains "Phone Accident Protection Plan" check that page contains "Added to cart"
Conclusion
Selenium has trouble handling today’s end-to-end tests because it was built for a whole other web app era.
Nowadays, full testing, from start to finish, must:
- Reflect real user behavior
- Remain stable as UI implementations change
- Provide fast, reliable feedback in CI/CD pipelines
- Minimize maintenance overhead
Intelligent tools like testRigor are here to help you drastically reduce test creation and maintenance time. Using its plain English commands, anyone from manual testers, BAs, SMEs, and other stakeholders can create, run, and edit test scripts quickly. Read here how testRigor is a test automation tool for manual testers.
If better options are available, why not use them and save valuable time, effort, and money? Let the experts dedicate their energy to creating more robust tests rather than debugging and exception handling of erratic test scripts. Make an informed decision to provide excellent quality and test coverage within deadlines.
| Achieve More Than 90% Test Automation | |
| Step by Step Walkthroughs and Help | |
| 14 Day Free Trial, Cancel Anytime |









