What Is Agentic QA?
|
|
Software testing is always treated with caution by engineering teams. The majority agree that testing is important, yet almost everyone has experienced the annoyance of having to maintain test suites at scale. As software systems become more complex and organizations release updates faster, the older methods of QA don’t keep up.
Teams spend weeks creating end-to-end automation, integrate it into CI/CD pipelines, and feel productive for a while, until the app starts evolving rapidly. A modified checkout flow breaks twenty tests. A frontend engineer renames a selector, and another set of tests starts failing. A new onboarding step gets introduced, and suddenly half the regression suite turns red.
Most teams eventually come to accept an uncomfortable truth: as applications grow, maintaining automated tests can begin using up as much effort as writing the application itself.
Agentic AI is helping QA keep pace by enabling testing systems to make smart decisions on their own rather than depending on fixed instructions. Agentic QA proposes a different way of thinking about testing. Rather than building systems that strictly follow predefined instructions, it attempts to build systems capable of reasoning about software behavior.
The shift sounds subtle, but from an architectural perspective, it is fairly significant.
| Key Takeaways: |
|---|
|
What is Agentic QA?
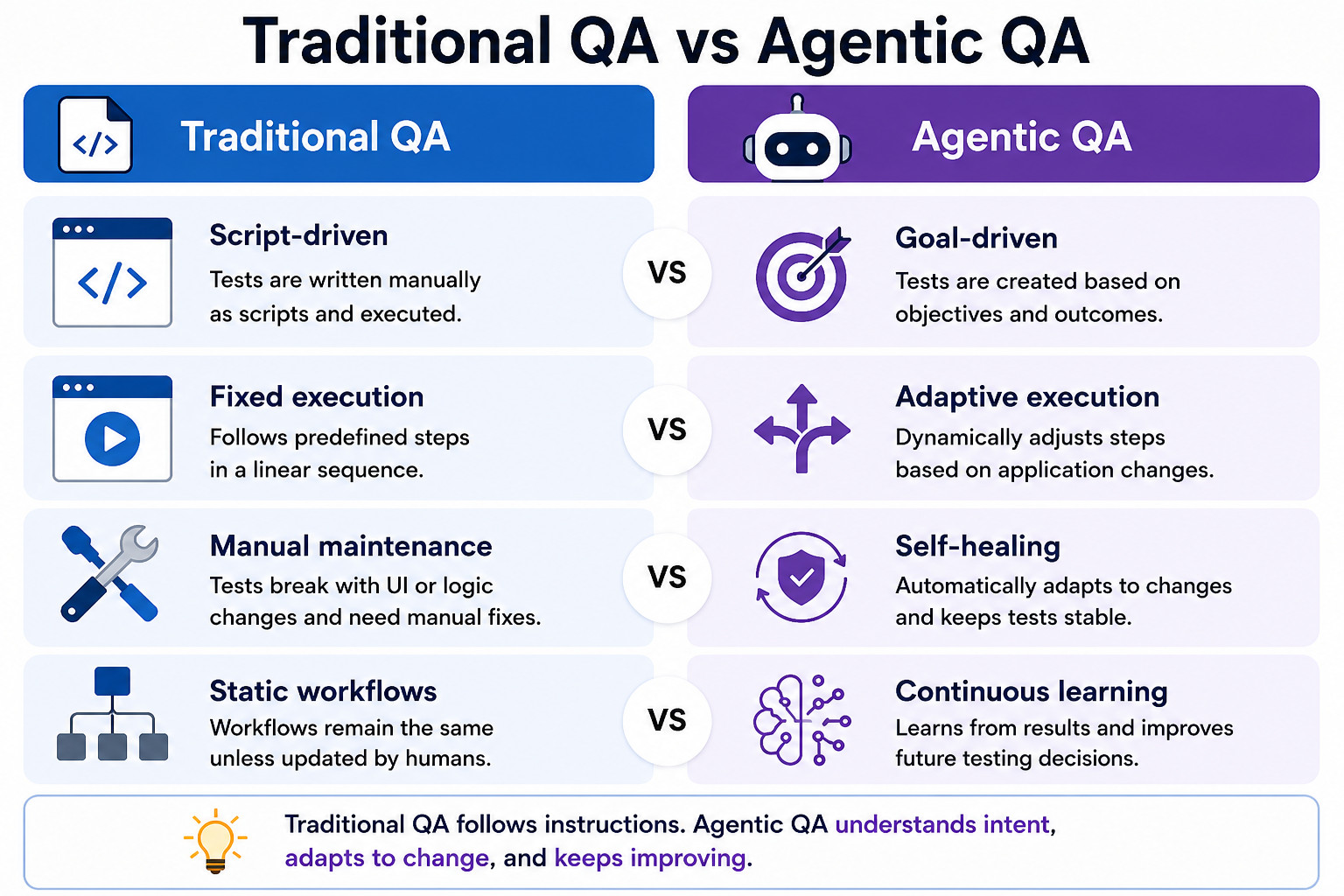
Agentic QA is a method of software QA where autonomous AI agents plan, execute, and adapt testing workflows relevant to goals rather than preset scripts. In place of adhering to step-by-step instructions defined by a human, agentic systems understand requirements, determine what needs testing, generate and run test cases, analyze failures, and continuously fine-tune their strategy as the app grows.
Consider it this way. Typical traditional test automation is similar to providing someone a recipe and telling them to follow the instructions exactly. Agentic QA is like employing a chef who understands the dish you want, chooses the best ingredients, adapts the techniques based on what’s available to them, and adjusts the seasoning as they go. The human is still responsible for setting the goals. The agent is only responsible for figuring out how to achieve it.
Agentic QA, as a phrase, sits at the junction of several related strategies. This includes autonomous testing, AI-powered testing, and intelligent test automation. Agentic QA is unique because it defines a particular level of autonomy where the AI works in a goal-directed loop of planning, acting, observing, and adapting, instead of just helping with isolated tasks.
Read: Top QA Trends for 2026.
The Difference Between Script Execution and Goal Execution
Most QA engineers are already familiar with the restrictions of deterministic automation. Scripts succeed at validating known paths, but software systems rarely stay static.
Human testers naturally adapt to change.
Consider opening a website where the login button is shifted from the top-right corner to a sidebar menu. A human barely notices. They scan the page, identify the new location, and continue.
"Selector not found."
Execution aborted.
Agentic systems attempt to replicate the adaptive behavior humans demonstrate naturally.
Internally, this generally involves combining several components:
- a reasoning layer
- browser automation
- contextual memory
- execution tools
- validation systems
The browser automation framework itself is usually unchanged. Technologies like Playwright still execute interactions such as clicks, keyboard input, and DOM inspection.
The intelligence layer sits above those systems.
"Click element with ID login-btn"
The agent might evaluate several signals simultaneously:
- visual labels
- semantic meaning
- accessibility metadata
- historical interactions
- nearby components
The process begins looking less like automation scripting and more like decision-making.
Why Self-Healing Tests have Become a Major Discussion
One of the most heavily discussed capabilities around Agentic QA is self-healing behavior. Anyone who has maintained large UI suites understands why. Consider a common example.
<button id="checkout-btn"> Checkout </button>
<button id="purchase-button"> Checkout </button>
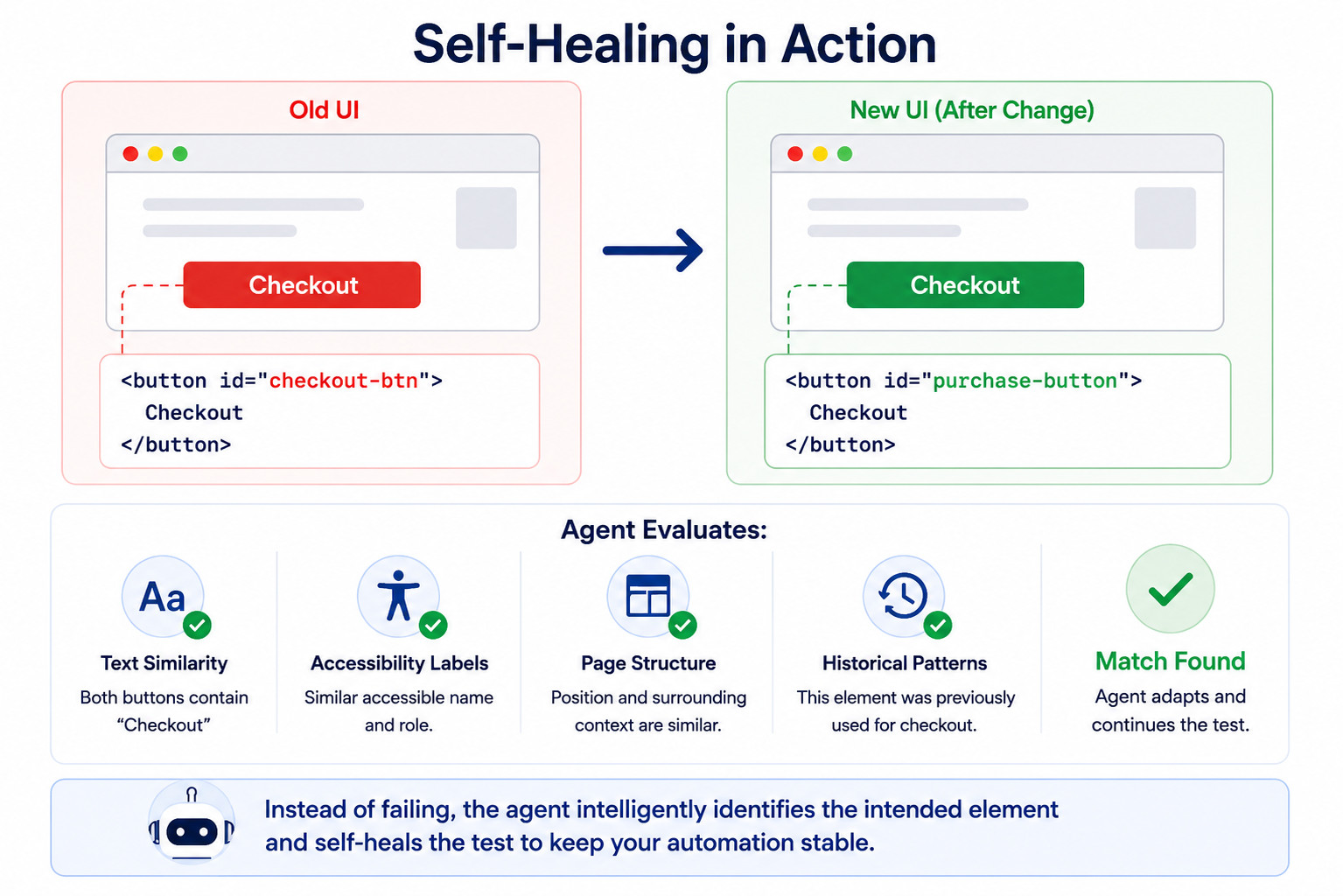
"What element most likely represents the intended action?"
Rather than relying on a single identifier, it validates multiple characteristics:
- visible text
- accessibility properties
- surrounding page structure
- historical interaction patterns
- semantic similarity
<button>Checkout</button> <button>Express Checkout</button>
The agent now needs confidence in scoring. Selecting the wrong one will create a false positive where tests technically pass while testing the wrong workflow. For that reason, self-healing systems usually need secondary validation mechanisms. Blind adaptation becomes dangerous. Controlled adaptation becomes useful.
The Architecture Behind Agentic QA Systems
While implementations differ across vendors and internal engineering teams, most Agentic QA platforms depend on a similar set of underlying components. Understanding these building blocks helps explain why agentic systems behave differently from traditional automation frameworks.
Reasoning Layer
At the core of most systems resides a reasoning engine, often powered by a large language model or a specialized decision layer. Its responsibility is not to execute actions directly but to interpret objectives and determine intent.
"Verify that guest users can complete a purchase successfully."
Then the reasoning layer determines what that statement actually means from a testing POV. It identifies relevant workflows, possible dependencies, and expected outcomes before passing instructions to downstream systems.
Rather than functioning like a static rules engine, this layer continuously evaluates context and makes decisions based on changing application behavior.
Execution Layer
Once a strategy exists, another component must translate those decisions into actual interactions with the application.
This responsibility typically falls to browser automation and execution frameworks such as Playwright, Selenium, or Puppeteer. These systems perform the operational work: clicking buttons, entering values, submitting forms, validating responses, and collecting runtime information.
The important distinction is that these frameworks are no longer acting as the source of intelligence. They become execution mechanisms controlled by higher-level decision systems.
Memory and Context Management
Memory is one of the least discussed but most important elements in Agentic QA architecture.
Traditional automation generally starts from zero during each execution cycle. Agentic systems benefit from retaining context across runs.
This information may include:
- previously observed failures
- recurring application patterns
- successful interaction histories
- known edge cases
- historical UI changes
As systems scale, memory becomes increasingly valuable because it reduces repeated discovery and allows testing behavior to improve over time.
Validation and Feedback Systems
Reasoning and execution alone are not sufficient. Agentic systems also need protocols for validating outcomes and feeding observations back into future runs. This layer helps distinguish actual defects from environmental failures, flaky tests, and transient system behavior.
Without a feedback mechanism, an autonomous testing system becomes difficult to trust in production environments. Over time, these components form a continuous ecosystem where execution generates data, data informs decisions, and decisions influence future testing behavior.
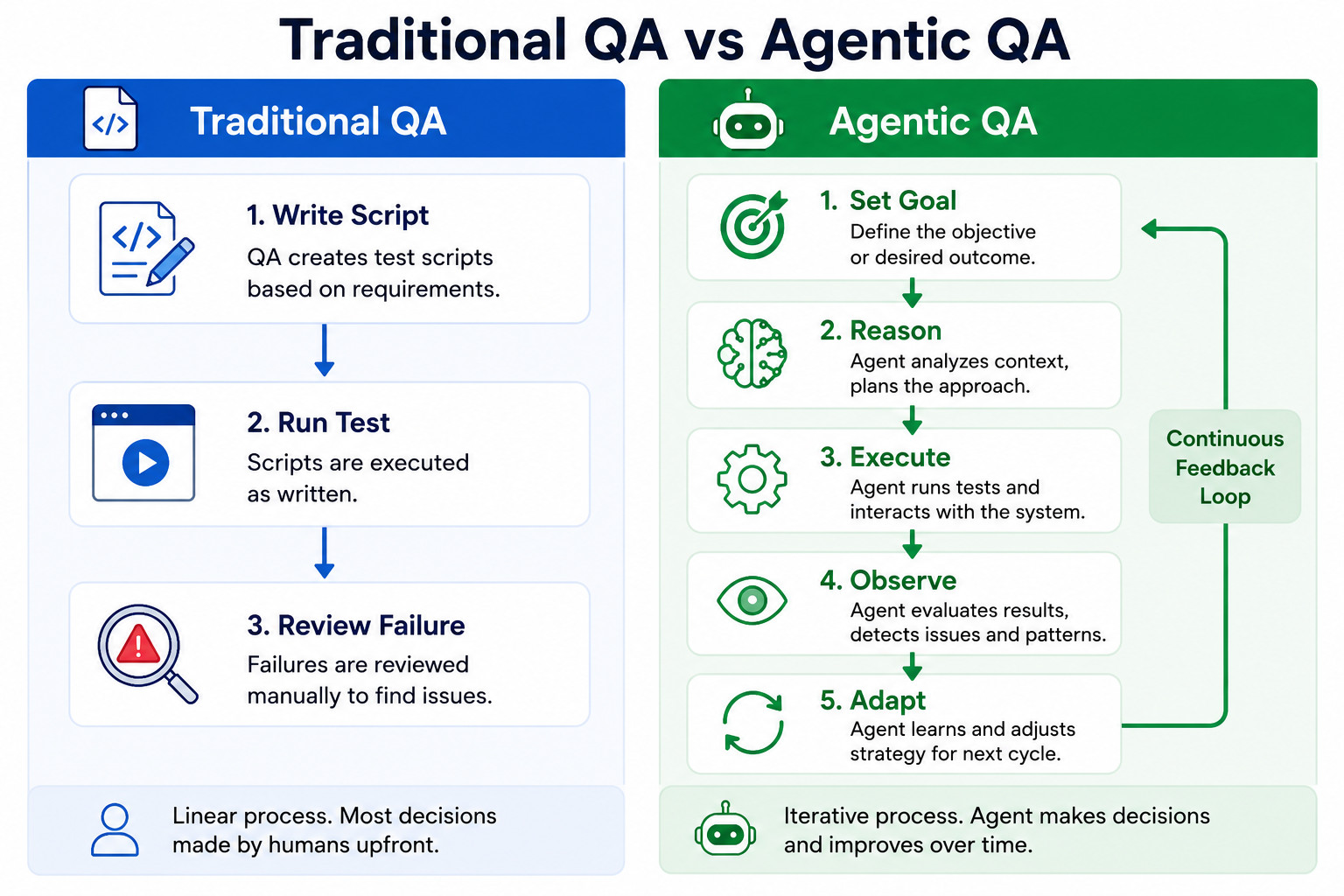
How Agentic QA Actually Works
Agentic QA works more like a continuous feedback loop than a usual test execution process. In traditional automation, tests are written, executed, and reviewed separately, with most decisions made upfront. Agentic systems operate differently. They continuously analyze context, decide what deserves attention, execute actions, evaluate results, and improve based on what they learn.
Understanding Context
The process is initiated by understanding what has changed and where risk exists. The system can pull context from user stories, requirement documents, API specifications, pull requests, release notes, or historical defects.
For example, a small UI text change does not require the same level of testing as modifications to authentication or payment logic. Instead of treating every release equally, the system attempts to prioritize testing effort based on impact.
Read: AI Context Explained: Why Context Matters in Artificial Intelligence.
Generating and Executing Test Scenarios
After identifying what needs attention, the system builds test scenarios that align with expected user behavior.
"Guest users should be able to complete a purchase without creating an account."
Open storefront Add product to cart Proceed as guest Enter shipping details Submit payment Verify confirmation
These scenarios are then executed using automation frameworks.
Learning and Adapting
What makes Agentic QA different from conventional automation is its capability to adapt. Instead of immediately failing when applications change, the system attempts to interpret those changes and adjust its behavior.
Over time, observations from previous runs help improve future decisions. The result is a testing process that gradually becomes more cognizant of application behavior, bringing down repetitive maintenance work and allowing QA teams to focus more on exploratory testing and complex edge cases.
Read: Different Evals for Agentic AI: Methods, Metrics & Best Practices.
Where Retrieval-Augmented Generation Fits
"Premium users may export reports larger than 100 MB."
A generic model has no way of knowing this rule exists. Without context, the testing process becomes guesswork. Retrieval-Augmented Generation, typically called RAG, addresses this issue by injecting external information into the agent’s decision-making process.
Instead of depending only on model memory, the system retrieves information from:
- requirement documents
- API specifications
- internal knowledge bases
- product documentation
- user stories
The flow becomes:
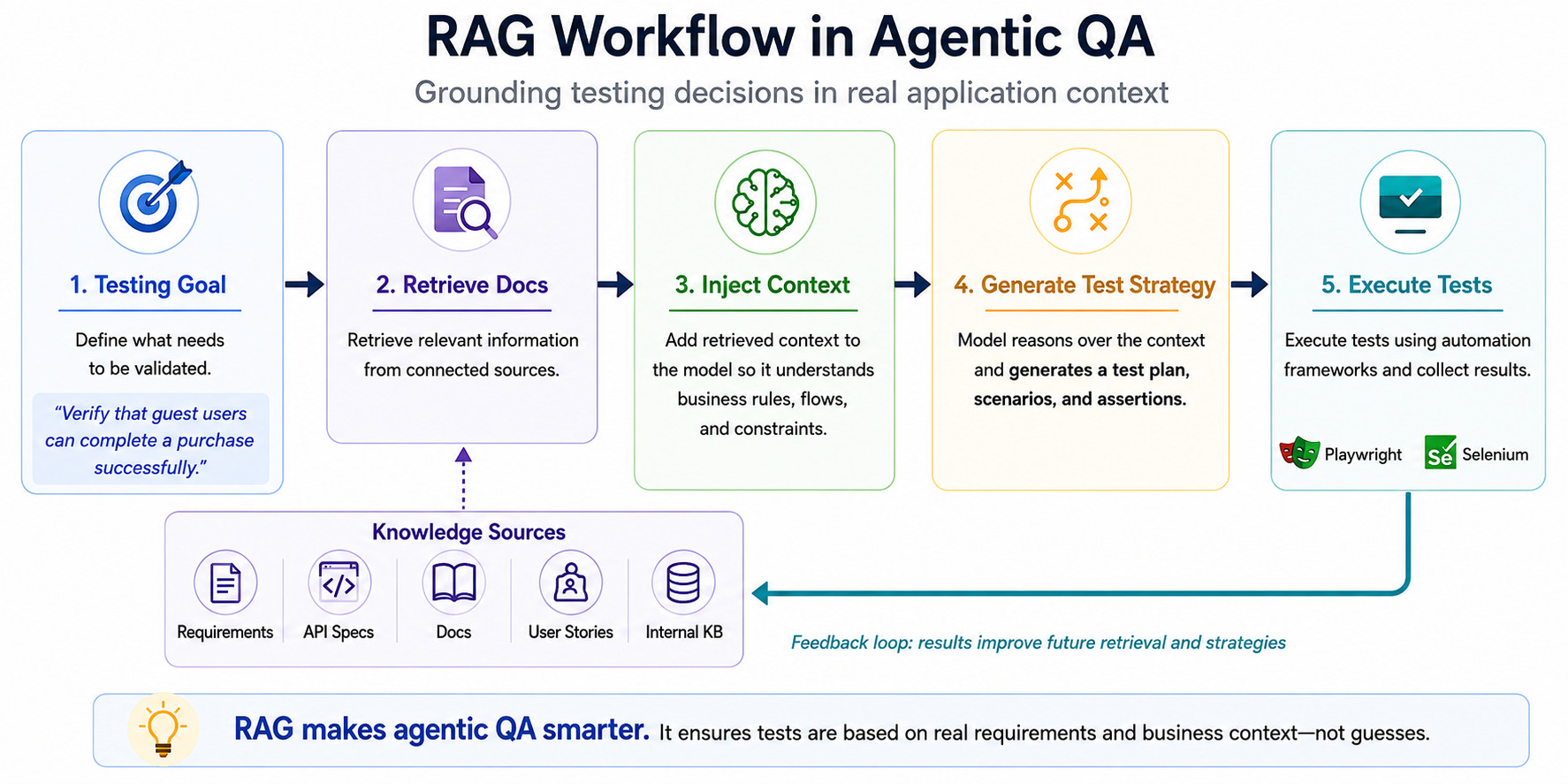
The agent now understands expected behavior before interacting with the application. This significantly improves accuracy.
Will Agentic QA Replace QA Engineers?
"What happens if this API returns incomplete data?"
"What happens if two systems update simultaneously?"
"What happens during network instability?"
These questions need domain understanding that is not limited to automation.
What Agentic QA changes is where effort gets spent.
Instead of maintaining brittle scripts and debugging selectors every week, QA engineers may increasingly spend time designing testing strategies and validating autonomous systems. The role becomes less operational and more analytical.
How Agentic QA Principles Are Appearing in Modern Testing Tools
Completely autonomous QA systems with zero manual intervention are still evolving. However, tools like testRigor have started including capabilities that are geared towards agentic direction. The tool allows testers to create tests in plain English rather than depending fully on selectors and code-heavy scripts. Instead of tightly coupling automation to implementation details such as DOM structure or element identifiers, the platform attempts to validate workflows from a user-behavior perspective. It has self-healing capabilities that actually work.
Tools like this do not represent the final state of Agentic QA, but they demonstrate how the industry is steadily moving away from rigid script maintenance toward systems that can understand intent and adapt to change.
Conclusion
Agentic QA helps with autonomous and adaptive testing that enhances software quality and delivery speeds while still needing human monitoring. As software complexity increases, so will the need for Agentic QA. The technology is still early, and there are unresolved challenges around reliability, hallucinations, reproducibility, and cost. Yet the direction seems increasingly clear.
As software systems scale and release cycles become shorter, static testing models begin struggling under the weight of continuous change. The future of quality assurance may not involve writing larger collections of scripts.
It may involve building systems capable of understanding what they are actually trying to validate.
FAQs
What is the difference between Agentic QA and traditional test automation?
A: Traditional test automation relies on predefined scripts and fixed workflows. Agentic QA focuses on goals rather than instructions. Instead of executing exact steps, autonomous agents can understand objectives, generate tests, analyze outcomes, and adapt when applications change.
Is Agentic QA and AI-powered testing the same?
A: AI-powered testing is a bigger category that can include test generation, analytics, or failure prediction. Agentic QA is a more specific approach where AI systems work autonomously in a cycle of planning, execution, observation, and adaptation.
How does Retrieval-Augmented Generation (RAG) improve Agentic QA?
A: RAG gives application-specific context to AI systems. It retrieves information from requirement documents, API specifications, user stories, and knowledge bases, so testing decisions are based on actual business rules rather than assumptions.
Which types of applications benefit most from Agentic QA?
A: Agentic QA can offer the maximum value for applications that change frequently, such as SaaS platforms, e-commerce systems, enterprise products, and large web applications, where maintaining traditional automation becomes expensive.
What are the biggest challenges with Agentic QA?
A: Challenges include hallucinations, non-deterministic behavior, trust and validation concerns, infrastructure cost, and maintaining consistency across large testing environments.
| Achieve More Than 90% Test Automation | |
| Step by Step Walkthroughs and Help | |
| 14 Day Free Trial, Cancel Anytime |









