How to Validate AI-Generated Tests?
|
|
Artificial Intelligence (AI) has been used in all aspects of life, including software engineering. Its growing use has completely transformed the software development process, including test case generation. AI-powered tools now automatically create unit tests, integration tests, functional tests, and end-to-end scenarios, promising improved coverage and time savings.
However, to ensure these AI-generated tests are correct and meaningful, they must be validated to ensure reliability, accuracy, and usefulness.
| Key Takeaways: |
|---|
|
This article explores the importance of validation and provides developers, QA engineers, and technical leaders with a step-by-step roadmap to ensure test quality in AI-powered development workflows.
Why is Validation of AI-generated Tests Important?
AI is powerful but imperfect (at least as of now). Though they can generate high-volume test cases in seconds, they don’t understand your specific business logic or user context. Without validation, you risk wasted effort, misleading confidence, and fragile test suites.
- Preventing Inaccuracies (Hallucinations): AI generates convincing test cases, but they may be incorrect, flawed, or illogical. Validating test cases ensures they measure what they are supposed to and remain meaningful.
- Ensuring Comprehensive Coverage: Validation ensures that AI-generated scenarios cover critical edge cases, boundary conditions, and invalid scenarios, rather than just basic functionality.
- Mitigating Bias and Ensuring Security: AI models are not free from bias or security threats. One validation technique is to include a human to manually review tests. This human validation checks for ethical and security constraints.
- Reducing Costly Failures: Unvalidated tests can miss critical bugs, leading to expensive post-release fixes, system downtime, or a damaged brand reputation.
- Improving Future AI Performance: Human validation of AI-generated tests improves future accuracy by creating a feedback loop.
AI-based tools, ranging from LLMs to agentic automation platforms, can generate various types of tests by analyzing requirements, code, and user interactions.
Here are the main types of tests and artifacts that can be generated using AI:
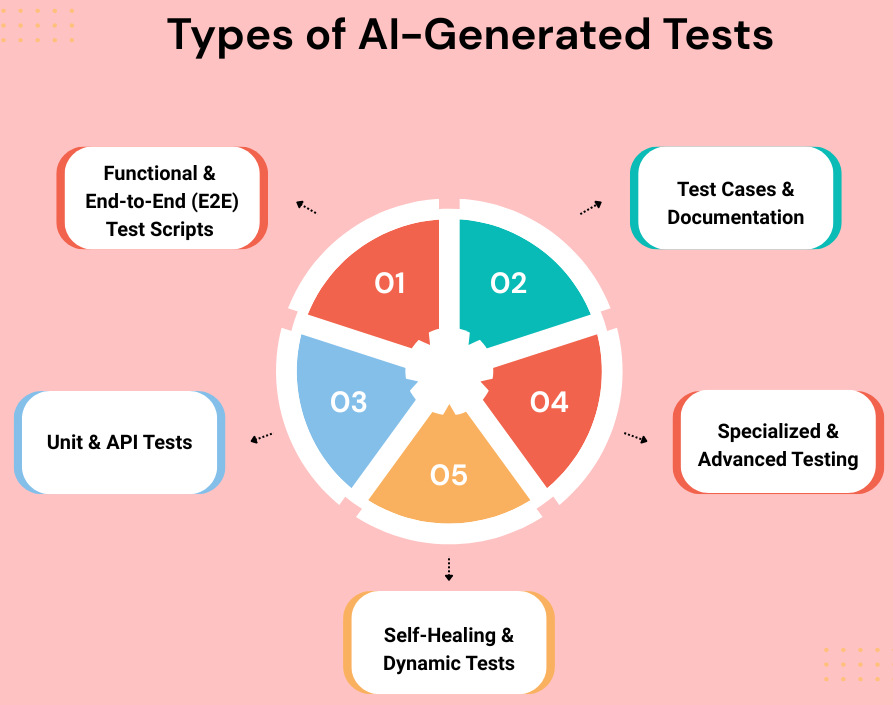
1. Functional and End-to-End (E2E) Test Scripts
AI tools can generate functional and end-to-end (E2E) test scripts. Tools like testRigor allow users to generate tests in plain English, which are executable, automated steps, reducing the need for coding. User flows, or code, are analyzed, and tests are generated. Similarly, AI-enhanced session recorders capture user actions performed in UI and convert them into durable, low-code tests.
2. Test Cases and Documentation
AI translates JIRA issues, requirements, or user stories into automated tests. It can also analyze Figma designs, produce specifications, or PDF documents to create comprehensive cases, including edge cases and negative scenarios. AI models analyze historical test data to identify and remove redundant or inefficient test cases.
3. Unit and API Tests
AI models can scan source code to automatically generate unit tests that cover edge cases and improve code coverage. It can also analyze API specifications to generate functional test cases for API endpoints.
4. Specialized and Advanced Testing
Test cases for specialized and advanced testing types, such as visual regression testing, accessibility testing, performance, or load testing, are created by AI models. AI-based tools compare UI screenshots against a baseline using visual AI to identify cosmetic bugs or inconsistencies across browsers or devices to generate regression tests. Models can also scan UI components to detect potential accessibility issues and suggest fixes.
Generative AI models create realistic, synthetic test data, including complex edge cases and negative inputs. AI models can simulate high-volume user traffic using historical patterns to identify performance bottlenecks.
5. Self-Healing and Dynamic Tests
AI-powered testing tools like testRigor detect UI element changes and update the test script in real time. A human approves the changes, and the tests continue to run after self-healing.
Step-by-Step Validation Framework
A comprehensive, step-by-step validation framework is required to verify test cases, scenarios, or automated scripts generated by AI. It is essential that AI is treated as an assistant rather than a replacement for human expertise.
Here’s a practical roadmap to validate AI-generated tests.
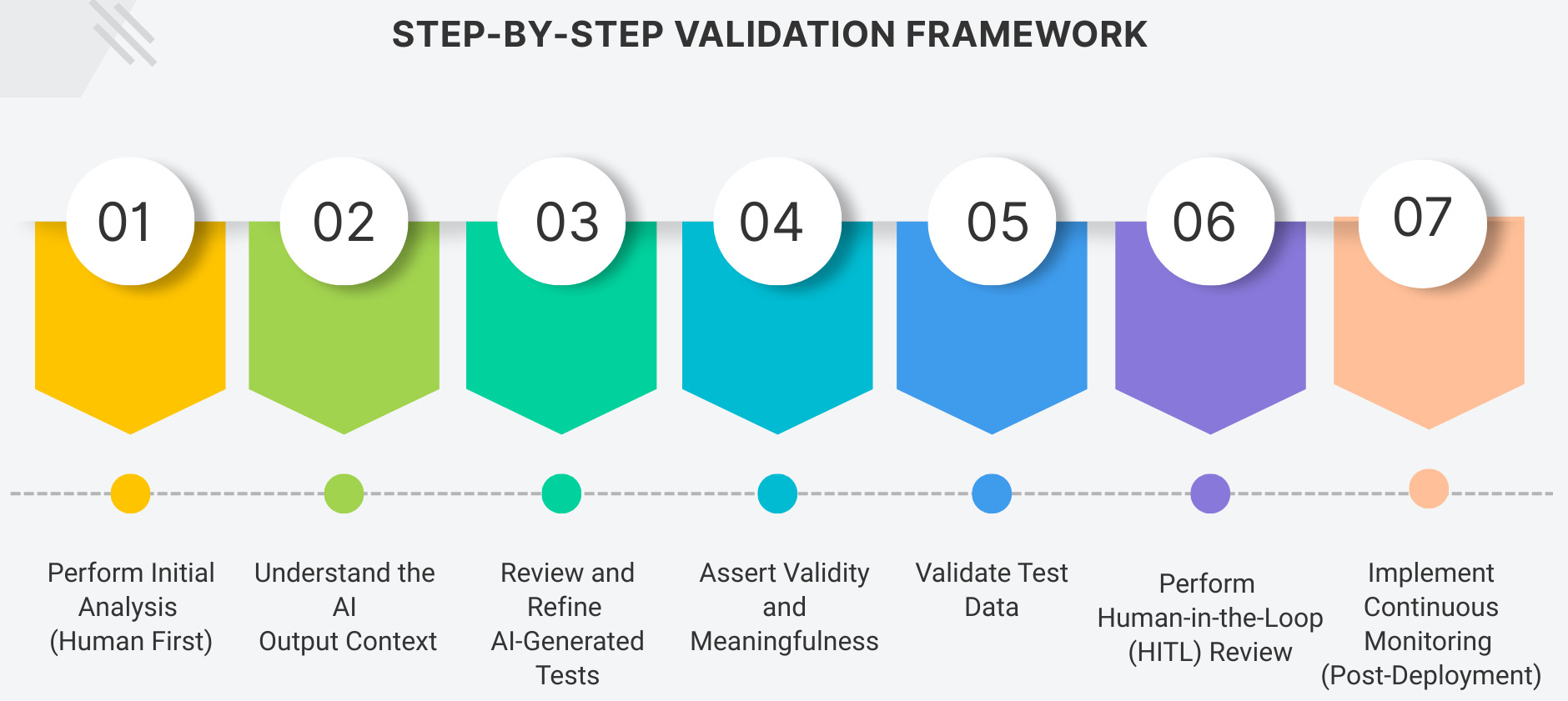
Step 1: Perform Initial Analysis (Human First)
As a first step, clearly define the testing objectives, scope, and risk profile of the applications. As AI does not understand business impact, user priorities, or technical debt, it is necessary to analyze business requirements, map system architecture, and identify critical user flows before involving AI. You can also define data validation rules, such as password complexity or input constraints, at this stage.
Step 2: Understand the AI Output Context
Identify what the AI model was given as input (doc, code snippet, prompts), and map the AI output to existing test structures. Also, determine the test type and scope.
Read: AI Context Explained: Why Context Matters in Artificial Intelligence.
Step 3: Review and Refine AI-Generated Tests
Review all AI-generated test scenarios to ensure they are relevant, accurate, and non-duplicative, and refine them as needed. Check for “test theatre”: tests that appear to test something but, in reality, are not (hallucinations). Ensure tests are independent and do not rely on shared state or specific sequence. Also, look for test duplication.
Step 4: Assert Validity and Meaningfulness
A test is not just a passing condition; it must assert the correct behavior. In this step, verify that the assertions in the AI-generated tests are specific and meaningful, rather than generic.
assert user.age > 0
assert user.validate_age() == True
- Change the assertion to its opposite (For example, from toBe(‘active’) to toBe(‘inactive’)) and run the test. If it still passes, the test is broken.
- Verify that tests catch actual bugs by deliberately breaking the code.
Step 5: Validate Test Data
This step validates the test data to ensure it is realistic and covers edge cases. AI often generates only “happy path” tests. It should be ensured that tests for boundary conditions (e.g., minimum/maximum values, empty strings, null values) are covered. It is also ensured that tests clean themselves up properly to prevent database buildup.
If tests reference external systems, confirm the mocks are accurate and validate the stubs for real behavior. Read: Mocks, Spies, and Stubs: How to Use?
Step 6: Perform Human-in-the-Loop (HITL) Review
Review the tests to spot unclear test names, missing assertions, and weird test data choices by pairing up with another QA engineer for reviews so that you have fresh eyes. Audit for biases, safety issues, or toxicity.
Read: How to Keep Human In The Loop (HITL) During Gen AI Testing?
Step 7: Implement Continuous Monitoring (Post-Deployment)
This is the last step to verify test execution, review test coverage, and implement continuous monitoring. As applications evolve, AI-generated tests can become outdated. Set a “shadow mode” for new tests, running them alongside existing, trusted tests. Regularly perform mutation testing to ensure the tests are effective.
When test execution is verified, observe flakiness, false positives, and fragile assertions.
How to Use AI to Validate AI-Generated Tests?
The steps outlined above are generic steps for validating AI-generated test cases.
Let us try to run an AI-generated test case using AI with the testRigor tool.
Here, we are going to validate whether the chatbot is providing correct data regarding Newton’s Third Law of Motion. In this case, we will simply instruct the tool to evaluate the response of the chatbot instead of hardcoding Newton’s law.
The testRigor script for this test case is:
enter "mention Newton's third law" into "Chat with AI...". type enter. check that page "contains Newton's third law" using ai.
Now let’s execute the script and see the output:
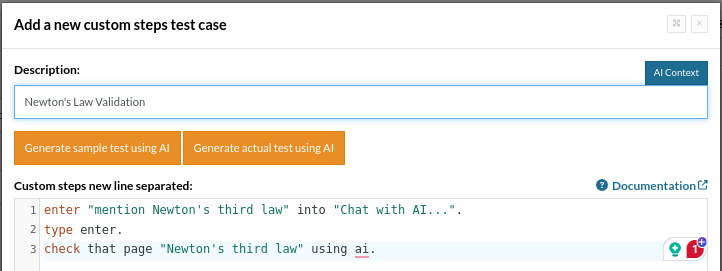
The statement "Newton's third law" is true because "Newton's third law is valid and universally accepted as a scientific principle, which states that 'for every action, there is an equal and opposite reaction.' The provided screenshot and page source confirm that the AI chatbot mentions Newton's Third Law, which aligns with the truth of the statement. There is no evidence in the provided materials to contradict the validity of Newton's third law."
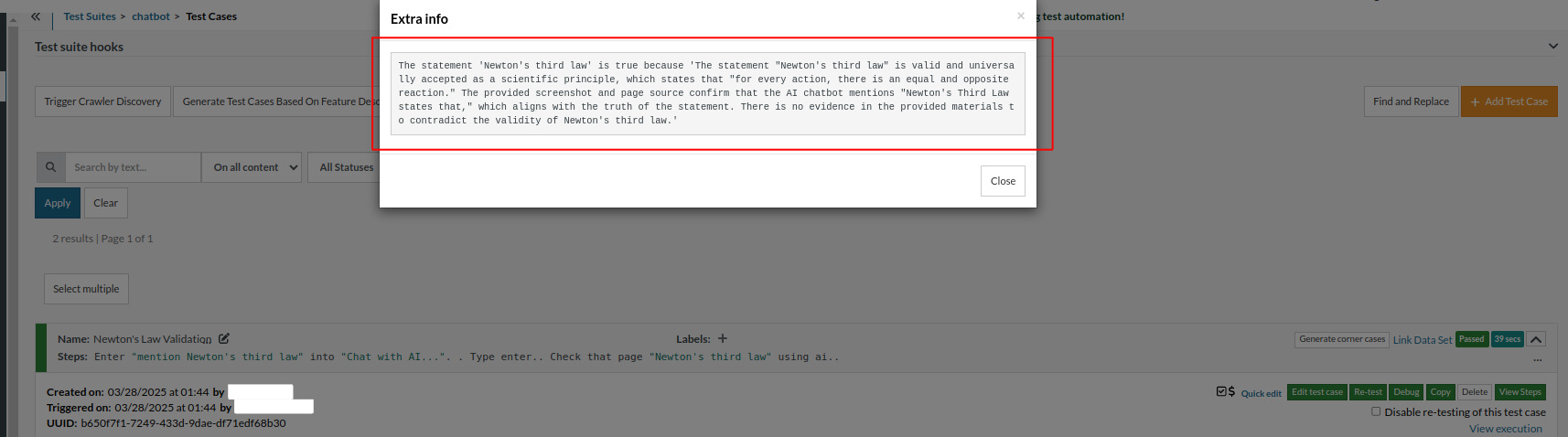
So you can see that testRigor makes testers’ lives easy. You don’t have to hardcode anything. Instead, just by giving a context (Newton’s Third Law, in this case), AI generated a test case for the chatbot. It is then validated by testRigor (in this example, the generated detailed info includes Newton’s Third Law). The assertion is made, and then we can see in the ‘extra info’ why testRigor passes or fails a particular test case (which means it explains why it did what it did).
Also read, How to use AI effectively in QA.
Techniques for Validation
AI can generate tests 9x faster and reduce maintenance by up to 90%. However, it also suffers from challenges of hallucination, producing redundant tests or missing complex business logic. Validating AI-generated tests is thus crucial.
Effective validation involves keeping human testers around, along with automated sanity checks to ensure the generated tests accurately reflect business requirements and provide reliable coverage.
Here are the techniques for validating AI-generated tests:
Key Techniques for Validation
- Human-in-the-Loop (HITL) Review: Human testers review AI-generated tests for logic, completeness, and accuracy. Human testers manually review tests, especially those written in Gherkin or plain English, before executing them.
- Intent-based Testing & Assertions: This technique focuses on evaluating whether the test output aligns with the intended purpose rather than just specific, brittle outputs.
- Visual & Functional Merging: AI-powered tools combine visual AI (snapshot comparisons) with functional, step-by-step checks (DOM elements) to ensure the UI looks right and functions correctly. testRigor is the best tool for this purpose.
- Adversarial Testing: A technique called “red teaming” intentionally tries to break AI-generated tests with malformed inputs to test their robustness.
- Cross-Reference Requirements: In this method, AI-generated tests are traced back to user stories (in Jira) to ensure all objectives are met.
- Mutation Testing: This approach evaluates test effectiveness by introducing small changes (mutations) and checking whether tests fail. Tools like
MutPy(Python library),Stryker(JavaScript), andPIT(Java) are used. Effective test suites catch bugs introduced by mutation. - AI Prompt Tracking: This technique tracks prompts, AI model versions, and the context used. This helps with reproducibility and iterative development.
Read more: Prompt Engineering in QA and Software Testing.
Best Practices for Validation
- Start with a Pilot Project: Rather than proceeding with the full-scale implementation, begin by applying AI to a well-documented, specific, small feature area to establish a baseline for quality and efficiency.
- Focus on Requirements Quality: AI is only as good as the context and data it is provided. So, ensure that inputs (user stories, requirements) are clear and up to date.
- Prioritize Quality over Quantity: Avoid the vanity of “high test count”. Focus instead on the quality of generated tests that aim to improve coverage, catch meaningful bugs, and reduce technical debt.
- Treat AI as a Partner, Not a Replacement: Remember, AI is a partner that generates high-volume standard scenarios and brainstorming edge cases. It cannot replace human testers dealing with complex logic and critical thinking.
- Establish Continuous Feedback Loops: Continuously feed test execution results back into the AI system to reevaluate and refine future test generations, improving accuracy over time.
- Implement Robust Testing for the AI itself: Validate tests for consistency and bias, especially for generative models, ensuring that the generated test cases are not just accurate but also fair and diverse.
Common Challenges in Validation
- Inaccurate Assumptions and False Confidence: AI models may generate tests for features that do not exist or generate scenarios that are opposite to actual product requirements (hallucinations). Testers may assume generated test cases have full coverage, which is false, and as a result, some critical bugs may be masked. testRigor offers many AI features of its own, and that is where the explainability of the AI (XAI) engine comes into the picture. Using XAI, testRigor can understand the context, and explains why it took an action which it did. Read more: What is Explainable AI (XAI)?
- Lack of Business Logic and Domain Nuance: AI models lack the context-specific knowledge related to complex business rules or regulatory constraints. AI models generally excel at generating “happy path” scenarios but struggle with edge cases, complex workflows, and error handling.
- High Maintenance and Fragility: AI-generated test cases are mostly brittle, and even small UI changes (as simple as renaming a button) can cause tests to fail. This leads to high maintenance overhead. AI-generated tests may be difficult to debug as AI may combine multiple libraries, omit documentation, or generate complex helper functions. When tests fail, identifying their root causes is difficult.
- Non-Deterministic Results (Flakiness): AI models usually produce different outputs for the same input (for example, chatbots that give different replies every time you ask the same question). This inconsistency in behavior makes it difficult for users to rely on them for consistent, repeatable test cases. Test cases may also demonstrate non-deterministic behavior, leading to false positives and negatives. All these inconsistencies make validation challenging. testRigor aims to address flakiness by changing how tests are authored from low-level scripting to intent-based assertions on behavior. It provides a radical separation between what the user does and how they do it, thus removing many of the structural causes of instability. It enables the creation of test suites that are stable enough for rapidly changing applications. Read how testRigor helps avoid flakiness and What are Flaky Tests in Software Testing? for examples showing testRigor implementation.
- Technical and Security Risks: Security flaws such as improper input validation or dependency vulnerabilities may be missing in AI-generated test cases. Performance issues like memory leaks may arise if code that passed unit tests fails under load.
- Data Quality and Privacy Issues: This is a very important and common challenge that almost all AI models face. If the training data used in the AI model is inaccurate, incomplete, biased, or outdated, generated test cases will be the same. If prompts that generate tests contain sensitive, proprietary information, data leakage may occur if proper privacy guardrails are not in place.
- Skills Gap and Tool Limitations: Validating AI-generated test cases required experts in both AI and traditional QA. These skilled experts are usually in short supply. Many organizations rely on generic tools such as ChatGPT or Gemini rather than customized AI testing solutions. This leads to inefficient testing.
Case Study: Test Case Generation from User Stories
Here is a case study validating various metrics regarding AI-generated tests. The general trend shows that while AI significantly accelerates test case creation, it requires human oversight to ensure quality. Validated results show that AI can improve coverage and reduce manual testing time by up to 97%, provided that prompt engineering and rigorous validation are part of the workflow.
- Validation Method: A controlled comparison was used to analyze correctness, coverage, duplication, and ambiguity.
- Key Finding: Prompt optimization led to an average improvement of 67.78% across key metrics.
- Limitations: Despite high performance, 27.22% of AI-generated test cases were ambiguous, reinforcing the need for human review.
Conclusion: AI serves as a powerful assistant for speed, but human oversight is essential to refine and validate test logic.
Future Trends in Validation
- AI-Assisted Test Validation: AI models suggest which tests are of value, meaningful, or redundant.
- Semantic Test Comparisons: Tests are compared semantically to analyze test intent vs actual assertions.
- Natural Language Specifications: Requirements are mapped to tests using AI.
- Test Correctness Scores: Each test is associated with a test correctness score, which is an automated confidence score.
Conclusion
AI tools can generate tests at the fastest rate, but without proper validation, these tests can provide false confidence or create long-term maintenance costs.
Effective validation can be achieved only by using automated analysis with human judgment to ensure tests generated are meaningful, accurate, maintainable, and aligned with business objectives.
By using the structured validation framework outlined in this blog and tools and techniques such as coverage and mutation testing, teams can elevate AI-generated tests into a trustworthy and valuable part of their quality strategy.
Frequently Asked Questions (FAQs)
- Why is it important to validate AI-generated tests?
AI-generated tests can accelerate test creation, but they may include incorrect assumptions, hallucinations, incomplete coverage, or brittle logic. Validation ensures the tests accurately reflect real user behavior, verify meaningful functionality, and remain reliable over time.
- Can AI-generated tests introduce flakiness?
Yes. AI-generated tests may rely on unstable selectors, timing assumptions, or incomplete synchronization. Stabilizing tests through resilient locators, proper waits, and deterministic data improves reliability.
- Should AI-generated tests replace manual QA validation?
No. AI-generated tests should augment QA efforts, not replace human oversight. QA engineers play a critical role in reviewing, refining, and strategically selecting which tests provide real business value.- What metrics can help evaluate AI-generated test quality?
Useful metrics include:- Pass/fail stability rate
- Flakiness percentage
- Requirement coverage
- Defect detection rate
- Test maintenance effort
Tracking these metrics helps determine whether the AI-generated tests are delivering value.- How often should AI-generated tests be reviewed?
AI-generated tests should be reviewed in the following situations:- Before merging into the main test suite
- After major feature updates
- When tests start failing unexpectedly
- As part of regular test maintenance cycles
Ongoing validation ensures long-term stability.You're 15 Minutes Away From Automated Test Maintenance and Fewer Bugs in ProductionSimply fill out your information and create your first test suite in seconds, with AI to help you do it easily and quickly.Achieve More Than 90% Test Automation Step by Step Walkthroughs and Help 14 Day Free Trial, Cancel Anytime  “We spent so much time on maintenance when using Selenium, and we spend nearly zero time with maintenance using testRigor.”Keith Powe VP Of Engineering - IDT
“We spent so much time on maintenance when using Selenium, and we spend nearly zero time with maintenance using testRigor.”Keith Powe VP Of Engineering - IDT - Should AI-generated tests replace manual QA validation?








